当前位置:网站首页>Mnasnet learning notes
Mnasnet learning notes
2022-07-01 02:34:00 【Fried dough twist】
MnasNet Learning notes
Original address :MnasNet: Platform-Aware Neural Architecture Search for Mobile
brief introduction
Lightweight network optimization


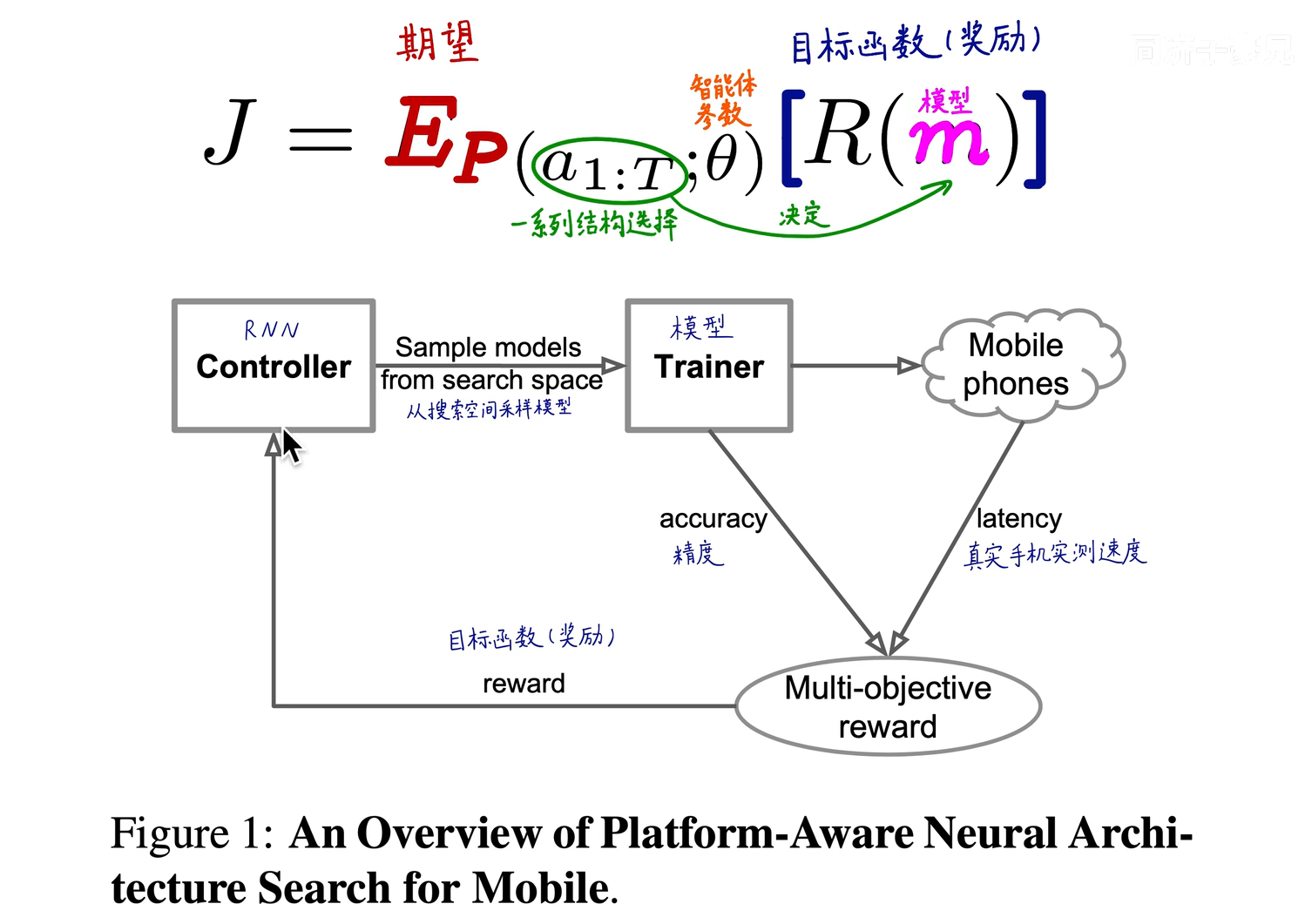
Pass hard index T Control the penalty and incentive of the whole objective function
$\alpha $ = 0 ,$\beta $ = -1 when , The punishment is even worse , Therefore, most models focus on hard indicators
$\alpha $ = -0.07 ,$\beta $ = -0.07 when , The overall distribution is more even , More


Ensure the structural diversity of different layers

Overall process
The resulting structure

Text

Abstract
Design convolutional neural networks for mobile devices (CNN) Challenging , Because mobile models need to be small and fast , But it's still accurate . Although in the design and improvement of mobile CNN Great efforts have been made in all aspects of , But when so many architectural possibilities need to be considered , It is difficult to balance these tradeoffs manually . In this paper , We propose an automatic mobile neural architecture search (MNAS) Method , This method explicitly incorporates the model delay into the main objective , So that the search can identify a model that achieves a good trade-off between accuracy and latency . Different from previous work , Our method passes through another agent that is usually inaccurate ( for example FLOPS) To consider delays , Our method directly measures real-world reasoning delay by executing models on mobile phones . To further strike the right balance between flexibility and the size of search space , We propose a new factorization hierarchical search space , To encourage layer diversity across the network . Experimental results show that , In multiple visual tasks , Our approach is always superior to the most advanced mobile CNN Model . stay ImageNet In the classification task , our MnasNet The delay on pixel phones is 1.8 millisecond , achieve 75.2% Of top-1 precision ⇥ Than MobileNetV2[29] faster , The accuracy is higher than 0.5% and 2.3%⇥ Than NASNet faster , High accuracy 1.2%. our MnasNet stay COCO Target detection is also better than MobileNet Better map quality . Code is located https://github.com/tensorflow/tpu/ Trees / Lord / Model / official /mnasnet.
1. Introduction
Convolutional neural networks (CNN) In image classification 、 Significant progress has been made in target detection and many other applications . With modern times CNN The model gets deeper and deeper 、 More and more big [31、13、36、26], They are also getting slower and slower , More calculations are needed . The increasing demand for computing makes it possible to deploy the most advanced CNN Models become difficult, such as mobile or embedded devices .
Considering the limited computing resources available on mobile devices , Many recent studies have focused on reducing network depth and using lower cost operations ( Like deep convolution [11] Sum group convolution [33]) To design and improve mobile CNN Model . However , Designing a resource constrained mobile model is a challenge : You must be careful Balance accuracy and resource efficiency , Thus creating a huge design space .
In this paper , We propose a method for designing mobile CNN Automatic neural structure search method of the model . chart 1 Shows an overview of our approach , The main difference from the previous methods is delayed perception of multi-objective reward and novel search space . Our approach is based on two main ideas . First , We describe the design problem as a multi-objective optimization problem , The problem considers CNN Model accuracy and reasoning delay . With previous work [36、26、21] Triggers are used in to approximate infer different delays , We directly measure real-world latency by executing models on real mobile devices . Our ideas are inspired by the following observations :FLOPS Usually an inaccurate proxy : for example ,MobileNet[11] and NASNet[36] There is something similar FLOPS(575M vs.564M), But their delays are significantly different (113ms vs.183ms, See table for details 1). secondly , We observed that , Previous automation methods mainly searched for several types of units , The same cells are then stacked repeatedly over the network . This simplifies the search process , But it also excludes layer diversity, which is important for computational efficiency . To solve this problem , We propose a new factorization hierarchical search space , It allows layers to be architecturally different , But there is still a proper balance between flexibility and the size of search space .

We apply our proposed method to ImageNet classification [28] and COCO object detection [18]. chart 2 Sum up our MnasNet Comparison between the model and other most advanced mobile models . And MobileNetV2 comparison , Our model will ImageNet The accuracy of 3.0%, The delay on Google pixel phones is similar . On the other hand , If we limit the target accuracy , So our MnasNet Model ratio MobileNetV2 fast 1.8 times , Than S NASNet fast 2.3 times , Higher accuracy . With the widely used ResNet-50[9] comparison , our MnasNet The accuracy of the model is slightly higher (76.7%), Less parameters 4.8 times , Less multiplication and addition 10 times . By inserting our model as a feature extractor into SSD Object detection framework , Our model improves COCO Reasoning delay and mapping quality on datasets , be better than MobileNetsV1 and MobileNetV2, And realized with SSD300 Fairly good mapping quality (23.0 vs 23.2), just 42× Less multiplication and addition .

in summary , Our main contributions are as follows :
1、 We introduce a Multi-objective neural architecture search method , This method can optimize the accuracy and real-world delay on mobile devices .
2、 We came up with a new one Factorization hierarchical search space , To achieve layer diversity , But it can still strike a proper balance between flexibility and the size of search space .
3、 Under typical mobile delay constraints , We are ImageNet Classification and COCO Object detection shows New state-of-the-art accuracy .
2. Related Work
In the last few years , Improve CNN The resource efficiency of models has always been an active research topic . Some common methods include 1) Baseline CNN The weight of the model and / Or activate quantization to a lower bit representation [8,16], or 2) Trim less important filters according to triggers [6,10], Or according to the platform perception index , Such as [32] Delay introduced in . However , These methods are associated with the baseline model , Not focused on learning CNN New combinations of operations .
Another common approach is to manually create a more efficient mobile architecture :SqueezeNet[15] By using low cost 1x1 Convolution and reduction of filter size to reduce the number of parameters and calculations ;MobileNet[11] Deep separable convolution is widely used to minimize computational density ;ShuffleNet[33,24] Using low-cost group convolution and channel shuffling ;Concedenet【14】 Learn cross layer connection group convolution ; lately ,MobileNetV2【29】 By using resource efficient reverse residuals and linear bottlenecks , The most advanced results are obtained in the mobile scale model . Unfortunately , Considering the potential huge design space , These handmade models usually require a lot of manpower .
lately , People are more and more interested in using neural structure search to automate the model design process . These methods are mainly based on Reinforcement Learning 【35、36、1、19、25】、 Evolutionary search 【26】、 Differentiable search 【21】 Or other learning algorithms 【19、17、23】. Although these methods can generate a moving size model by repeatedly stacking several search units , But they do not incorporate mobile platform constraints into the search process or search space . Closely related to our work is MONAS【12】、DPP Net【3】、RNAS【34】 and Pareto NASH【4】, They are trying to search CNN Optimize multiple objectives , Such as model size and accuracy , But their search process is like CIFAR And other small tasks . by comparison , This paper aims at the mobile delay limitation in the real world , Focus on bigger tasks , Such as ImageNet Classification and COCO Object detection .
3. Problem Formulation
We describe the design problem as a multi-objective search , The purpose is to find a method with high accuracy and low reasoning delay CNN Model . And the previous architecture (architecture) Search method ( Usually for indirect indicators ( Like triggers ) To optimize ) Different , By running on real mobile devices CNN Model , Then we incorporate the real-world reasoning delay into our goal , To consider the delay in direct practical reasoning . Doing so can directly measure the goals that can be achieved in practice : Our early experiments showed that , Due to mobile hardware / The diversity of software features , Delays approaching the real world are challenging .
Given a model m, Give Way ACC(m) Indicates the accuracy of the target task ,LAT(m) Represents the reasoning delay on the target mobile platform ,T Indicates target delay . A common method is to put T Consider as a hard constraint , Under this constraint, the accuracy is improved to the greatest extent :

However , This approach can only maximize a single measure , It cannot provide multiple Pareto optimal solutions . Unofficially , If a model has the highest accuracy without increasing the delay , Or it has the lowest delay without reducing the accuracy , Then this model is called Pareto optimal model . Considering the computational cost of performing schema search , We are more interested in finding in a single schema search Multiple Pareto-optimal( The budget is the lowest under the same performance , The best performance under the same budget ) Optimal solution .
Although the literature [2] There are many ways to , But we use a custom weighted product method 1 To approximate the Pareto optimal solution , The optimization objective is defined as :

among ,w It's the weight factor , Defined as :

among α and β Is to apply a specific constant . choice α and β The empirical rule of thumb is to ensure that under different precision delay tradeoffs , Pareto optimal solutions have similar returns . for example , We have observed from experience that , Doubling the delay usually brings 5% The relative accuracy of . Two models are given :(1)M1 With delay l And precision a;(2) M2 The incubation period is 2l, The accuracy is higher than 5%:a·(1+5%), They should have similar rewards : R e w a r d ( M 2 ) = a ⋅ ( 1 + 5 % ) ⋅ ( 2 l / T ) β ≈ Reward ( M 1 ) = a ⋅ ( l / T ) β Reward(M2)=a \cdot ( 1+5 \%) \cdot(2 l / T)^{\beta} \approx \operatorname{Reward}(M 1)=a \cdot(l / T)^{\beta} Reward(M2)=a⋅(1+5%)⋅(2l/T)β≈Reward(M1)=a⋅(l/T)β. Solving this problem will lead to β≈ −0.07. therefore , We use α=β=−0.07 In our experiment , Unless explicitly stated .
chart 3 Shows two typical values (α,β) The objective function of . In the diagram above , belt (α=0,β=−1) , If the measured delay time is less than the target delay time T, We just need to use accuracy as the target value ; otherwise , We will severely punish the target value , To prevent the model from violating the delay constraint . The figure below (α=β=−0.07) Delay the target T Consider as a soft constraint , And smoothly adjust the target value according to the measured delay .


4. Mobile Neural Architecture Search
In this section , We will first discuss our new decomposition level search space , Then we summarize our search algorithm based on reinforcement learning .
A little



5. Experimental Setup
In image ImageNet or COCO Search directly in such a large task CNN Models are expensive , Because it takes several days for each model to converge . Although previous methods were mainly for smaller tasks ( Such as CIFAR10) Perform schema search [36,26], But what we found was that , When considering the model delay , These smaller agent tasks don't work , Because when applied to larger problems , You usually need to zoom in on the model . In this paper , We are directly in the ImageNet Perform a schema search on the training set , But there are few training steps (5 Stages ). Usually , We randomly choose from the training set 50K Images as fixed validation sets . In order to ensure that the accuracy improvement comes from our search space , We used and NASNet same RNN controller , Although it is not efficient stay 64 platform TPUv2 On the device , Each schema search requires 4.5 Time of day . During the training , We passed the Pixel 1 The one-way distance of the mobile phone is large CPU Each sampling model is run on the kernel to measure its real-world latency . Overall speaking , Our controller collected approximately during the architecture search 8K A model , But only 15 The best model of personality can be transferred to the complete ImageNet, Only 1 Models are transferred to COCO.
For complete ImageNet Training , We use attenuation to 0.9、 Momentum is 0.9 Of RMSProp Optimizer . Add the batch norm after each convolution layer , Momentum is 0.99, The weight attenuation is 1e-5. Exit rate 0.2 Apply to the last layer . Subsequent literature [7] after , front 5 The learning rate of the three periods ranges from 0 Add to 0.256, Then each 2.4 A period of decline 0.97. We use batch size 4K And initial pretreatment , The image size is 224×224. about COCO train , We insert the learned model into SSD detector [22], And use the [29] Same settings , Include input size 320×320.
6. Results
In this section , We will study our model in ImageNet Classification and COCO Performance in object detection , And compare it with other most advanced mobile models .





7. Ablation Study and Discussion
In this section , We study the effects of delay constraints and search space , And discussed MnasNet The importance of architectural details and layer diversity .
7.1. Soft vs. Hard Latency Constraint
Our multi-objective search method allows us to search through α and β Set to the reward equation 2 To handle hard delay and soft delay constraints . chart 6 It shows typical α and β Multi-objective search results . When α=0 when ,β=−1、 Delays are considered as hard constraints , Therefore, controllers tend to pay more attention to faster models , To avoid delay penalties . On the other hand , By setting α=β=−0.07 when , The controller regards the target delay as a soft constraint , And try to search the model within a larger delay range . It revolves around 75ms The target delay value of samples more models , But it is also explored that the delay is less than 40ms Or greater than 110ms Model of . This allows us to search from Pareto Select multiple models in the curve , As shown in the table 1 Shown .
7.2. Disentangling Search Space and Reward
To clarify the impact of our two key contributions : Multi goal rewards and new search space , chart 5 Their performances are compared . from NASNet[36] Start , We first use the same unit based search space [36], And we use our multi object reward to simply add delay constraints . It turns out that , By weighing accuracy against delay , It can generate faster models . then , We apply our multi-objective reward and our new factorization search space , Achieve higher accuracy and lower latency , It shows the effectiveness of our search space .

7.3. MnasNet Architecture and Layer Diversity
chart 7(a) It illustrates what we found through automated methods MnasNet-A1 Model . As expected , It consists of various layer architectures in the whole network . An interesting observation is , our MnasNet Use at the same time 3x3 and 5x5 Convolution , This is the same as the previous mobile model, which only uses 3x3 Convolution is different .
To study the effects of layer diversity , surface 6 take MnasNet Instead of just repeating a single type layer ( Fixed kernel size and expansion ratio ) The variants of . Compared with these variants , our MnasNet The model has better accuracy and delay tradeoffs , It highlights the layer diversity in resource constrained CNN Importance in the model .


8. Conclusion
In this paper, we propose an efficient mobile design method based on reinforcement learning CNN Automatic neural structure search method of the model . Our main idea is to incorporate the real-world delay information perceived by the platform into the search process , And a new decomposition level search space is used to search the mobile model , Make the best trade-off between accuracy and delay . We prove , Under the typical delay constraint of mobile reasoning , Our method can automatically find a better mobile model than the existing methods , And in ImageNet Classification and COCO The latest achievements have been made in object detection . The resulting MnasNet The architecture also provides interesting findings about the importance of layer diversity , This will guide us in designing and improving future mobile CNN Model .
边栏推荐
- Clickhouse eliminates the gap caused by group by
- Objects and object variables
- 开源基础软件公司,寻找一起创造未来的你(API7.ai)
- Applet custom top navigation bar, uni app wechat applet custom top navigation bar
- [JS] [Nuggets] get people who are not followers
- Qu'est - ce que le PMP?
- 【做题打卡】集成每日5题分享(第一期)
- Open source basic software companies, looking for you to create the future together (api7.ai)
- [graduation season · advanced technology Er] - summary from graduation to work
- 我的PMP学习考试心得
猜你喜欢
MnasNet学习笔记

记一次服务部署失败问题排查

UE4渲染管线学习笔记

PMP是什麼?

Machine learning 9-universal approximator radial basis function neural network, examining PDA and SVM from a new perspective

如何在智汀中實現智能鎖與燈、智能窗簾電機場景聯動?

AI edge computing platform - beaglebone AI 64 introduction

在unity中使用jieba分词的方法

零基础自学SQL课程 | 窗口函数

Focusing on green and low carbon, data center cooling has entered a new era of "intelligent cooling"
随机推荐
SWT/ANR问题--StorageManagerService卡住
如何在智汀中实现智能锁与灯、智能窗帘电机场景联动?
手机edge浏览器无法打开三方应用
鼠标悬停效果六
kubernetes资源对象介绍及常用命令(二)
Viewing JVM parameters
Open source basic software companies, looking for you to create the future together (api7.ai)
旷世轻量化网络ShuffulNetV2学习笔记
Xception学习笔记
JS anti shake and throttling
How do the top ten securities firms open accounts? Also, is it safe to open an account online?
UE4渲染管线学习笔记
我的PMP学习考试心得
@The difference between configurationproperties and @value
SWT / anr problem - storagemanagerservice stuck
522. Longest special sequence II
How to realize the scene linkage of intelligent lock, lamp and intelligent curtain motor in zhiting?
My PMP learning test experience
SWT/ANR问题--Binder Stuck
先写API文档还是先写代码?