当前位置:网站首页>batch size设置技巧
batch size设置技巧
2022-07-06 23:28:00 【汀、】
1、什么是BatchSize
Batch一般被翻译为批量,设置batch_size的目的让模型在训练过程中每次选择批量的数据来进行处理。Batch Size的直观理解就是一次训练所选取的样本数。
Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点。
2、 为什么需要 Batch_Size?
在没有使用Batch Size之前,这意味着网络在训练时,是一次把所有的数据(整个数据库)输入网络中,然后计算它们的梯度进行反向传播,由于在计算梯度时使用了整个数据库,所以计算得到的梯度方向更为准确。但在这情况下,计算得到不同梯度值差别巨大,难以使用一个全局的学习率,所以这时一般使用Rprop这种基于梯度符号的训练算法,单独进行梯度更新。
在小样本数的数据库中,不使用Batch Size是可行的,而且效果也很好。但是一旦是大型的数据库,一次性把所有数据输进网络,肯定会引起内存的爆炸。所以就提出Batch Size的概念。
3、 如何设置Batch_Size 的值?
设置BatchSize要注意一下几点:
1)batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。
2)随着batchsize增大,处理相同的数据量的速度越快。
3)随着batchsize增大,达到相同精度所需要的epoch数量越来越多。
4)由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5)由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
6)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。
7)具体的batch size的选取和训练集的样本数目相关。
8)GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优
我在设置BatchSize的时候,首先选择大点的BatchSize把GPU占满,观察Loss收敛的情况,如果不收敛,或者收敛效果不好则降低BatchSize,一般常用16,32,64等。
4、在合理范围内,增大Batch_Size有何好处?
内存利用率提高了,大矩阵乘法的并行化效率提高。
跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
5、 盲目增大 Batch_Size 有何坏处?
内存利用率提高了,但是内存容量可能撑不住了。
跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
6、调节 Batch_Size 对训练效果影响到底如何?
Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
随着 Batch_Size 增大,处理相同数据量的速度越快。
随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优
batchsize过小:每次计算的梯度不稳定,引起训练的震荡比较大,很难收敛。
batchsize过大:
(1)提高了内存利用率,大矩阵乘法并行计算效率提高。
(2)计算的梯度方向比较准,引起的训练的震荡比较小。
(3)跑完一次epoch所需要的迭代次数变小,相同数据量的数据处理速度加快。
缺点:容易内容溢出,想要达到相同精度,epoch会越来越大,容易陷入局部最优,泛化性能差。
batchsize设置:通常10到100,一般设置为2的n次方。
原因:计算机的gpu和cpu的memory都是2进制方式存储的,设置2的n次方可以加快计算速度。
深度学习中经常看到epoch、 iteration和batchsize这三个的区别:
(1)batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次;
举个例子,训练集有1000个样本,batchsize=10,那么训练完整个样本集需要:
100次iteration,1次epoch。
1.当数据量足够大的时候可以适当的减小batch_size,由于数据量太大,内存不够。但盲目减少会导致无法收敛,batch_size=1时为在线学习,也是标准的SGD,这样学习,如果数据量不大,noise数据存在时,模型容易被noise带偏,如果数据量足够大,noise的影响会被“冲淡”,对模型几乎不影响。
2.batch的选择,首先决定的是下降方向,如果数据集比较小,则完全可以采用全数据集的形式。这样做的好处有两点,
1)全数据集的方向能够更好的代表样本总体,确定其极值所在。
2)由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。
边栏推荐
- 数字化创新驱动指南
- sublime使用技巧
- SQL injection HTTP header injection
- Knapsack problem unrelated to profit (depth first search)
- AOSP ~binder communication principle (I) - Overview
- Linkedblockingqueue source code analysis - initialization
- Weebly mobile website editor mobile browsing New Era
- 磁盘监控相关命令
- [question] Compilation Principle
- Array initialization of local variables
猜你喜欢
Is it necessary to renew the PMP certificate?
 [email protected] Mapping relatio"/>
[email protected] Mapping relatio"/>Why JSON is used for calls between interfaces, how fastjson is assigned, fastjson 1.2 [email protected] Mapping relatio
利用OPNET进行网络仿真时网络层协议(以QoS为例)的使用、配置及注意点
Harmonyos fourth training
K6EL-100漏电继电器
HarmonyOS第四次培训
SQL injection HTTP header injection
Sublime tips
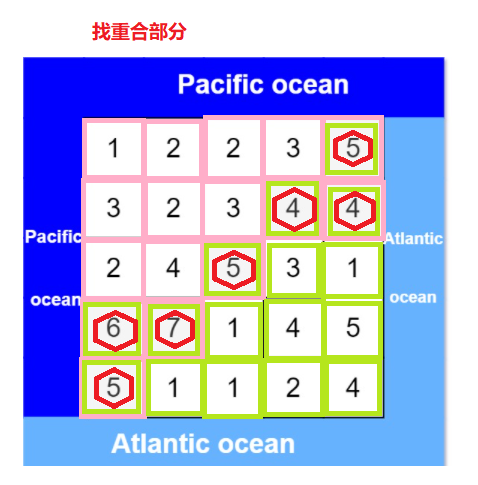
Leetcode (417) -- Pacific Atlantic current problem
Error: No named parameter with the name ‘foregroundColor‘
随机推荐
Leetcode longest public prefix
How can professional people find background music materials when doing we media video clips?
JHOK-ZBL1漏电继电器
NPDP产品经理认证,到底是何方神圣?
利用OPNET进行网络指定源组播(SSM)仿真的设计、配置及注意点
实现网页内容可编辑
Leetcode(417)——太平洋大西洋水流问题
QSlider of QT control style series (I)
np.random.shuffle与np.swapaxis或transpose一起时要慎用
2. Overview of securities investment funds
【PHP SPL笔记】
Leetcode (417) -- Pacific Atlantic current problem
利用OPNET进行网络单播(一服务器多客户端)仿真的设计、配置及注意点
pmp真的有用吗?
Y58. Chapter III kubernetes from entry to proficiency - continuous integration and deployment (Sany)
QT simple layout box model with spring
U++ game learning notes
c语言神经网络基本代码大全及其含义
模拟线程通信
AttributeError: module ‘torch._ C‘ has no attribute ‘_ cuda_ setDevice‘