当前位置:网站首页>语音合成模型小抄(1)
语音合成模型小抄(1)
2022-08-02 22:43:00 【Andy Dennis】
前言
语音也是一个日渐热门的行业啊。给定一段文本, 我们想让它被阅读出来.就需要使用到语音合成技术,也就是Text-to-Speech, 简称TTS。这里记录一下我看到的一些有意思的模型。
one-stage语音合成一般称为端到端 end-to-end
Two-stage语音合成步骤的, 通常stage1:
文本 -(FFT)-> 语谱图 -(滤波)-> 梅尔谱/线性谱
stage 2: 将梅尔谱/线性谱 生成 波形(音频)
论文
VITS
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
ICML 2021
论文: https://arxiv.org/abs/2106.06103
代码: https://github.com/jaywalnut310/vits
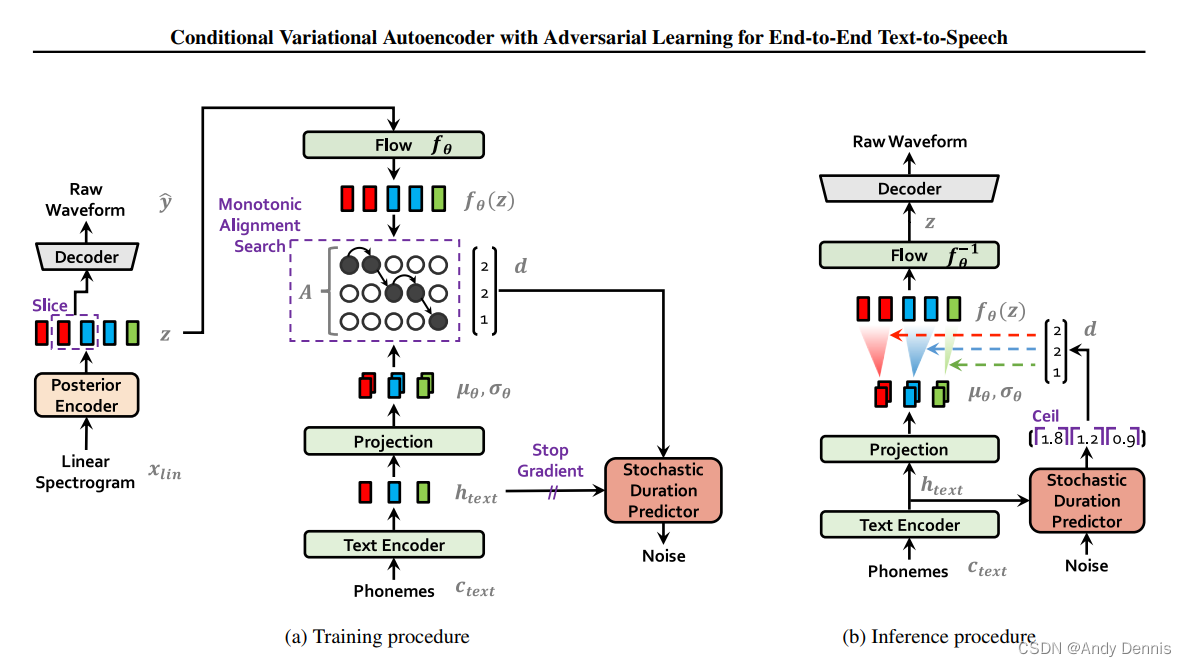
condition VAE + flow + GAN
flow可以看看v-flow和flow++这两篇文章。
知乎上看到两个论文笔记:
详细点的 细读经典:VITS,用于语音合成带有对抗学习的条件变分自编码器
简短的【论文笔记】VITS_OlaWod
边栏推荐
- 【UE5 骨骼动画】全形体IK导致Two Bone IK只能斜着移动,不能平移
- 软件测试到底自学还是报班?
- 微信小程序(一)
- CAS:474922-22-0,DSPE-PEG-MAL,磷脂-聚乙二醇-马来酰亚胺科研试剂供应
- Towards a General Purpose CNN for Long Range Dependencies in ND
- 你离「TDengine 开发者大会」只差一条 SQL 语句!
- No-code development platform form styling steps introductory course
- Jmeter二次开发实现rsa加密
- openssl源码下载
- Token、Redis实现单点登录
猜你喜欢




随机推荐
Broadcast platform, the use of the node generated captcha image, and validate
airflow db init 报错
markdown语法
微信小程序(一)
redis的学习笔记
Technology Sharing | How to do assertion verification for xml format in interface automation testing?
【Unity】Unity开发进阶(七)双刃剑:扩展方法
【C语言】带头双向循环链表(list)详解(定义、增、删、查、改)
创建型模式 - 抽象工厂模式AbstractFactory
mysql 错误:The driver has not received any packets from the server.
VS保存后Unity不刷新
分库分表索引设计:二级索引、全局索引的最佳设计实践
The only way to go from a monthly salary of 10k to 30k: automated testing
IDO预售代币合约系统开发技术说明及源码分析
Week 7 CNN Architectures - LeNet-5、AlexNet、VGGNet、GoogLeNet、ResNet
2022暑假牛客多校1 (A/G/D/I)
I have been in the software testing industry for nearly 20 years, let me talk to you about today's software testing
CAS:1445723-73-8,DSPE-PEG-NHS,磷脂-聚乙二醇-活性酯两亲性脂质PEG共轭物
智能电视竞争白热化,利用小程序共建生态突围
程序员如何优雅地解决线上问题?