当前位置:网站首页>Pointnet / pointnet++ point cloud data set processing and training
Pointnet / pointnet++ point cloud data set processing and training
2022-07-04 19:49:00 【Master Ma】
One 、 Representation of 3D data
The expression forms of three-dimensional data are generally divided into four :
① Point cloud : from N individual D Point composition of dimension , When this D = 3 It usually means ( x , y , z ) Coordinates of , Of course, it can also include some normal vectors 、 Strength and other characteristics . This is the main data type today .

② Mesh: It consists of triangular patches and square patches .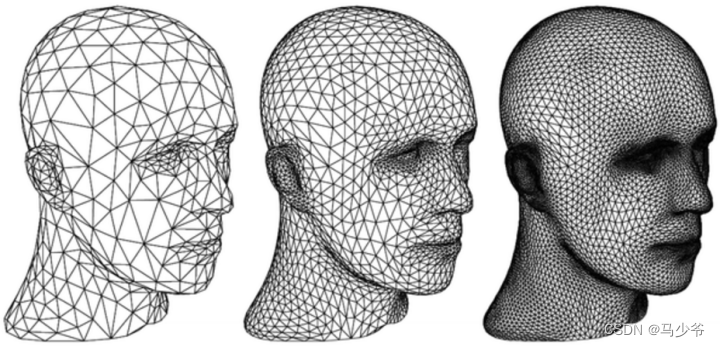
③ Voxel : Use the three-dimensional grid to use 0 and 1 characterization .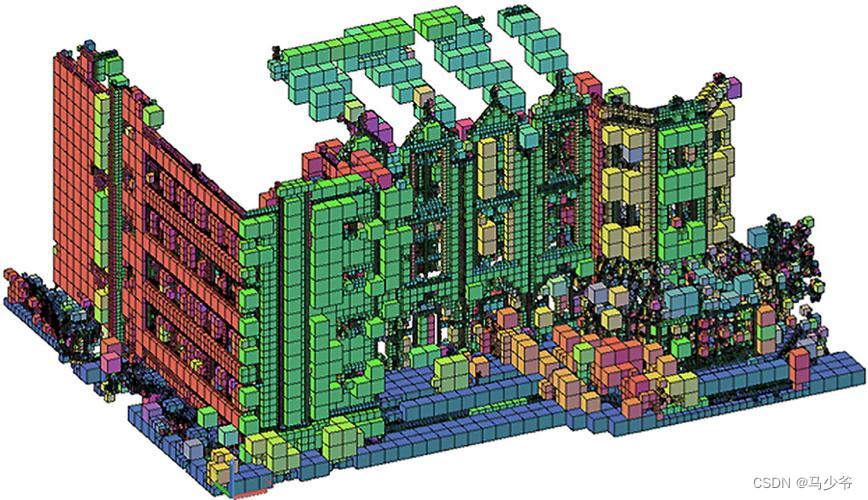
④ Multi angle RGB Image or RGB-D Images 
And because the point cloud is closer to the original representation of the device ( That is, radar scans objects to directly generate point clouds ) At the same time, its expression is simpler , An object uses only one N × D The matrix representation of , Therefore, point cloud has become the most important of many 3D data representation methods . Mapping 、 Architecture 、 Electric power 、 Industry and even the most popular fields such as automatic driving are widely used .
Two 、 Point cloud segmentation data set processing
Our point cloud data may be inconsistent with the data required by the model , So you need to write your own script to standardize the data . The standard point cloud data processing format is as follows :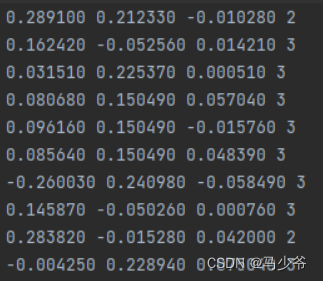
It only contains point cloud (x,y,z) Coordinates and labels corresponding to each point . And maybe we start from CloudCompare There are four columns of data and one column of point cloud intensity information :
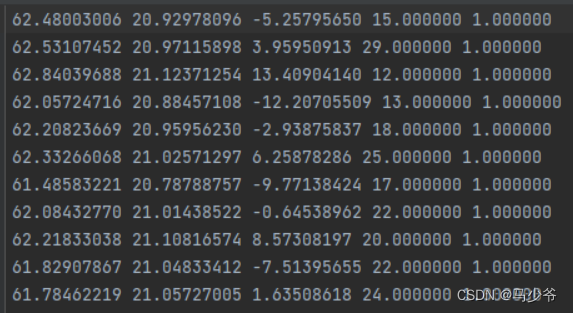
So write the following script to remove the redundant fourth column data ( The specific path of the file is set by yourself ):
# -*- coding:utf-8 -*-
import os
filePath = 'D:\\ Point cloud data processing team \\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390'
for i,j,k in os.walk(filePath):
for name in k:
print(name)
f = open(filePath+name) # open txt file
line = f.readline() # Read the file as a line
list1 = []
while line:
a = line.split()
b = a[0:3]
c = float(a[-1])
print(c)
if(float(a[-1])==36.0):
c=2
if(float(a[-1])==37.0):
c=3
b.append(c)
list1.append(b) # Add it to the list
line = f.readline()
f.close()
print(list1)
with open(filePath+name, 'w+') as file:
for i in list1:
file.write(str(i[0]))
file.write(' '+str(i[1]))
file.write(' ' + str(i[2]))
file.write(' ' + str(i[3]))
if(i!=list[-1]):
file.write('\n')
file.close()
# path_out = 'test.txt' # new txt file
# with open(path_out, 'w+') as f_out:
# for i in list1:
# fir = '9443_' + i[0] # Prefix the first column '9443_'
# sec = 9443 + int(i[1]) # Add... To the values in the second column 9443
# # print(fir)
# # print(str(sec))
# f_out.write(fir + ' ' + str(sec) + '\n') # Write the first two columns into the new txt file
Then we need to divide the training set 、 Test set 、 Verification set of json Document processing , Because we use our own data set , every last txt The file name of must be different from that in the previous official data set , So you need to write a script to control the training set 、 Test set 、 Verify the three... Read in by the set json File modification . The specific code is as follows ( The path name also needs to be modified to its own path name ):
import os
filePath = 'D:\\ Point cloud data processing team \\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390'
##### On the last line, there will be a , Report errors !!!!!!!!!
###### Manually delete or improve programs
#####
file = '1.txt'
with open(file,'a') as f:
f.write("[")
for i,j,k in os.walk(filePath):
for name in k:
base_name=os.path.splitext(name)[0] # Remove the suffix .txt
f.write(" \"")
f.write(os.path.join("shape_data/03797390/",base_name))
f.write("\"")
f.write(",")
f.write("]")
f.close()
Finally, when the actual program is running, it is found that it will contain 0 Too much data leads to inaccurate model classification , as follows :
According to the actual physical meaning of the specific project ( All the people here 0 That is, the position not detected by the laser ,x,y,z The coordinates are marked 0), So writing scripts is right for all 0 Remove the part of :
# -*- coding:utf-8 -*-
import os
filePath = 'D:\\ Point cloud data processing team \\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390'
for i,j,k in os.walk(filePath):
for name in k:
list1 = []
for line in open(filePath+name):
a = line.split()
#print(a)
b = a[0:6]
#print(b)
a1 =float(a[0])
a2 =float(a[1])
a3 =float(a[2])
#print(a1)
if(a1==0 and a2==0 and a3==0):
continue
list1.append(b[0:6])
with open(filePath+name, 'w+') as file:
for i in list1:
file.write(str(i[0]))
file.write(' '+str(i[1]))
file.write(' ' + str(i[2]))
file.write(' ' + str(i[3]))
file.write(' ' + str(i[4]))
if(i!=list[-1]):
file.write('\n')
file.close()
3、 ... and 、 model training
We open model Folder , Choose to pointnet2_part_seg_msg In the name of python file , Double click in :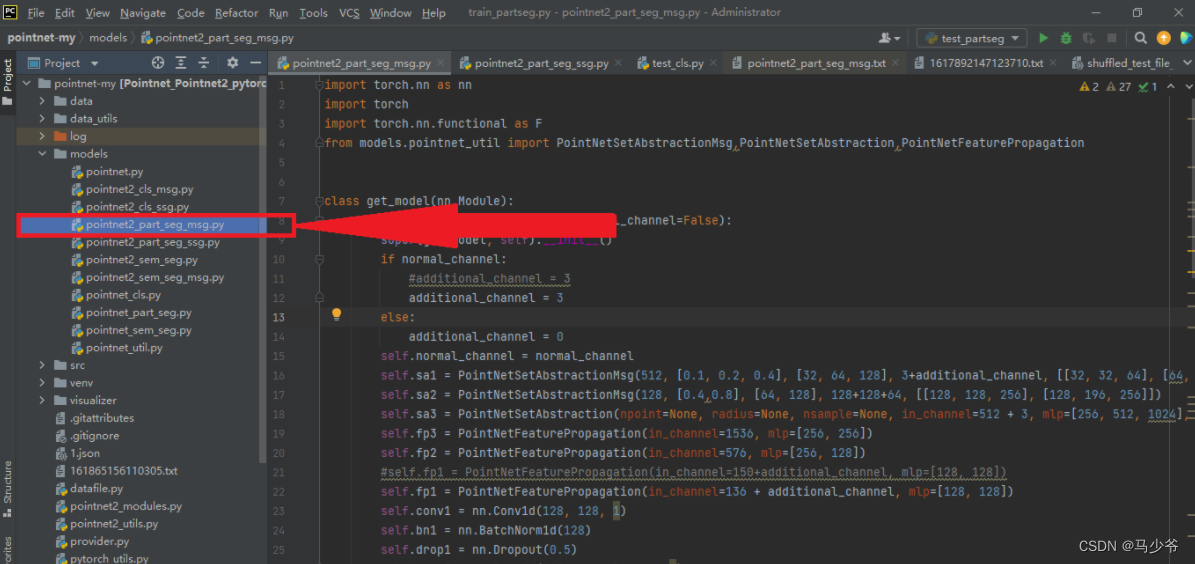
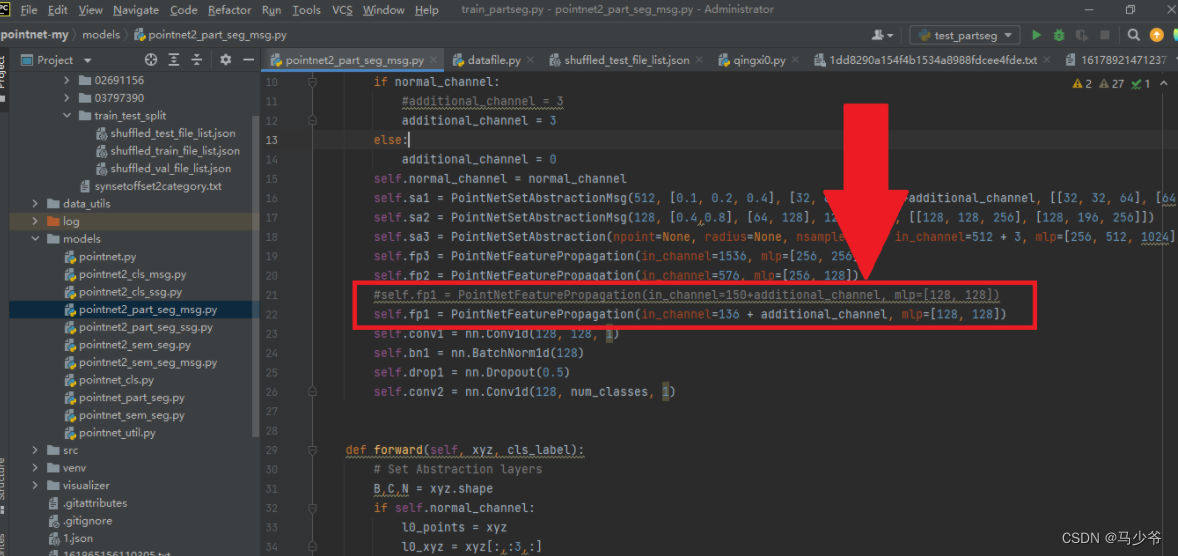
Next, we need to modify PointNetFeaturePropagation Of in_channel, The specific method is 128+4 Total number of classes divided , For example, our segmentation here uses two objects , Each object is 2 classification , So the number of channels is 128+42=136:
Next, we need to modify the part of the independent heat coding , take view The second parameter in the method is modified to the number of types of objects to be segmented :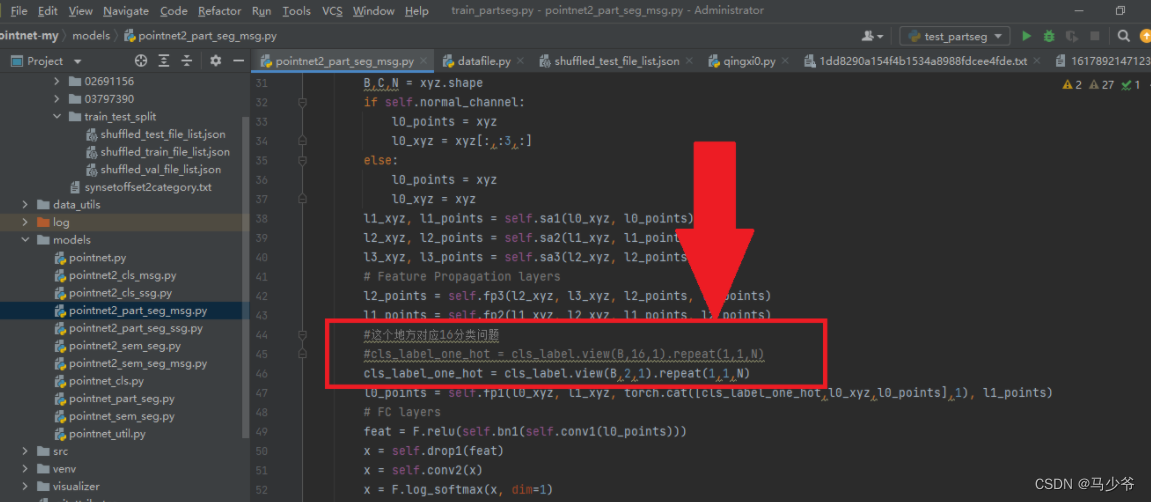
2.2.5 Modification of training model
In training the model , We need to modify the objects to be classified seg_classes For the category corresponding to our own dataset , For example, the classification in the example includes two categories , Each category has two components .( For convenience , We keep the original ’Airplane’: [0, 1], ‘Mug’: [2, 3] These two names , At the same time, we should pay attention to it , The number should be from 0 Start numbering in sequence , If not, an error will be reported ), At the same time, you should pay attention to whether your computer supports it cuda Speed up , without GPU, You can put all the following code ".cuda()" delete , The program can run correctly .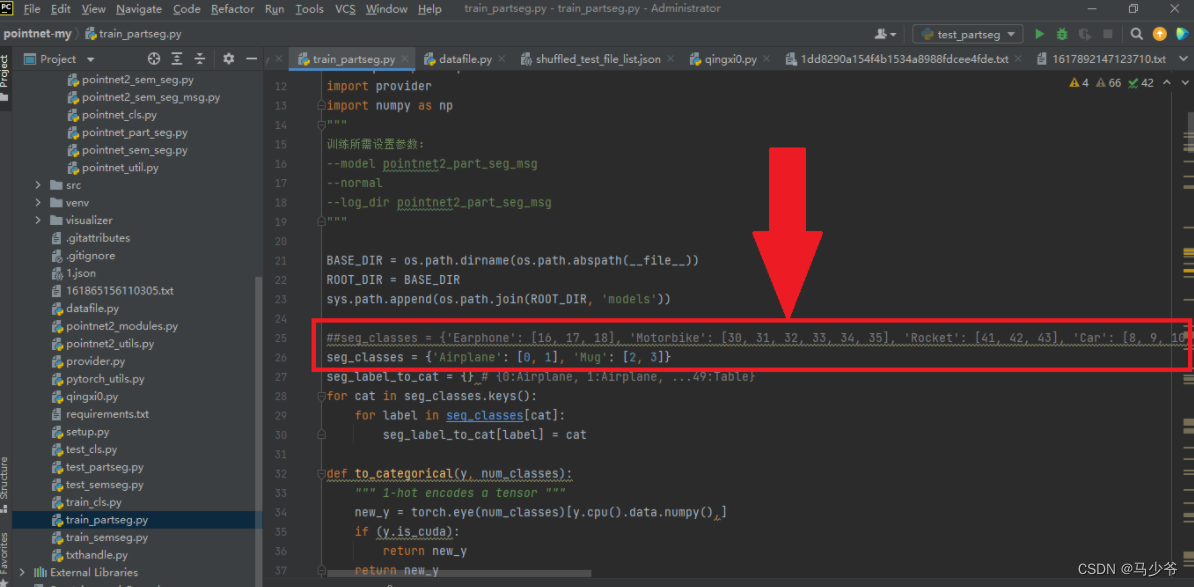
Next, we need to modify the total number of segmented objects num_classes Number your categories , The total number of parts is your total number :num_part.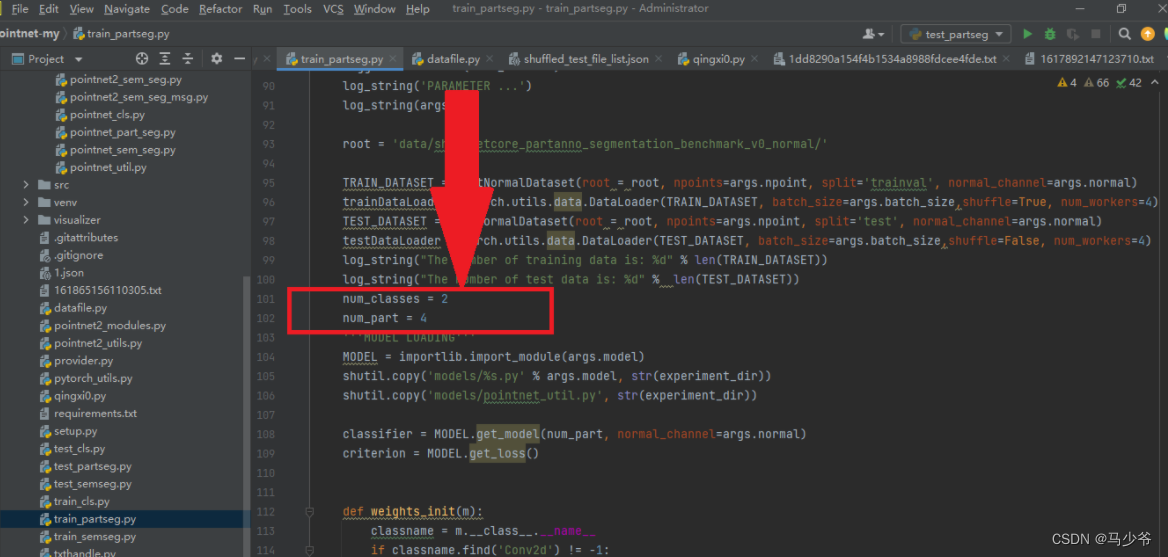
Last , Right click to run the program , If a progress bar appears, it indicates that the model has been successfully improved , You can run through your own data set !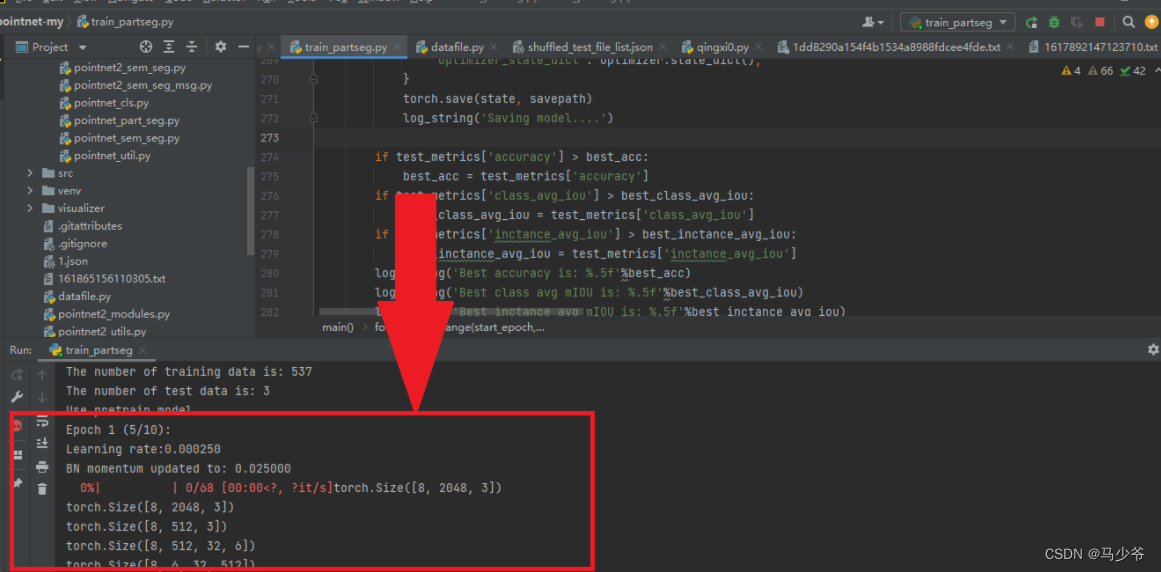
Four 、 Print model prediction data
After training the model with our own data set , Will use the name test_partseg Of python File to test the model , In order to better understand the model and test the effect of the model , Sometimes we need to print out the point cloud coordinates predicted by the model . Here is given test_partseg File modification method and operation results .
4.1 Test model code modification
First we need to find the python file , Then make the same changes as above, as shown in the following two places :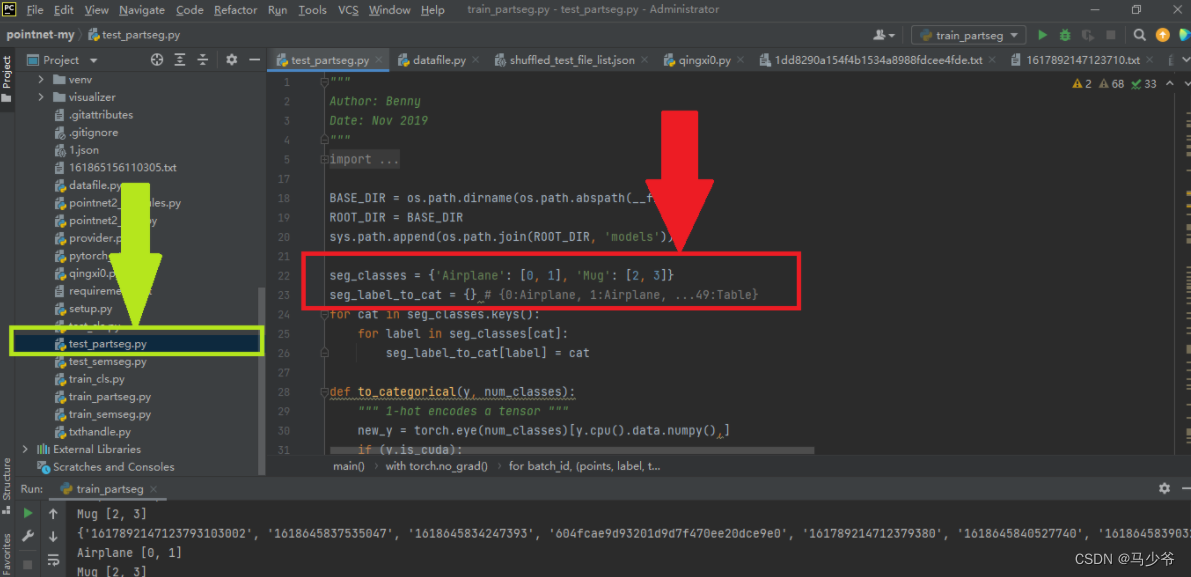
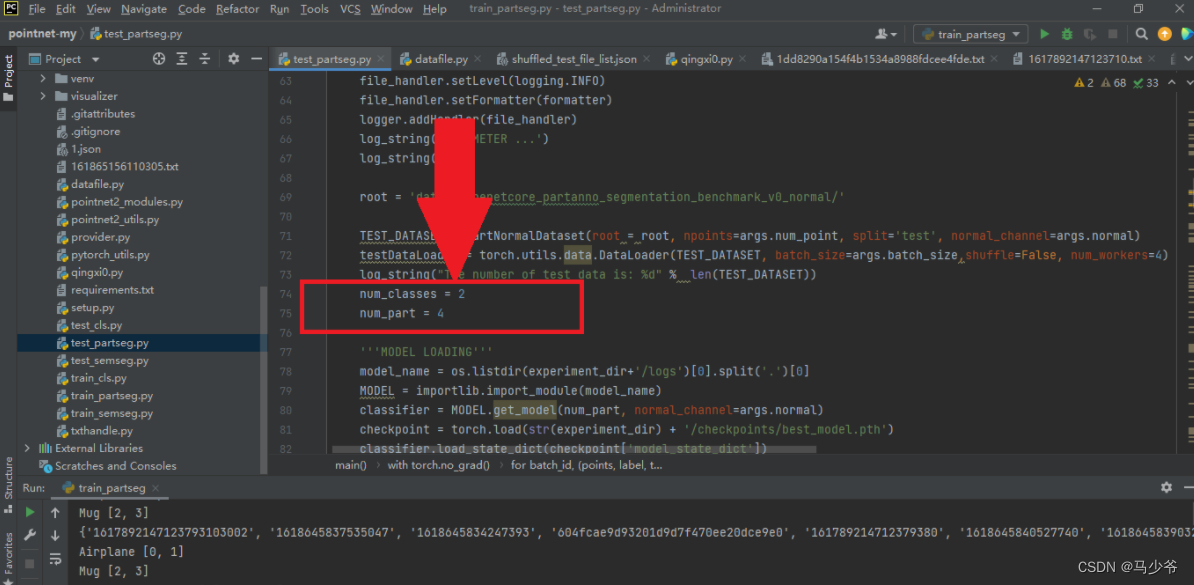
Then we need to write code to print out the coordinates with different labels after classification , In this example, we want to print the coordinate points of four categories of two objects , The code is as follows ( Part of the code ):
for j in aaa:
#print(points1[i,j])
res1= open(r'E:\03797390_0_'+str(i)+'.txt', 'a')
res1.write('\n' + str(points1[i,j]).strip('[]'))
res1.close()
xxxxxx=xxxxxx+1
bbb = numpy.argwhere(cur_pred_val[i] == 1)
for j in bbb:
#print(points1[i, j])
res2 = open(r'E:\03797390_1_' + str(i) + '.txt', 'a')
res2.write('\n' + str(points1[i,j]).strip('[]'))
res2.close()
xxxxxx = xxxxxx + 1
ccc = numpy.argwhere(cur_pred_val[i] == 2)
for j in ccc:
#print(points1[i, j])
res3 = open(r'E:\02691156_2_' + str(i) + '.txt', 'a')
res3.write('\n' + str(points1[i,j]).strip('[]'))
res3.close()
xxxxxx = xxxxxx + 1
ddd = numpy.argwhere(cur_pred_val[i] == 3)
for j in ddd:
#print(points1[i, j])
res4 = open(r'E:\02691156_3_' + str(i) + '.txt', 'a')
res4.write('\n' + str(points1[i,j]).strip('[]'))
res4.close()
xxxxxx = xxxxxx + 1
After the modification, run the program and find that the results can be displayed , Indicates that the modification was successful !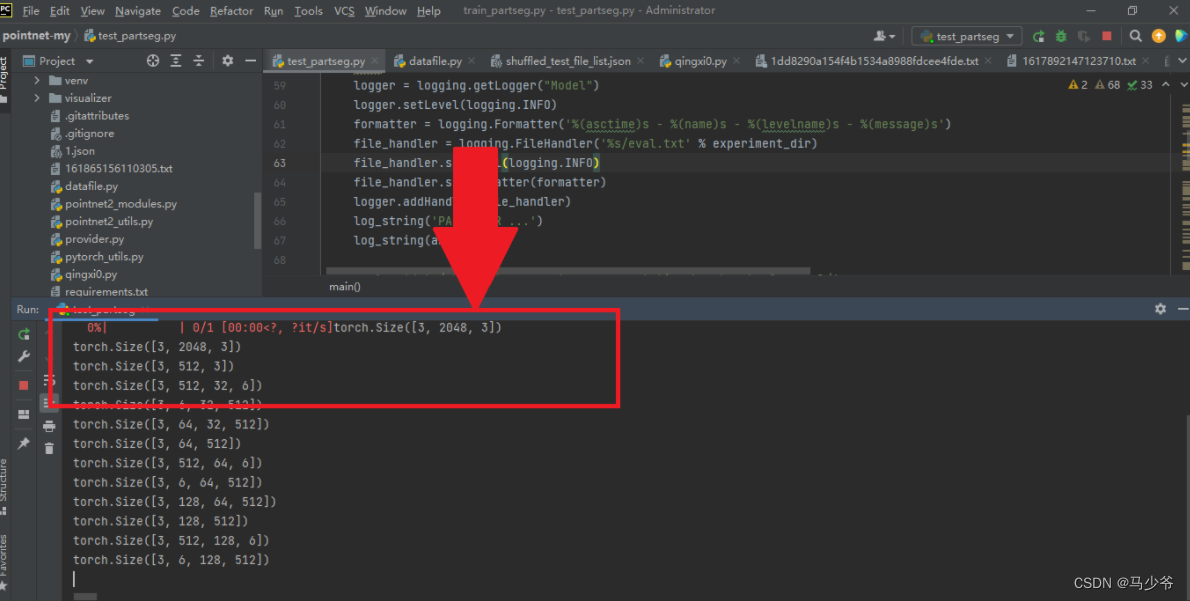
The format of the printed point cloud coordinates is as follows :

reference :https://blog.csdn.net/weixin_44603934/article/details/123589948
边栏推荐
- 1007 Maximum Subsequence Sum(25 分)(PAT甲级)
- QT realizes interface sliding switching effect
- How test engineers "attack the city" (Part I)
- Dark horse programmer - software testing - stage 07 2-linux and database -09-24-linux command learning steps, wildcards, absolute paths, relative paths, common commands for files and directories, file
- Pytorch学习(四)
- Hough Transform 霍夫变换原理
- SSRS筛选器的IN运算(即包含于)用法
- Comment utiliser async awati asynchrone Task Handling au lieu de backgroundworker?
- BCG 使用之新建向导效果
- 数据集划分
猜你喜欢






随机推荐
线上数据库迁移的几种方法
SSRS筛选器的IN运算(即包含于)用法
Detailed explanation of the binary processing function threshold() of opencv
Kotlin condition control
华为nova 10系列支持应用安全检测功能 筑牢手机安全防火墙
FPGA timing constraint sharing 01_ Brief description of the four steps
上线首月,这家露营地游客好评率高达99.9%!他是怎么做到的?
欧拉函数
How to use async Awati asynchronous task processing instead of backgroundworker?
Several methods of online database migration
Explore the contour drawing function drawcontours() of OpenCV in detail with practical examples
HMM隐马尔可夫模型最详细讲解与代码实现
【毕业季】绿蚁新醅酒,红泥小火炉。晚来天欲雪,能饮一杯无?
@transactional滥用导致数据源连接池耗尽问题
Abc229 summary (connected component count of the longest continuous character graph in the interval)
What should we pay attention to when doing social media marketing? Here is the success secret of shopline sellers!
Online sql to excel (xls/xlsx) tool
矩阵翻转(数组模拟)
Kotlin basic data type
数据集划分