当前位置:网站首页>MMA安装及使用优化
MMA安装及使用优化
2022-08-03 21:03:00 【选手一号位】
1.背景
公司自建的Hadoop集群,后期使用阿里的Maxcompute,就需要迁移数据到新环境中,阿里提供众多的迁移方案,在经过我们的实践后,最终选择了MMA,迁移数据Hive到Maxcompute。
2.MMA介绍
MMA(MaxCompute Migration Assist)是一款MaxCompute数据迁移工具。
在 Hive 迁移至 MaxCompute 的场景下,MMA 实现了 Hive 的 UDTF,通过 Hive 的分布式能力,实现 Hive 数据向 MaxCompute 的高并发传输。
这种迁移方式的优点有:
- 读数据由 Hive 自身完成,因此可以被 Hive 读的数据(包括 Hive 外表),都可以用 MMA 向 MaxCompute 迁移,且不存在任何数据格式问题
- 支持增量数据迁移
- 迁移效率高,迁移速率可以随资源分配线性提高
这种迁移方式的前置条件有:
- Hive 集群各节点需要具备访问 MaxCompute 的能力
架构与原理
当用户通过 MMA client 向 MMA server 提交一个迁移 Job 后,MMA 首先会将该 Job 的配置记录在元数据中,并初始化其状态为 PENDING。
随后,MMA 调度器将会把这个 Job 状态置为 RUNNING,向 Hive 请求这张表的元数据,并开始调度执行。这个 Job 在 MMA 中会被拆分为若干 个 Task,每一个 Task 负责表中的一部分数据的传输,每个 Task 又会拆分为若干个 Action 进行具体传输和验证。在逻辑结构上,每一个 Job 将会包含若干个 Task 组成的 DAG,而每一个 Task 又会包含若干个 Action 组成的 DAG。整体的流程大致如下:
┌──────────────────────────────────────────────────────────────────────────────────────────────-┐
│ HiveToMcTableJob │
│ │
│ ┌───────────────────────────┐ │
│ │ SetUpTask │ ┌────────────────────────────────────────────────────────┐ │
│ │ │ │ TableDataTransmissionTask │ │
│ │ DropTableAction │ │ │ │
│ │ | │ │ TableDataTransmissionAction(数据传输) │ │
│ │ CreateTableAction ├────►│ | | │ │
│ │ | │ │ HiveVerificationAction McVerificationAction │ │
│ │ DropPartitionAction │ │ | | │ │
│ │ | │ │ VerificationAction(对比验证结果) │ │
│ │ AddPartitionAction │ └────────────────────────────────────────────────────────┘ │
│ └───────────────────────────┘ │
│ │
└──────────────────────────────────────────────────────────────────────────────────────────────┘
官方文档:https://github.com/aliyun/alibabacloud-maxcompute-tool-migrate/blob/master/documents/HiveToMaxCompute_zh_v0.1.0.md
3.安装
3.1下载解压
版本选择跟自己的Hive版本相符即可。这里选择mma-0.1.1-hive-2.x.zip
下载链接:https://github.com/aliyun/alibabacloud-maxcompute-tool-migrate/releases
下载解压后:
[[email protected] mma]# unzip mma-0.1.1-hive-2.x.zip
[[email protected] mma]# cd mma-0.1.1
[[email protected] mma-0.1.1]# pwd
/data/soft/mma/mma-0.1.1
[[email protected] mma-0.1.1]# ll
total 20
drwxr-xr-x 2 root root 4096 Mar 28 12:01 bin
drwxr-xr-x 2 root root 4096 Sep 19 2021 conf
drwxr-xr-x 5 root root 4096 Apr 22 16:25 lib
drwxr-xr-x 3 root root 4096 Apr 22 16:25 res
-rw-r--r-- 1 root root 5 Apr 22 16:25 version.txt
[[email protected] mma-0.1.1]#
后面操作失败的,可以试试这个版本:
链接: https://pan.baidu.com/s/1WMHTrnzVqRDqqjJuVI5nyw 提取码: 38f6
3.2配置 MMA server
解压安装包之后,运行配置引导脚本:/data/soft/mma/mma-0.1.1/bin
[[email protected] bin]# ./configure
Hive configurations
Please input Hive metastore URI(s):
HELP: See: "hive.metastore.uris" in hive-site.xml
EXAMPLE: thrift://localhost:9083
>{thrift}
Please input Hive JDBC connection string
HELP: Same as the connection string used in beeline, which starts with jdbc:hive2
EXAMPLE: jdbc:hive2://localhost:10000
>{hive2}
Please input Hive JDBC user name
HELP: Same as the user name used in beeline. The default value is "Hive"
EXAMPLE: Hive
>{username}
Please input Hive JDBC password
HELP: Same as the password used in beeline
>{password}
Hive security configurations
Has Kerberos authentication? (Y/N)
>{isKerberos}
MaxCompute configurations
Please input MaxCompute endpoint
HELP: See: https://help.aliyun.com/document_detail/34951.html
EXAMPLE: http://service.cn.maxcompute.aliyun-inc.com/api
>{maxComputeEndpoint}
Please input MaxCompute project name
HELP: The target MaxCompute project
>{maxComputeProject}
Please input Alibaba cloud accesskey id
HELP: See: https://help.aliyun.com/document_detail/27803.html
>{accesskeyId}
Please input Alibaba accesskey secret
HELP: See: https://help.aliyun.com/document_detail/27803.html
>{accesskeySecret}
Generating MMA server configuration
MMA server configuration file path: /data/soft/mma/mma-0.1.1/conf/mma_server_config.json
Validating MMA server configurations
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data/soft/mma/mma-0.1.1/lib/client/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/data/soft/mma/mma-0.1.1/lib/connector/hive-uber.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Passed
Please execute the following commands manually to create required Hive UDTF
Upload Hive UDTF resource jar to HDFS:
hdfs dfs -put -f /data/soft/mma/mma-0.1.1/lib/data-transfer-hive-udtf-0.1.1-jar-with-dependencies.jar hdfs:///tmp/
Create Hive function in beeline:
DROP FUNCTION IF EXISTS default.odps_data_dump_multi;
CREATE FUNCTION default.odps_data_dump_multi as 'com.aliyun.odps.mma.io.McDataTransmissionUDTF' USING JAR 'hdfs:///tmp/data-transfer-hive-udtf-0.1.1-jar-with-dependencies.jar';
Press "ENTER" to confirm that the Hive UDTF has been created successfully
>
Congratulations! The configuration is completed!
[[email protected] bin]#
参数说明:
{thrift}:见 hive-site.xml 中"hive.metastore.uris"
{hive2}:通过 beeline 使用 Hive 时输入的 JDBC 连接串,必须为 default 库, 前缀为 jdbc:hive2
{username}:通常通过 beeline 使用 Hive 时输入的 JDBC 连接用户名, 默认值为 Hive
{password}:通常通过 beeline 使用 Hive 时输入的 JDBC 连接密码, 默认值为空
{isKerberos}:在使用 Kerberos 的情况下,需要配置其他参数,这里否
{maxComputeEndpoint}:经典网络Endpoint
{maxComputeProject}:建议配置为目标 MaxCompute project, 规避权限问题
{accesskeyId}:阿里云 accesskey id
{accesskeySecret}:阿里云 accesskey secret
3.3创建 Hive 函数
配置过程中还需要将某些文件上传至 HDFS,并在 beeline 中创建 MMA 需要的 Hive 永久函数。MMA 配置引导脚本会自动生成需要执行的命令,直接复制粘贴到安装有 hdfs 命令与 beeline 的服务器上执行即可。命令示例如下:
上传 Hive UDTF Jar 包至 HDFS:
hdfs dfs -put -f ${MMA_HOME}/res/data-transfer-hive-udtf-${MMA_VERSION}-jar-with-dependencies.jar hdfs:///tmp/
使用 beeline 创建 Hive 函数:
DROP FUNCTION IF EXISTS default.odps_data_dump_multi;
CREATE FUNCTION default.odps_data_dump_multi as 'com.aliyun.odps.mma.io.McDataTransmissionUDTF' USING JAR 'hdfs:///tmp/data-transfer-hive-udtf-${MMA_VERSION}-jar-with-dependencies.jar';
4.使用
4.1启动 MMA server
MMA server 进程在迁移期间应当一直保持运行。若 MMA server 因为各种原因中断了运行,直接执行以下命令重启即可。MMA server 进程在一台服务器最多只能存在一个。默认端口为 18889
/bin/mma-server
启动成功后,MMA支持WebUI:http://${hostname}:18888
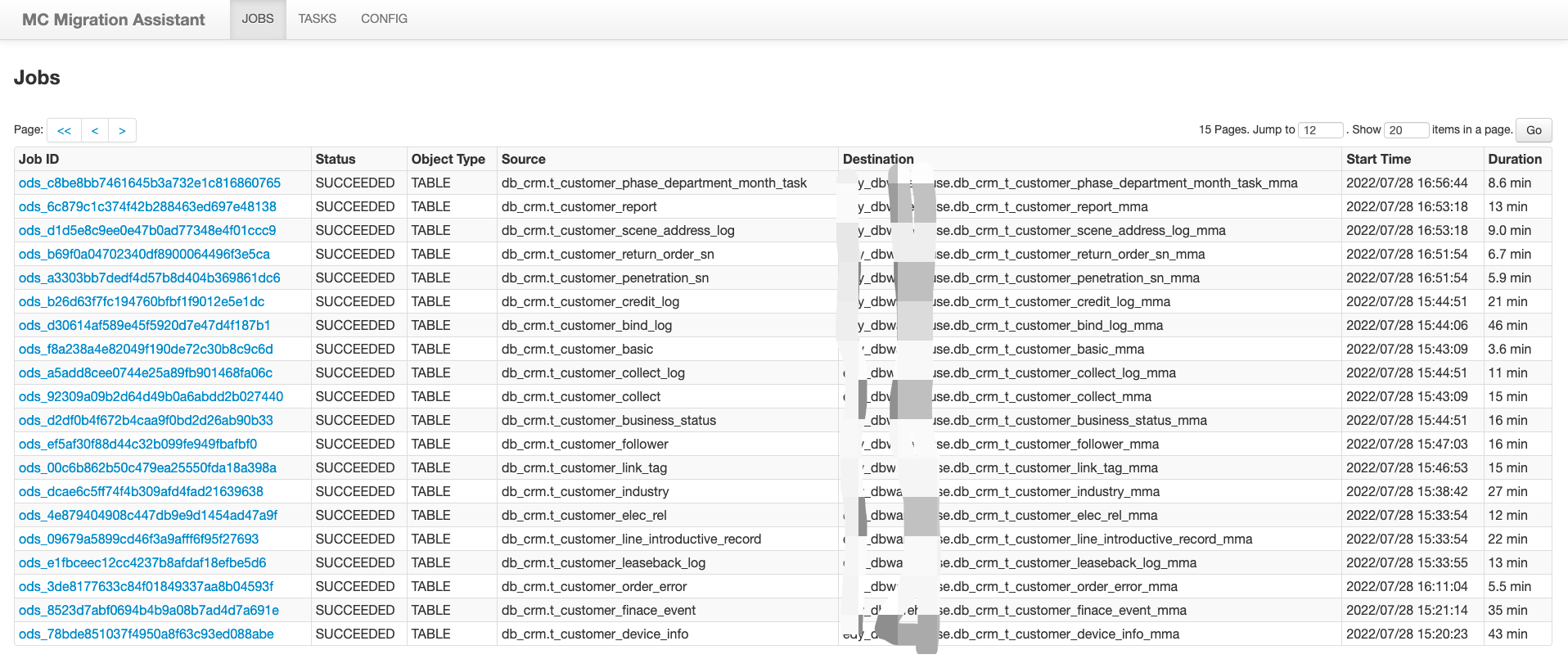
4.2生成任务配置
在生成配置任务前,需要先组织临时映射文件,有表级别和库级别,这里演示表级别,复制模板
[[email protected] ~]# cd /data/soft/mma/mma-0.1.1/conf/
[[email protected] conf]# cp table_mapping.txt.template table_mapping.txt
然后修改映射文件:vim table_mapping.txt
# generated for each of the following lines. Take the first line for an example, the source
# catalog(or database) and table are 'source_catalog' and 'source_table1', while the destination
# MaxCompute project and table are 'dest_pjt' and 'dest_table1'.
# 通过bin/gen-job-conf工具,以下每一行一行将会分别生成一个表迁移任务配置文件。每一行中,冒号(:)前后分别为源表和目标表
# 的全名。全名的格式为库名.表名,如source_catalog.source_table1:dest_pjt.dest_table1表示源表为source_catalog
# 库中的表source_table1,目标表为dest_pjt项目下的表dest_table1。
db_assets_pool.t_abs_payable:edy_dbwarehouse.db_assets_pool_t_abs_payable_mma
db_assets_pool.t_assets_device_backup:edy_dbwarehouse.db_assets_pool_t_assets_device_backup_mma
db_assets_pool.t_customer_received:edy_dbwarehouse.db_assets_pool_t_customer_received_mma
然后执行生成任务命令:
/bin/gen-job-conf --objecttype TABLE --tablemapping ${table_mapping_file}
其他参数
-jobid:可以指定 Job ID
-output:可以指定配置文件输出路径,不指定会默认生成到/conf目录下${objectType}-${sourceCatalog}-${destCatalog}-${job_id}.json
修改配置
生成配置文件后,需要指定迁移分区
{
"mma.filter.partition.begin":"2020-01-01",
"mma.filter.partition.end":"2020-05-01",
"mma.filter.partition.orders":"lex"
}
修改后:
{
"mma.object.source.catalog.name": "db_core_assets",
"mma.object.source.name": "b_asset",
"mma.object.type": "TABLE",
"mma.object.dest.catalog.name": "edy_dbwarehouse",
"mma.object.dest.name": "db_core_assets_b_asset_mma"
,"mma.filter.partition.begin":"2020-01-01","mma.filter.partition.end":"2020-05-01","mma.filter.partition.orders":"lex"
}
4.3提交任务
/bin/mma-client --action SubmitJob --conf
4.4查看任务状态
先查看所有迁移任务列表:
/bin/mma-client --action ListJobs
Job ID: 2263e913e9ba4130ac1e930b909dafab, status: FAILED, progress: 0.00%
Job ID: cf2c5f2f335041a1a1729b340c1d5fde, status: SUCCEEDED, progress: 0.00%
OK
/bin/mma-client --action GetJobInfo --jobid YOUR_JOB_ID
4.5其他命令
停止任务
/bin/mma-client --action StopJob --jobid YOUR_JOB_ID
重置任务
- 状态为
SUCCEEDEDFAILEDCANCELED三种状态下的任务可以被重置 - 当需要增量同步时,重置
SUCCEEDED状态下的任务 - 当需要重试失败任务时,重置
FAILEDCANCELED状态下的任务
/bin/mma-client --action ResetJob --jobid YOUR_JOB_ID
删除任务
/bin/mma-client --action DeleteJob --jobid YOUR_JOB_ID
5.优化
为了更自动化执行任务,生成任务配置,修改分区,提交任务,分别编写以下脚本
首先最新目录结构如下,db_crm,db_risk是对应的任务配置目录,后期再有其他库,可按照此方式添加
MMA_HOME
└── bin
├── configure # 生成 mma server 配置的工具
├── gen-job-conf # 生成任务配置的工具
├── mma-client # 客户端命令行工具
└── mma-server # 服务端命令行工具
└── conf
├── gss-jaas.conf.template
├── mma_server_config.json.template
└── table_mapping.txt.template
└── db_crm
├── finished # 完成的任务存放目录
├── table_mapping.txt # 任务配置文件
└── TABLE-* # 生成的任务json文件
└── db_risk
├── finished # 完成的任务存放目录
├── table_mapping.txt # 任务配置文件
└── TABLE-* # 生成的任务json文件
5.1 生成配置任务脚本
vim /data/soft/mma/mma-0.1.0/bin/mma_gen_job
#!/bin/bash
#desc: 生成任务job
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
mma=/data/soft/mma/mma-0.1.0
db=[email protected] #所dd有参数
echo $db
$mma/bin/gen-job-conf --objecttype TABLE --output $mma/conf/$db --tablemapping $mma/conf/$db/table_mapping.txt
使用示例:mma_gen_job db_crm
[[email protected] db_crm]# mma_gen_job db_crm
db_crm
mma_1bee5728-e5a3-4735-8818-9070ef47d0c1
Job configuration generated: /data/soft/mma/mma-0.1.0/conf/db_crm/TABLE-db_crm.t_visit_record-edy_dbwarehouse.db_crm_t_visit_record_mma-1658900626169.json
[[email protected] db_crm]# ll
total 12
drwxr-xr-x 2 root root 4096 Jul 27 11:44 done
-rw-r--r-- 1 root root 232 Jul 27 13:43 TABLE-db_crm.t_visit_record-edy_dbwarehouse.db_crm_t_visit_record_mma-1658900626169.json
-rw-r--r-- 1 root root 794 Jul 27 13:38 table_mapping.txt
完成后,将生成json文件,目录在 /conf/{db}下
5.2 添加分区任务
任务脚本生成之后,需要添加分区
vim /data/soft/mma/mma-0.1.0/bin/mma_modify_job
#!/bin/bash
#desc: 修改任务文件,添加分区范围
pcount=$#
if((pcount <3)); then
echo no args;
exit;
fi
#获取文件名称
p1=$1
fname=`basename $p1`
fname_bak=`basename $p1`_bak
echo fname=$fname
#获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#分区开始时间
p2=$2
#分区结束时间
p3=$3
#自定义jobid
uuid=`cat /proc/sys/kernel/random/uuid`
jobid=ods_`echo ${
uuid//-/}`
#新的json文件名
nfname=`echo $fname |cut -d"-" -f1-3`-"$jobid".json
echo "最新json文件名"$nfname
echo "任务jobid为:"$jobid
mma=/data/soft/mma/mma-0.1.0/bin
#提交任务
cat $pdir/$fname | jq '. + {"mma.filter.partition.begin":"'$p2'","mma.filter.partition.end":"'$p3'","mma.filter.partition.orders":"lex","mma.job.id":"'$jobid'"}' >> $pdir/$fname_bak
#重新生成json文件
rm -rf $pdir/$fname
cat $pdir/$fname_bak >> $pdir/$nfname
rm -rf $pdir/$fname_bak
使用示例:
mma_modify_job TABLE-db_crm.t_visit_record-edy_dbwarehouse.db_crm_t_visit_record_mma-1658902900181.json 2015-01-01 2022-05-01
[[email protected] db_crm]# mma_modify_job TABLE-db_crm.t_visit_record-edy_dbwarehouse.db_crm_t_visit_record_mma-1658902900181.json 2015-01-01 2022-05-01
fname=TABLE-db_crm.t_visit_record-edy_dbwarehouse.db_crm_t_visit_record_mma-1658902900181.json
pdir=/data/soft/mma/mma-0.1.0/conf/db_crm
最新json文件名TABLE-db_crm.t_visit_record-edy_dbwarehouse.db_crm_t_visit_record_mma-mma_f45c37bd31f64775b73bd6f88518ad07.json
任务jobid为:mma_f45c37bd31f64775b73bd6f88518ad07
5.3 提交任务脚本
vim /data/soft/mma/mma-0.1.0/bin/mma_submit_job
#!/bin/bash
#desc: 提交单个mma任务
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
mma=/data/soft/mma/mma-0.1.0/bin
#提交任务
nohup $mma/mma-client --action SubmitJob --conf $pdir/$fname 2>&1 &
使用示例
mma_submit_job TABLE-db_crm.t_call_log_current-edy_dbwarehouse.db_crm_t_call_log_current_mma-mma_1b37cda58bd446afabe355a86d488309.json
5.4查看任务脚本
vim /data/soft/mma/mma-0.1.0/bin/mma_getinfo_job
#!/bin/bash
#desc: 查看任务列表
mma=/data/soft/mma/mma-0.1.0
$mma/bin/mma-client --action GetJobInfo --jobid $1
5.5一键批量迁移任务
以上各脚本是单独执行,下面把这些脚本合成到一个脚本中,实现更加自动化的操作。
目前按照一个库迁移。
迁移步骤
- mapping映射文件需要手动一次性完成,文件目录:
/data/soft/mma/mma-0.1.0/conf/db_crm/table_mapping.txt - 根据映射文件生成json配置文件,对应一个表的迁移,使用脚本:
mma_gen_job - 根据json配置文件添加迁移分区,按照年迁移,一个json配置文件可生成多个,表示一个表对应多个迁移任务,使用脚本:
mma_modify_job - 按照顺序提交任务,使用脚本:
mma_submit_job
vim /data/soft/mma/mma-0.1.0/bin/mma_batch_job
#!/bin/bash
#desc: 一键批量迁移任务
# 1.生成任务
# 2.添加分区
# 3.提交任务
# 参数 $1:数据库 $2:分区开始 $3:分区结束
pcount=$#
#分区开始时间
p2=2015-01-01
#分区结束时间
p3=2022-05-01
if((pcount==1)); then
echo "批量迁移$1,默认迁移分区:$p2~$p3";
elif((pcount==3)); then
#分区开始时间
p2=$2
#分区结束时间
p3=$3
else
echo "命令实例:mma_batch_job db_crm 2015-01-01 2022-01-01"
echo "或者:mma_batch_job db_crm,不填分区,会使用默认分区"
exit;
fi
function ding_alert() {
webhook="https://oapi.dingtalk.com/robot/send?access_token=钉钉群机器人"
curl ${webhook} \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text", "text": { "content": "'$1'" } }'
}
path=/data/soft/mma/mma-0.1.0/conf/$1
echo "批量迁移任务 $1 >> 开始分区:$p2,结束分区:$p3"
mma=/data/soft/mma/mma-0.1.0/bin
#根据映射文件生成配置任务
$mma/mma_gen_job $1
#添加分区
for fname in $path/TABLE*
do
if [[ $fname =~ "ods_" ]];
# 包含ods_则表示已经添加了分区,跳过即可
then continue
fi
echo "添加任务分区:$fname"
$mma/mma_modify_job $fname $p2 $p3
done
#提交任务
for fname in $path/TABLE*
do
if [[ $fname =~ "ods_" ]]; then
echo "提交任务:$fname"
$mma/mma_submit_job $fname
ding_alert "迁移任务提交:$fname"
fi
done
使用示例:mma_batch_job db_crm,或者:mma_batch_job db_crm 2015-01-01 2022-05-01
5.6监测任务进度
前面已经指定,完成的配置任务单独备份到 finished 目录下,这里加一个监测任务进度的脚本,成功后将配置迁移走
vim /data/soft/mma/mma-0.1.0/bin/mma_check_job
#!/bin/bash
#desc: 查看mma任务状态,如果成功,则将配置任务移动到finished目录下
#需要走定时,是环境变量生效
source /etc/profile
path=/data/soft/mma/mma-0.1.0/conf
mma=/data/soft/mma/mma-0.1.0/bin
function ding_alert() {
webhook="https://oapi.dingtalk.com/robot/send?access_token=钉钉群机器人"
curl ${webhook} \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text", "text": { "content": "'$1\ $2'" } }'
}
#循环每个库的配置任务是否完成
for db in $path/db*
do
echo "监测的库:"$db
for fname in $db/TABLE*
do
if [[ $fname =~ "ods_" ]]; then
echo "json配置任务:"$fname
jobid=`echo "$fname"|cut -d'-' -f5|cut -d'.' -f1`
echo "获取任务jobid:"$jobid
echo "获取任务进度..."
result=`$mma/mma_getinfo_job $jobid |grep "status:"|awk -F ' ' '{print $NF}'`
echo "当前任务进度:$result"
dt=$(date +'%Y-%m-%d %H:%M:%S')
if [[ $result == 'SUCCEEDED' ]];then
echo "完成时间:$dt"
echo "任务同步完成,完成时间:$dt,将任务移动到finished目录下"
mv $fname $db/finished
msg="迁移任务<"$fname">已完成,完成时间:"$dt""
ding_alert $msg
elif [[ $result != 'PENDING' && $result != 'RUNNING' && $result != 'SUCCEEDED' && $result != 'FAILED' && $result != 'CANCELED' ]];then
echo "未获取到任务进度,尝试重新提交任务..."
$mma/mma_submit_job $fname
fi
fi
done
done
6.问题排查
查找导致失败的具体 Action
获取失败的jobid
/bin/mma-client --action ListJobs | grep FAILED
[[email protected] log]# ../bin/mma-client --action ListJobs | grep FAILED
Job ID: mma_1b37cda58bd446afabe355a86d488309, status: FAILED, progress: 0.00%
Job ID: 4bdc8676092a4dbc9dfd509936a03c07, status: FAILED, progress: 0.00%
OK
获得 Job ID 后可以执行以下命令获取失败的原因:
grep "Job failed" /log/mma_server.LOG | grep mma_1b37cda58bd446afabe355a86d488309
[[email protected] log]# grep "Job failed" mma_server.LOG|grep mma_1b37cda58bd446afabe355a86d488309
2022-07-27 15:10:46,960 INFO [main] job.AbstractJob (AbstractJob.java:fail(326)) - Job failed, id: mma_1b37cda58bd446afabe355a86d488309, reason: com.aliyun.odps.mma.server.task.HiveToMcTableDataTransmissionTask failed, id(s): 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3,2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.6,2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.7
2022-07-27 15:21:39,333 INFO [main] job.AbstractJob (AbstractJob.java:fail(326)) - Job failed, id: mma_1b37cda58bd446afabe355a86d488309, reason: com.aliyun.odps.mma.server.task.HiveToMcTableDataTransmissionTask failed, id(s): 7b0ae9cc-5cb7-4a3d-81c4-381a31ccf1c8.DataTransmission.part.0,7b0ae9cc-5cb7-4a3d-81c4-381a31ccf1c8.DataTransmission.part.1,7b0ae9cc-5cb7-4a3d-81c4-381a31ccf1c8.DataTransmission.part.2
2022-07-27 15:32:36,619 INFO [main] job.AbstractJob (AbstractJob.java:fail(326)) - Job failed, id: mma_1b37cda58bd446afabe355a86d488309, reason: com.aliyun.odps.mma.server.task.HiveToMcTableDataTransmissionTask failed, id(s): 2618bc2e-da37-421b-afd1-ca1c55cf3941.DataTransmission.part.0,2618bc2e-da37-421b-afd1-ca1c55cf3941.DataTransmission.part.1,2618bc2e-da37-421b-afd1-ca1c55cf3941.DataTransmission.part.2
[[email protected] log]#
获取失败的Action
grep 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3 mma_server.LOG | grep FAIL
[[email protected] log]# grep 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3 mma_server.LOG | grep FAIL
2022-07-27 14:58:19,139 ERROR [main] action.AbstractAction (AbstractAction.java:afterExecution(135)) - Action failed, actionId: 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3.DataTransmission, stack trace: java.util.concurrent.ExecutionException: java.sql.SQLException: org.apache.hive.service.cli.HiveSQLException: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
2022-07-27 14:58:19,139 INFO [main] action.AbstractAction (AbstractAction.java:setProgress(160)) - Set action status, id: 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3.DataTransmission, from: RUNNING, to: FAILED
2022-07-27 14:58:19,139 INFO [main] task.DagTask (DagTask.java:setStatus(92)) - Set task status, id: 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3, from: RUNNING, to: FAILED
2022-07-27 14:58:20,460 INFO [main] server.JobScheduler (JobScheduler.java:handleTerminatedActions(245)) - Action terminated, id: 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3.DataTransmission, status: FAILED
2022-07-27 14:58:30,547 INFO [main] server.JobScheduler (JobScheduler.java:handleTerminatedTasks(202)) - Task terminated, id: 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3, status: FAILED
2022-07-27 15:11:17,880 INFO [main] job.JobManager (JobManager.java:listSubJobsByStatus(736)) - List sub jobs by status, parent job id: basics: mma_1b37cda58bd446afabe355a86d488309, TABLE, Hive, Hive, MaxCompute, MaxCompute, db_crm, t_call_log_current, PENDING, extended: 98a44535-3bb8-4465-894a-791a557d8095.SetUp, SUCCEEDED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.0, SUCCEEDED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.1, SUCCEEDED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.2, SUCCEEDED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3, FAILED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.4, SUCCEEDED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.5, SUCCEEDED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.6, FAILED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.7, FAILED, 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.8, SUCCEEDED, status: PENDING
[[email protected] log]#
Action失败类型,这里是DataTransmission,继续查找错误
grep 2ba83078-9db8-4d68-bf4c-f63aa60139bf.DataTransmission.part.3 mma_server.LOG | grep "stack trace"
按照这个步骤基本上可以确定错误原因。
更多请在公号平台搜索:选手一号位,本文编号:2006,回复即可获取。
边栏推荐
猜你喜欢

安全基础8 ---XSS
手动输入班级人数及成绩求总成绩和平均成绩?
2022年强网杯rcefile wp
Li Mu hands-on learning deep learning V2-BERT fine-tuning and code implementation

迪赛智慧数——柱状图(多色柱状图):2021年我国城市住户存款排名
False label aggregation
XSS线上靶场---prompt
面试官:为什么 0.1 + 0.2 == 0.300000004?

Likou 707 - Design Linked List - Linked List

小朋友学C语言(1):Hello World
随机推荐
双线性插值公式推导及Matlab实现
七夕快乐!
迪赛智慧数——柱状图(多色柱状图):2021年我国城市住户存款排名
开源一夏 |如何优化线上服务器
敏捷交付的工程效能治理
6. XML
error: C1083: 无法打开包括文件: “QString”: No such error: ‘QDir‘ file not found
史兴国对谈于佳宁:从经济模式到落地应用,Web3的中国之路怎么走?
leetcode 326. Powers of 3
3种圆形按钮悬浮和点击事件
力扣59-螺旋矩阵 II——边界判断
svg胶囊药样式切换按钮
leetcode 461. Hamming Distance
PyCharm函数自动添加注释无参数问题
华为设备配置VRRP与BFD联动实现快速切换
Engineering Effectiveness Governance for Agile Delivery
2022-8-3 第七组 潘堂智 锁、多线程
leetcode 448. Find All Numbers Disappeared in an Array 找到所有数组中消失的数字(简单)
检测和控制影子IT的五个步骤
为什么 BI 软件都搞不定关联分析