当前位置:网站首页>Redis Foundation
Redis Foundation
2022-07-05 17:50:00 【Jinling town】
Redis brief introduction
Redis It's completely open source and free , comply with BSD agreement , Is a high-performance key-value database .
Redis And others key - value Cache products have the following three characteristics :
- Redis Support data persistence , The data in memory can be saved on disk , When you restart, you can load it again for use .
- Redis It's not just about supporting simple key-value Data of type , It also provides list,set,zset,hash Such as data structure storage .
- Redis Support data backup , namely master-slave Mode data backup .
Redis advantage
- Extremely high performance – Redis The speed at which you can read is 110000 Time /s, The speed of writing is 81000 Time /s .
- Rich data types – Redis Supporting binary cases Strings, Lists, Hashes, Sets And Ordered Sets Data type operations .
- atom – Redis All operations of are atomic , It means either successful execution or failure and no execution at all . Individual operations are atomic . Multiple operations also support transactions , Atomicity , adopt MULTI and EXEC Package the instructions .
- Rich features – Redis And support publish/subscribe, notice , key Expiration and so on .
Redis And others key-value What's the difference between storage ?
- Redis They have more complex data structures and provide atomic operations on them , This is a different evolutionary path from other databases .Redis All data types are based on basic data structure and transparent to programmers , There is no need for additional abstraction .
- Redis Run in memory but persist to disk , So we need to balance memory when we read and write different data sets at high speed , Because the amount of data cannot be larger than the hardware memory . Another advantage of in memory databases is , Compared to the same complex data structure on disk , It's very easy to operate in memory , such Redis Can do a lot of internal complexity of things . meanwhile , In terms of disk format, they are generated in a compact and additional way , Because they don't need random interviews .
redis How to install , I won't introduce you , Because different systems are installed differently . If you don't want to install it, you can use the online redis Environmental Science . But I'd like to recommend , Because I will use python To do something . among redis Visualization of the database can be used redis-desktop-manager. Command line operations use redis-cli.
Next I'll introduce you through different data structures redis The operation of .
character string (Strings)
character string (Strings) yes Redis One of the basic data structures of , from key and value form . We can compare it to programming language variables :keya Represents the variable name ,value Represents the value of the variable .
View all key The order of
keys *
Create string
set key value
If value Spaces in , You need to use **""** take value wrap up . Such as :
set x "xxx xxx xxx"Read string
get key
If you get a nonexistent key, Will return nil.
modify key The value of the inside
Make changes
Here's the command key Modification of existence , Create if it does not exist
set key New value If we don't want set What should I do if I overwrite the old value with the command of ? In the use of "NX" Parameters can be . such , When key In existence , Use set key value NX It doesn't cover the original value .
set key value NXAdd
If we want to value Add some strings at the end of , Use append command .( When key When it doesn't exist , Will create key) Of course , If the value has a space , and set It's the same way .
append key valueChange the numbers
Note that the following command is only for value In the case of numbers , Otherwise you will report an error .
# Give Way key The numbers inside plus 1 incr key # reduce 1 decr key # Add n incrby key n # reduce n decrby key n
Delete
If key If there is, put it back 1, Otherwise return to 0
del keyCode implementation
Here's how to use python Implement all of the above commands ( Any programming language is almost )
import redis
client = redis.Redis()
# Get all key
keys = client.keys()
# Create string
client.set("thisKey","thatValue")
# get value
value = client.get("thisKey")
# Do not overwrite changes
client.set("thisKey","way",nx=True)
# Add
client.append("thisKey","newMSg")
# Just change the numbers
client.set("num",1)
client.incr("num")
client.incrby("num",10)
client.decr("num")
client.decrby("num",4)
# Delete operation
client.delete("thisKey")Hash (Hash)
We introduced the string type of Redis Storage plan , At this time we can think about if I need to store 10w Personal scores , Right needs to store 10w Personal code ( If so ), How many do we need key?20w individual key!! So our key How to distribute it ( Be careful :key Can't repeat )? Do we have to : user name _score, user name _pwd, After the user name, add different types to represent different data . So in redis How to solve these problems ? Use Hashtable !! We can take a look at the data structure of the hash table This article
Redis hash It's a string Type of field and value Mapping table (key Let it be key),hash Ideal for storing objects , Every hash Can be stored 232 - 1 Key value pair (43 More than ). Use Hash The watch can not only reduce Redis in key The number of , And optimize storage space , It takes up a lot less memory than strings .
Here is redis The storage diagram of :

Add data :
Add one key value pair of data at a time :
hset key field value
Add multiple key value pairs of data at a time :
hmset key field1 value1 [field2 value2 ]
Of course, if we don't want to treat the existing field Make changes
hsetnx key field value
Get data :
Get the value of a field :
hget key field
Get the value of multiple fields :
hmget key field1 [field2]
Get all field names and values
hgetall key
Of course, we can get all of them separately field get value
hvals key
hkeys key
Determine whether a field exists
HEXISTS key field
Returns... If the field exists 1, Returns if it does not exist 0
Get the number of fields in the hash table
hlen key
Next I will not use python To achieve these things , We will introduce more about the characteristics of various structures . If you want to know more instructions, you can see Novice tutorial
list (List)
Lists are a fantastic structure , You can make a list of water pipes , Data can be entered from one side , Then come out from the other side ( Of course , That side can go in and out , It's just a different order ). So what's the use of this structure ? We can take sending messages as an example . We need to ensure the order of message arrival , So we can use the list ? for example : Send a message in from the left , Receive the message from the right . Here are a few simple instructions :
insert data
l representative left( Left ),r representative right( Right )
Insert data from the left
lpush key value
Insert data from the right
rpush key value
Get the length of the list
Notice the first one below l It doesn't mean left, It's about list
llen key
View the data
lrange key Start index End index
The index is numbered from the far left , It means the last one lpush The index of our data is 0( Think of the list as a small pipe ). If the start index is the same as the end index , Just return the value of the index position . So what if we start on the right ? Use “ Negative index ” that will do . among **-1** Represents the rightmost data .-2 Represents the second data on the far right .
Pop up data
Pop up the leftmost data
lpop key
Pop up the rightmost data
rpop key
The difference between popping up data and viewing data is , Data will also be deleted when data is popped up .
aggregate (Sets)
This set has the same concept as the set in mathematics . How to put it? ? stay redis The collection of , The data is A disorderly , Can't repeat .
Add data :
s For the assembly (set)
sadd key value1 value2 value3……
Get the number of elements in the collection
If the collection does not exist, return 0
scard key
Get data from the collection
spop key count
We said earlier , Sets are unordered , therefore spop The acquisition of is also disordered .( After obtaining the data, the data will be deleted )count Get several pieces of data on behalf of .
This is to get all the data of the collection ( It doesn't delete data ). However, this command is best not used in the production environment , Because of the large amount of data, your server may explode .
SMEMBERS key
Determine if the data exists
sismember key value
There is returned 1, Otherwise return to 0
Delete data
srem key value1 value2……
Here is the knowledge of mathematics
intersect
sinter key1 key2……
Union and collection
sunion key1 key2……
Take the difference set
sdiff key1 key2……
Ordered set (sorted sets)
Ordered set , As the name implies, the data in the collection is orderly . So what does it mean ? Let's imagine , In a highly concurrent scenario , The data is always up to date , If we store the data in the database , If you need to get rankings in real time , So it will definitely have a big impact on the performance of the data . After all, the larger the amount of data , The slower the sorting time is . It's different from a collection , The elements of an ordered set are associated with a double Score of type , The elements cannot be repeated , But the scores can be repeated .
Add data
zadd key score1 member1 [score2 member2]
As I said before ,score It has to be for double type , So if the input is not double May be an error .
Modifying data
Modify data to use zadd Score to modify data , At the same time, you can add NX Parameters
zadd key NX sorce member
You can also use zincrby Add and subtract data scores
ZINCRBY key Change quantity member
The amount of change can be either positive or negative . If member If it doesn't exist, it will create ,member The score is the same as the change .
get data
Based on the ranking within the rating range
- Sort from small to large
zrangebyscore An ordered collection name Lower scoring limit Upper scoring limit [withsores limit Slice start position The number of results ]
- Sort from large to small
zrevrangebyscore An ordered collection name Lower scoring limit Upper scoring limit [withsores limit Slice start position The number of results ]
The bracketed representation can be omitted , If withsores Omitting means only return value , Don't return score . Omit “limit Slice start position The number of results ” It means not slicing the results .
Location based sorting
Sort from small to large
The position starts from zero
zrange An ordered collection name Starting position ( contain ) End position ( contain )[withsores]
Sort from large to small
zrevrange An ordered collection name Starting position ( contain ) End position ( contain )[withsores]
Get rank
zrank An ordered collection name value
zrevrank An ordered collection name value
zrank and zrevrank The difference is that ,zrank The ranking is from 0 At the beginning , The lower the score, the closer the ranking 0, The lowest score is 0. and zrevrank The higher the score, the closer it is 0. The same thing is that if the value doesn't exist, it returns None.
Get a value score
zscore An ordered collection name value
Returns... If a value does not exist None.
See how many values are in a certain rating range
zcount An ordered collection name Lower scoring limit Upper scoring limit
Release the news / Subscribed Channels
Let's talk about a scene , Take the previous message sending scenario as an example , If the server's message is being updated , So how do we update the client information ? Follow the previous method , We only use polling query , At a certain time ( for instance 1s) Check redis, See if the news changes , If the news changes , Then the client will update , Then there will be the following questions :
- Keep checking redis, Consume system resources
- Use polling query , There will be a delay in the message
- Even if 1s( Polling time ) Sent 5 Bar message , Then the client will only change once .
At this time, we can use redis Of “ Release / subscribe ” Mode to realize message communication .
- Release : The publisher of the message
- subscribe : Receiver of message , It can be for 1 One can be more than one
Release the news
publish Channel name Information
Subscribed Channels
subscribe Channel name 1 Channel name 2……
It will return to 3 Bar message : The first is the type of information , The second is the channel name , The third is what is published . It needs to be noted that , We can only accept the current information , New subscriptions can't receive previous subscriptions .
Conclusion
The above is redis A very simple introduction to . It only introduces redis Simple use and some basic operations , as for redis More complex instructions in commands , Baidu or google That's it . about redis, I think we ( As a student ) What should be paid attention to is redis Why can we be so good ? What data structure is used in it , And how can you redis Apply to high concurrency scenarios , How to save and backup multi server data .
边栏推荐
- Abnormal recovery of virtual machine Oracle -- Xi Fenfei
- Knowledge points of MySQL (7)
- Seven Devops practices to improve application performance
- SQL Server(2)
- 力扣解法汇总1200-最小绝对差
- EPM相关
- 较文心损失一点点性能提升很多
- CVPR 2022 best student paper: single image estimation object pose estimation in 3D space
- Rider set the highlighted side of the selected word, remove the warning and suggest highlighting
- Sentinel flow guard
猜你喜欢

Knowledge points of MySQL (6)

哈趣K1和哈趣H1哪个性价比更高?谁更值得入手?
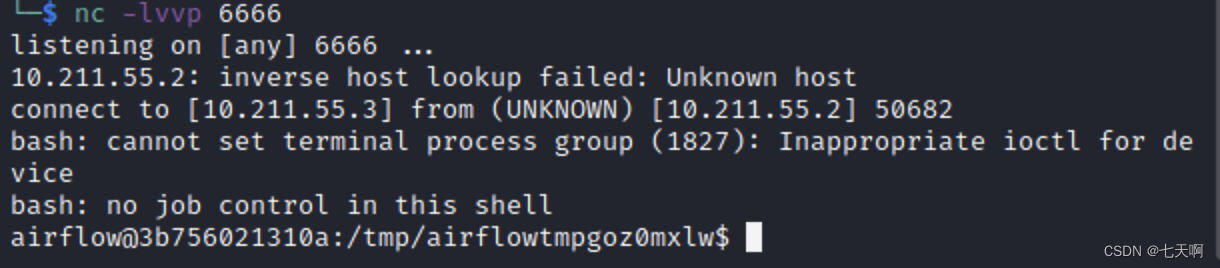
Vulnerability recurrence - 48. Command injection in airflow DAG (cve-2020-11978)
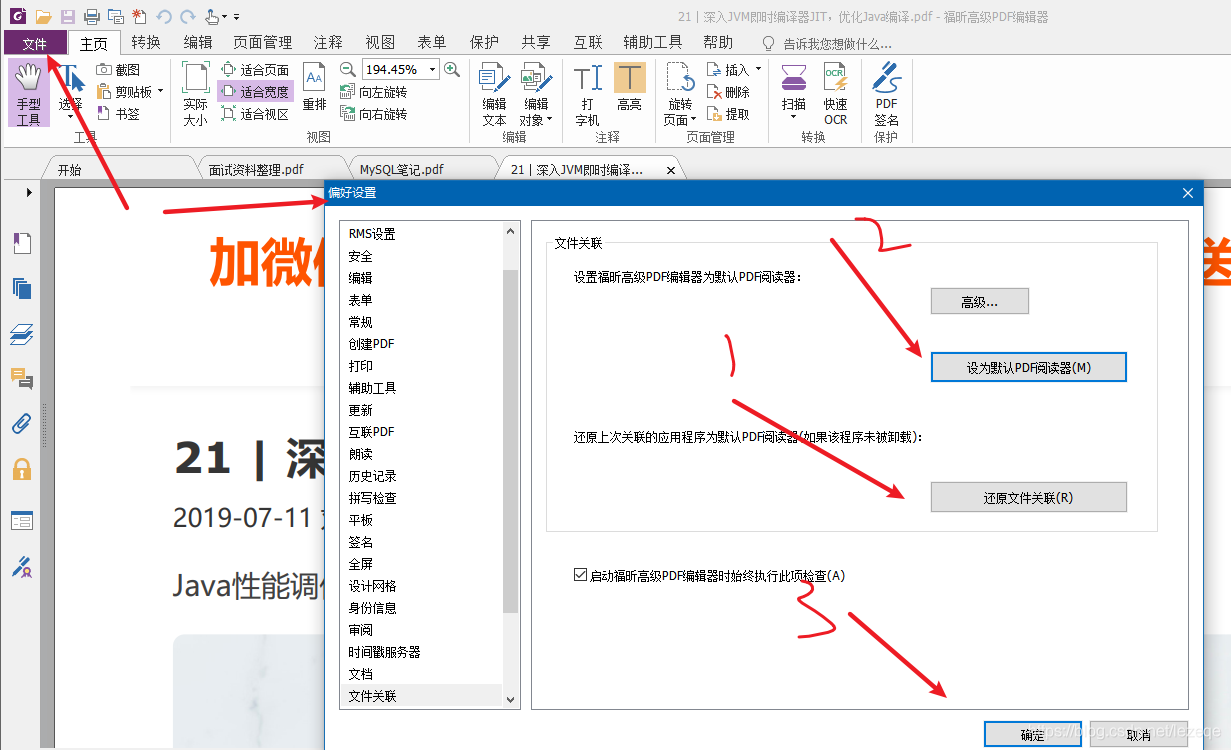
解决“双击pdf文件,弹出”请安装evernote程序
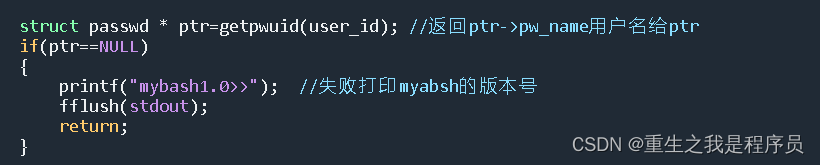
mybash

Ten top automation and orchestration tools

EPM相关

Leetcode daily practice: rotating arrays
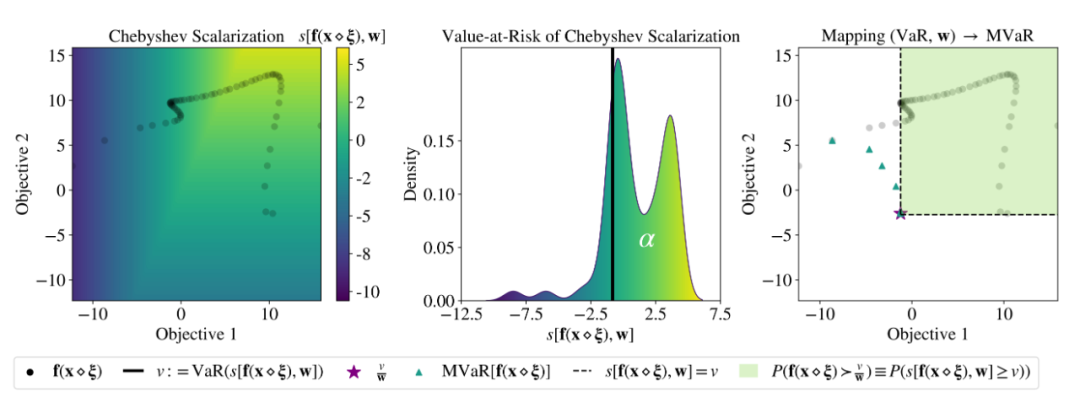
ICML 2022 | Meta提出魯棒的多目標貝葉斯優化方法,有效應對輸入噪聲
Which is more cost-effective, haqu K1 or haqu H1? Who is more worth starting with?
随机推荐
Abnormal recovery of virtual machine Oracle -- Xi Fenfei
论文阅读_中文NLP_LTP
Ordinary programmers look at the code, and top programmers look at the trend
解决“双击pdf文件,弹出”请安装evernote程序
为什么阳历中平年二月是28天
Please tell me why some tables can find data by writing SQL, but they can't be found in the data map, and the table structure can't be found
leetcode每日一题:字符串中的第一个唯一字符
蚂蚁金服的暴富还未开始,Zoom的神话却仍在继续!
如何保存训练好的神经网络模型(pytorch版本)
PMP认证需具备哪些条件啊?费用多少啊?
北京内推 | 微软亚洲研究院机器学习组招聘NLP/语音合成等方向全职研究员
rsync
Ten capabilities that cyber threat analysts should have
Compter le temps d'exécution du programme PHP et définir le temps d'exécution maximum de PHP
Cartoon: how to multiply large integers? (I) revised version
MySQL之知识点(六)
How to save the trained neural network model (pytorch version)
QT console printout
这个17岁的黑客天才,破解了第一代iPhone!
Size_ T is unsigned