当前位置:网站首页>Thesis reading_ Medical NLP model_ EMBERT
Thesis reading_ Medical NLP model_ EMBERT
2022-07-05 17:41:00 【xieyan0811】
English title :EMBERT: A Pre-trained Language Model for Chinese Medical Text Mining
Chinese title : A pre training language model for Chinese medical text mining
Address of thesis :https://chywang.github.io/papers/apweb2021.pdf
field : natural language processing , Knowledge map , Biomedical
Time of publication :2021
author :Zerui Cai etc. , East China Normal University
Source :APWEB/WAIM
Quantity cited :1
Reading time :22.06.22
Journal entry
For the medical field , utilize Synonyms in the knowledge map ( Only dictionaries are used , Graph calculation method is not used ), Training similar BERT Natural language representation model . The advantage lies in the substitution of knowledge , Specifically designed Three self supervised learning methods To capture the relationship between fine-grained entities . The experimental effect is slightly better than the existing model . No corresponding code found , The specific operation method is not particularly detailed , Mainly understand the spirit .
What is worth learning from , The Chinese medical knowledge map used , Among them, the use of synonyms ,AutoPhrase Automatically recognize phrases , Segmentation method of high-frequency word boundary, etc .
Introduce
The method in this paper is dedicated to : Make better use of a large number of unlabeled data and pre training models ; Use entity level knowledge to enhance ; Capture fine-grained semantic relationships . And MC-BERT comparison , The model in this paper pays more attention to exploring the relationship between entities .
The author mainly aims at three problems :
- Synonyms are different , such as : Tuberculosis And consumption It refers to the same disease , But the text description is different .
- Entity nesting , such as : Novel coronavirus pneumonia , Both contain pneumonia entities , It also contains the entity of novel coronavirus , Itself is also an entity , The previous method only focused on the whole entity .
- Long entity misreading , such as : Diabetes ketoacids , When parsing, you need to pay attention to the relationship between the primary entity and other entities .
The contribution of the article is as follows :
- A Chinese medical pre training model is proposed EMBERT(Entity-rich Medical BERT), You can learn the characteristics of medical terms .
- Three self supervised tasks are proposed to capture semantic relevance at the entity level .
- Six Chinese medical data sets were used to evaluate , Experiments show that the effect is better than the previous method .
Method
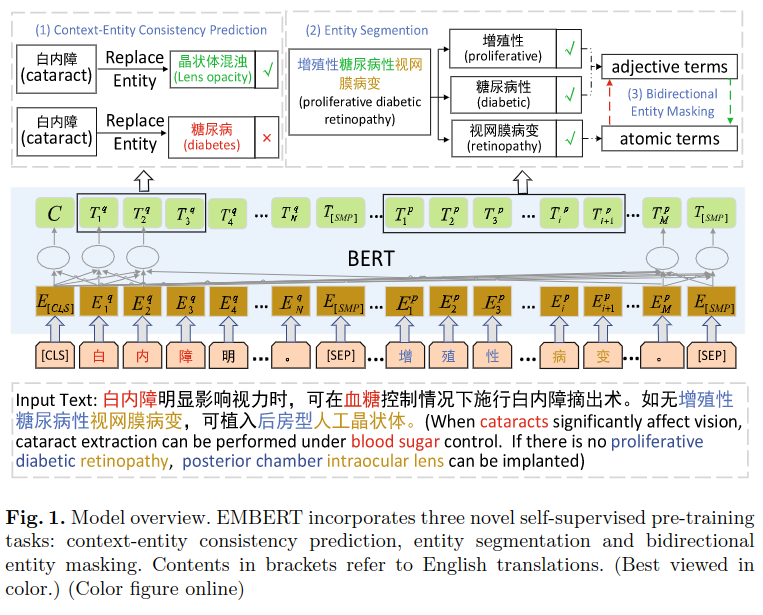
Entity context consistency prediction
Use from http://www.openkg.cn/ From the knowledge map of SameAs Relationship building dictionary , Replace the words in the data set with synonyms to construct more training data , Then predict the consistency between the replaced entity and the context , To improve the effect of the model . On the principle of , The context of the replaced entity and the original entity should also be consistent .
Suppose a sentence contains words x1…xn, Replaced the i Entity xsi,…xei, among s and e Indicates the starting and ending position of replacement , Its context refers to the location in si Before and si What follows , use ci Express .
First , Encode the replaced entity as a vector yi:
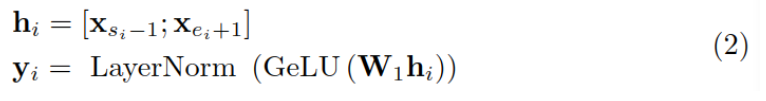
then , utilize yi To predict the context ci, And calculate the loss function :
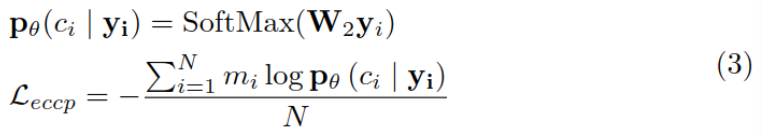
Entity segmentation
A rule-based system is used to cut the long entity into several parts of semantics , And label , Training model with labeled data .
The way to do it is Build a physical vocabulary , Get a group of high-quality entities in the medical field from the Training Center , Combine with entities in the knowledge map . First use AutoPhrase Generate the original segmentation result , Calculate the frequency of the start and end positions of each segment , Yes top-100 Manual check of high-frequency words , As a tangent diversity .
set up Long entity is xsi,…,xei, Cut it further xeij,…,xeij, And the last position of the segmented segment xsij Label as the syncopation point 1, Other location labels are 0, Training models to predict this label , It is defined as a binary classification problem . Formula y Is this position token Vector representation of .
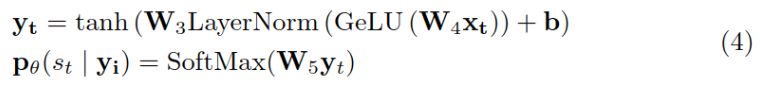
The loss function is calculated as follows :
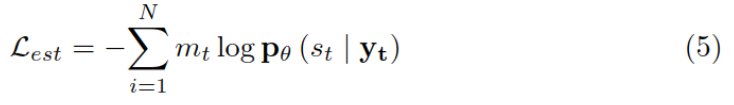
Bidirectional entity masking
Use the method in the previous step , Long entities can be divided into adjectives and meta entities ( The main entities ), Cover adjectives , Use the primary entity to predict it ; Relative , Also mask the main entity , Predict it with adjectives .
Take the masking meta entity as an example , Use adjectives and relative positions p To calculate the representation of meta entities :
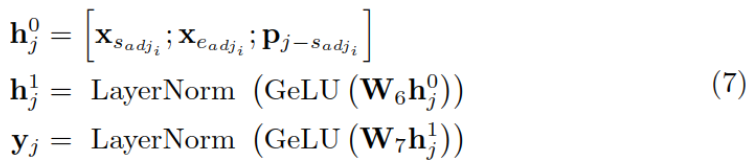
And then use it yj To predict the xj, And calculate the cross entropy as the loss function :
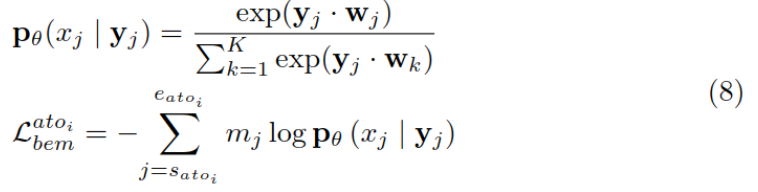
The same is true of using meta entity prediction to predict adjectives , The final loss function Lben It is the sum of two losses .
Loss function
The final loss function , contain BERT The loss of Lex And the loss of the above three methods ,λ It's a super parameter. .
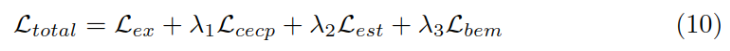
experiment
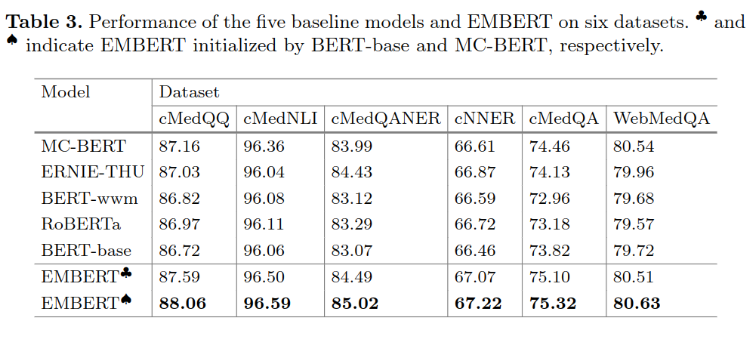
Use dingxiangyuan medical community Q & A and BBS Data training model , Data volume 5G, The training data used in this paper is obviously less than MC-BERT, But the effect is similar .
The main experimental results are as follows :
边栏推荐
- Cartoon: how to multiply large integers? (integrated version)
- Vulnerability recurrence - 48. Command injection in airflow DAG (cve-2020-11978)
- 漫画:寻找无序数组的第k大元素(修订版)
- ICML 2022 | Meta propose une méthode robuste d'optimisation bayésienne Multi - objectifs pour faire face efficacement au bruit d'entrée
- Is it safe for China Galaxy Securities to open an account? How long can I buy stocks after opening an account
- thinkphp3.2.3
- Humi analysis: the integrated application of industrial Internet identity analysis and enterprise information system
- Troubleshooting - about clip not found Visual Studio
- 机器学习01:绪论
- 基于51单片机的电子时钟设计
猜你喜欢
VBA drives SAP GUI to realize office automation (II): judge whether elements exist

7 pratiques devops pour améliorer la performance des applications

WR | Jufeng group of West Lake University revealed the impact of microplastics pollution on the flora and denitrification function of constructed wetlands

哈趣K1和哈趣H1哪个性价比更高?谁更值得入手?
Summary of optimization scheme for implementing delay queue based on redis
Database design in multi tenant mode
MySql 查询符合条件的最新数据行

十个顶级自动化和编排工具
ICML 2022 | Meta提出魯棒的多目標貝葉斯優化方法,有效應對輸入噪聲

leetcode每日一题:字符串中的第一个唯一字符

随机推荐
How to write a full score project document | acquisition technology
2022 information system management engineer examination outline
Read the history of it development in one breath
Cartoon: a bloody case caused by a math problem
Flow characteristics of kitchen knife, ant sword, ice scorpion and Godzilla
Q2 encryption market investment and financing report in 2022: gamefi becomes an investment keyword
证券网上开户安全吗?证券融资利率一般是多少?
mysql中取出json字段的小技巧
Learn about MySQL transaction isolation level
Seven Devops practices to improve application performance
解决“双击pdf文件,弹出”请安装evernote程序
云主机oracle异常恢复----惜分飞
读libco保存恢复现场汇编代码
CVPR 2022最佳学生论文:单张图像估计物体在3D空间中的位姿估计
Vulnerability recurrence - 48. Command injection in airflow DAG (cve-2020-11978)
世界上最难的5种编程语言
Cartoon: interesting [pirate] question
C # realizes crystal report binding data and printing 3-qr code barcode
Accuracy of BigDecimal Division
Force deduction solution summary 729- my schedule I