当前位置:网站首页>论文阅读_医疗NLP模型_ EMBERT
论文阅读_医疗NLP模型_ EMBERT
2022-07-05 17:16:00 【xieyan0811】
英文题目:EMBERT: A Pre-trained Language Model for Chinese Medical Text Mining
中文题目:中文医学文本挖掘的预训练语言模型
论文地址:https://chywang.github.io/papers/apweb2021.pdf
领域:自然语言处理,知识图谱,生物医疗
发表时间:2021
作者:Zerui Cai等,华东师范大学
出处:APWEB/WAIM
被引量:1
阅读时间:22.06.22
读后感
针对医疗领域,利用知识图中的同义词(只使用了词典,未使用图计算方法),训练类似BERT的自然语言表示模型。优势在于代入了知识,具体设计了三种自监督学习方法来捕捉细粒度实体间的关系。实验效果略好于现有模型。没找到对应代码,具体的操作方法写的也不是特别细,主要领会精神。
比较值得借鉴的是,其中用到的中文医疗知识图,其中同义词的使用方法,AutoPhrase自动识别短语,高频词边界的切分方法等。
介绍
文中方法致力于:更好地利用大量未标注数据和预训练模型;使用实体级的知识增强;捕捉细粒度的语义关系。与 MC-BERT 相比,文中的模型更注重探索实体间的关系。
作者主要针对三个问题:
- 同义不同词,比如: 结核病 与 痨病 指的是同一疾病,但文本描述不同。
- 实体嵌套,比如:新型冠状病毒肺炎,既包含肺炎实体,又包含新型冠状病毒实体,自身也是一个实体,之前方法只关注了整个实体。
- 长实体误读,比如:糖尿病酮酸,解析时需要关注主实体与其它实体的关系。
文章贡献如下:
- 提出了中文医疗预训练模型 EMBERT(Entity-rich Medical BERT),可学习医学术语的特征。
- 提出三种自监督任务捕捉实体层面的语义相关性。
- 使用六个中文医疗数据集评测,实验证明效果好于之前方法。
方法
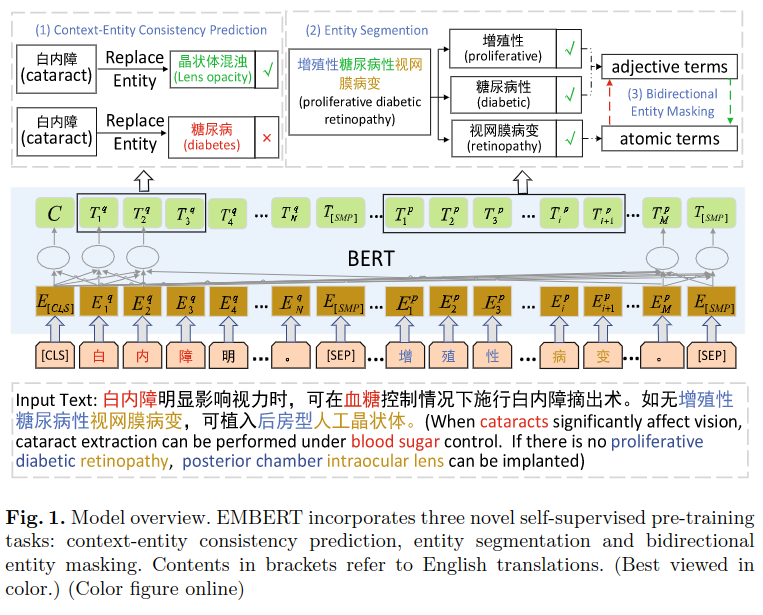
实体上下文一致性预测
利用从http://www.openkg.cn/的知识图中取到的 SameAs 关系建立词典,用同义词替换数据集中的词构造更多训练数据,再预测被替换的实体与上下文的一致性,以提升模型效果。原理上,被替换的实体和原有实体的上下文也应具有一致性。
假设一个句子包含字x1…xn,替换了其中的第i个实体 xsi,…xei,其中s和e表示替换的起止位置,其上下文指的是位置在si之前和si之后的内容,用ci表示。
首先,将替换后的实体编码为向量 yi:
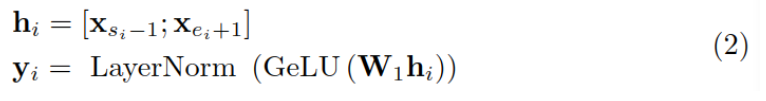
然后,利用 yi 来预测上下文 ci,并计算损失函数:
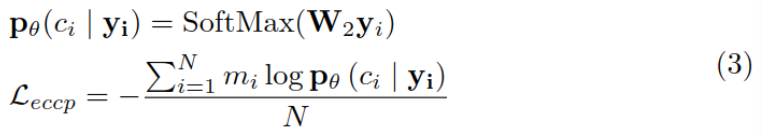
实体切分
使用基于规则的系统将长实体切分成几部分语义,并打标签,再用标注数据训练模型。
具体方法是建立一个实体词表,从训练集中获得一批高质量的医疗领域实体,与知识图中实体结合。先用AutoPhrase生成原始切分结果,计算每个片段开始和结束位置的频率,对top-100高频词手动检查,作为切分集。
设长实体为xsi,…,xei,将其进一步切分xeij,…,xeij,并将切分后小段的最后一个位置xsij作为切分点打标签为1,其它位置标签为0,训练模型来预测这个标签,将其定义为一个二分类问题。公式中的 y 是该位置token的向量表示。
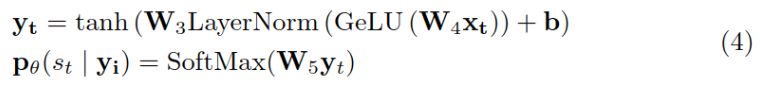
损失函数计算如下:
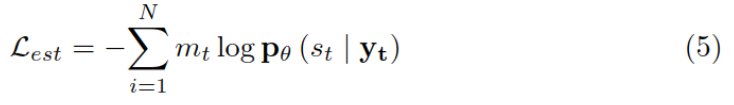
双向实体遮蔽
利用上一步方法,可把长实体分成形容词和元实体(主要的实体),遮蔽形容词,使用主实体预测它;相对的,也遮蔽主实体,用形容词预测它。
以遮蔽元实体为例,利用形容词和相对位置p来计算元实体的表示:
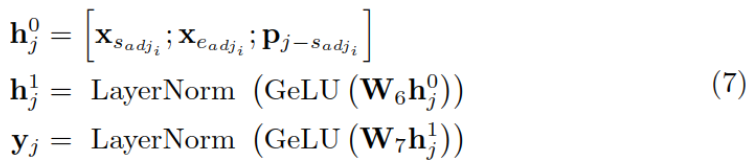
然后利用 yj 来预测 xj,并计算交叉熵作为损失函数:
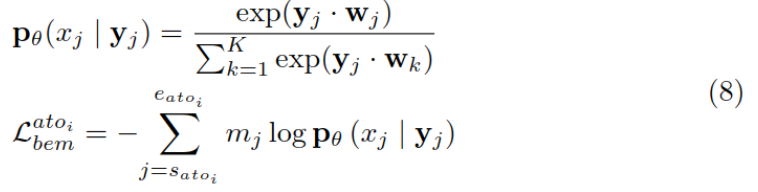
用元实体预测预测形容词也是同理,最后得到的损失函数Lben是两种损失的加和。
损失函数
最终的损失函数,包含BERT的损失Lex和上述三种方法的损失,λ是超参数。
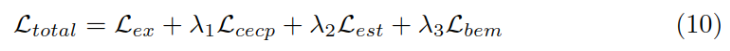
实验
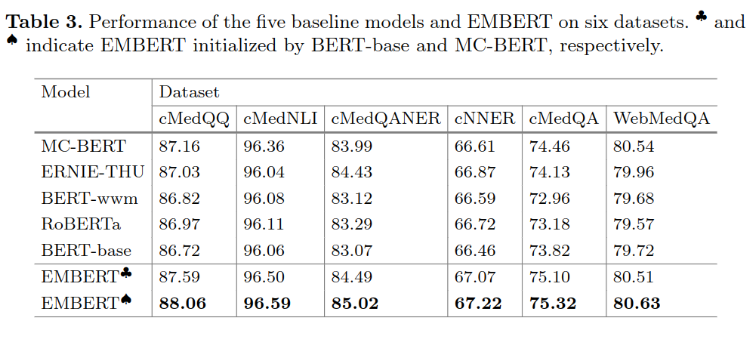
使用丁香园医疗社区问答及BBS数据训练模型,数据量5G,文中使用的训练数据明显少于MC-BERT,但效果与之相似。
主实验效果如下:
边栏推荐
- 世界上最难的5种编程语言
- IDEA 项目启动报错 Shorten the command line via JAR manifest or via a classpath file and rerun.
- 解决“双击pdf文件,弹出”请安装evernote程序
- Force deduction solution summary 1200 minimum absolute difference
- 一文了解MySQL事务隔离级别
- Function sub file writing
- flask解决CORS ERR 问题
- MYSQL group by 有哪些注意事项
- 漫画:一道数学题引发的血案
- mongodb(快速上手)(一)
猜你喜欢
MySql 查询符合条件的最新数据行

求解为啥all(())是True, 而any(())是FALSE?
c#图文混合,以二进制方式写入数据库

Knowledge points of MySQL (7)
深入理解Redis内存淘汰策略
Mongodb (quick start) (I)
mongodb(快速上手)(一)
Example tutorial of SQL deduplication

IDC报告:腾讯云数据库稳居关系型数据库市场TOP 2!
33: Chapter 3: develop pass service: 16: use redis to cache user information; (to reduce the pressure on the database)
随机推荐
提高应用程序性能的7个DevOps实践
基于51单片机的电子时钟设计
Tips for extracting JSON fields from MySQL
Understand the usage of functions and methods in go language
Tita performance treasure: how to prepare for the mid year examination?
Ordinary programmers look at the code, and top programmers look at the trend
thinkphp3.2.3
请问下为啥有的表写sql能查到数据,但在数据地图里查不到啊,查表结构也搜不到
漫画:如何实现大整数相乘?(上) 修订版
Cartoon: how to multiply large integers? (next)
Knowing that his daughter was molested, the 35 year old man beat the other party to minor injury level 2, and the court decided not to sue
机器学习01:绪论
goto Statement
Mongodb (quick start) (I)
The five most difficult programming languages in the world
Cartoon: how to multiply large integers? (I) revised version
漫画:寻找股票买入卖出的最佳时机
菜刀,蚁剑,冰蝎,哥斯拉的流量特征
漫画:一道数学题引发的血案
Winedt common shortcut key modify shortcut key latex compile button