当前位置:网站首页>漫画:寻找无序数组的第k大元素(修订版)
漫画:寻找无序数组的第k大元素(修订版)
2022-07-05 16:51:00 【小灰】
本文修改了两个细节:
1.方法二中,插入数组A的条件是遍历到的元素“大于”数组A的最小元素,而非”小于”。
2.方法三中,节点24从小顶堆下沉的时候,应该和节点17交换,而不是和节点20交换。
在此感谢大家的指正。
————— 第二天 —————
题目是什么意思呢?比如给定的无序数组如下:
如果 k=6,也就是要寻找第6大的元素,这个元素是哪一个呢?
显然,数组中第一大的元素是24,第二大的元素是20,第三大的元素是17 ...... 第6大的元素是9。
方法一:排序法
这是最容易想到的方法,先把无序数组从大到小进行排序,排序后的第k个元素,自然就是数组中的第k大元素。
方法二:插入法
维护一个长度为k的数组A的有序数组,用于存储已知的k个较大的元素。
接下来遍历原数组,每遍历到一个元素,和数组A中最小的元素相比较,如果小于等于数组A的最小元素,继续遍历;如果大于数组A的最小元素,则插入到数组A中,并把曾经的最小元素“挤出去”。
比如k=3,先把最左侧的7,5,15三个数有序放入数组A当中,代表当前最大的三个数。
这时候,遍历到3, 由于3<5,继续遍历。
接下来遍历到17,由于17>5,插入到数组A的合适位置,类似于插入排序,并把原先最小的元素5“挤出去”。
继续遍历原数组,一直遍历到数组的最后一个元素......
最终,数组A中存储的元素是24,20,17,代表着整个数组中最大的3个元素。此时数组A中的最小的元素17就是我们要寻找的第k大元素。
————————————
什么是二叉堆?不太了解的小伙伴可以先看看这一篇:漫画:什么是二叉堆?(修正版)
简而言之,二叉堆是一种特殊的完全二叉树,它包含大顶堆和小顶堆两种形式。
其中小顶堆的特点,是每一个父节点都小于等于自己的子节点。要解决这个算法题,我们可以利用小顶堆的特性。
方法三:小顶堆法
维护一个容量为k的小顶堆,堆中的k个节点代表着当前最大的k个元素,而堆顶显然是这k个元素中的最小值。
遍历原数组,每遍历一个元素,就和堆顶比较,如果当前元素小于等于堆顶,则继续遍历;如果元素大于堆顶,则把当前元素放在堆顶位置,并调整二叉堆(下沉操作)。
遍历结束后,堆顶就是数组的最大k个元素中的最小值,也就是第k大元素。
假设k=5,具体的执行步骤如下:
1.把数组的前k个元素构建成堆。
2.继续遍历数组,和堆顶比较,如果小于等于堆顶,则继续遍历;如果大于堆顶,则取代堆顶元素并调整堆。
遍历到元素2,由于 2<3,所以继续遍历。
遍历到元素20,由于 20>3,20取代堆顶位置,并调整堆。
遍历到元素24,由于 24>5,24取代堆顶位置,并调整堆。
以此类推,我们一个一个遍历元素,当遍历到最后一个元素8的时候,小顶堆的情况如下:
3.此时的堆顶,就是堆中的最小值,也就是数组中的第k大元素。
这个方法的时间复杂度是多少呢?
1.构建堆的时间复杂度是 O(k)
2.遍历剩余数组的时间复杂度是O(n-k)
3.每次调整堆的时间复杂度是 O(logk)
其中2和3是嵌套关系,1和2,3是并列关系,所以总的最坏时间复杂度是O((n-k)logk + k)。当k远小于n的情况下,也可以近似地认为是O(nlogk)。
这个方法的空间复杂度是多少呢?
刚才我们在详细步骤中把二叉堆单独拿出来演示,是为了便于理解。但如果允许改变原数组的话,我们可以把数组的前k个元素“原地交换”来构建成二叉堆,这样就免去了开辟额外的存储空间。
因此,方法的空间复杂度是O(1)。
/**
* 寻找第k大的元素
* @param array 待调整的堆
* @param k 第几大
*/
public static int findNumberK(int[] array, int k){
//1.用前k个元素构建小顶堆
buildHeap(array, k);
//2.继续遍历数组,和堆顶比较
for(int i=k; i<array.length;i++){
if(array[i] > array[0]){
array[0] = array[i];
downAdjust(array, 0, k);
}
}
//3.返回堆顶元素
return array[0];
}
/**
* 构建堆
* @param array 待调整的堆
* @param length 堆的有效大小
*/
private static void buildHeap(int[] array, int length) {
// 从最后一个非叶子节点开始,依次下沉调整
for (int i = (length-2)/2; i >= 0; i--) {
downAdjust(array, i, length);
}
}
/**
* 下沉调整
* @param array 待调整的堆
* @param index 要下沉的节点
* @param length 堆的有效大小
*/
private static void downAdjust(int[] array, int index, int length) {
// temp保存父节点值,用于最后的赋值
int temp = array[index];
int childIndex = 2 * index + 1;
while (childIndex < length) {
// 如果有右孩子,且右孩子小于左孩子的值,则定位到右孩子
if (childIndex + 1 < length && array[childIndex + 1] < array[childIndex]) {
childIndex++;
}
// 如果父节点小于任何一个孩子的值,直接跳出
if (temp <= array[childIndex])
break;
//无需真正交换,单向赋值即可
array[index] = array[childIndex];
index = childIndex;
childIndex = 2 * childIndex + 1;
}
array[index] = temp;
}
public static void main(String[] args) {
int[] array = new int[] {7,5,15,3,17,2,20,24,1,9,12,8};
System.out.println(findNumberK(array, 5));
}方法四:分治法
大家都了解快速排序,快速排序利用分治法,每一次把数组分成较大和较小的两部分。
我们在寻找第k大元素的时候,也可以利用这个思路,以某个元素A为基准,把大于于A的元素都交换到数组左边,小于A的元素都交换到数组右边。
比如我们选择以元素7作为基准,把数组分成了左侧较大,右侧较小的两个区域,交换结果如下:
包括元素7在内的较大元素有8个,但我们的k=5,显然较大元素的数目过多了。于是我们在较大元素的区域继续分治,这次以元素12位基准:
这样一来,包括元素12在内的较大元素有5个,正好和k相等。所以,基准元素12就是我们所求的。
这就是分治法的大体思想,这种方法的时间复杂度甚至优于小顶堆法,可以达到O(n)。有兴趣的小伙伴可以尝试用代码实现一下。
觉得本文有用,请给个好看,觉得特别有用,请转发给你的朋友们。
边栏推荐
- goto Statement
- 齐宣王典故
- 深入理解Redis内存淘汰策略
- 【性能测试】jmeter+Grafana+influxdb部署实战
- Database design in multi tenant mode
- Embedded-c Language-2
- Alpha conversion from gamma space to linner space under URP (II) -- multi alpha map superposition
- WR | Jufeng group of West Lake University revealed the impact of microplastics pollution on the flora and denitrification function of constructed wetlands
- 关于mysql中的json解析函数JSON_EXTRACT
- 干货!半监督预训练对话模型 SPACE
猜你喜欢

精准防疫有“利器”| 芯讯通助力数字哨兵护航复市
thinkphp模板的使用
![[Web attack and Defense] WAF detection technology map](/img/7c/60a25764950668ae454b2bc08fe57e.png)
[Web attack and Defense] WAF detection technology map

ECU简介
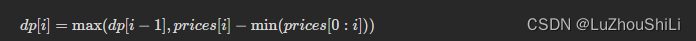
【剑指 Offer】63. 股票的最大利润
Tips for extracting JSON fields from MySQL
![[first lecture on robot coordinate system]](/img/3c/af056f0fe68b3244a3dc491ceb291d.png)
[first lecture on robot coordinate system]
Complete solution instance of Oracle shrink table space
In depth understanding of redis memory obsolescence strategy
Browser rendering principle and rearrangement and redrawing
随机推荐
The survey shows that the failure rate of traditional data security tools in the face of blackmail software attacks is as high as 60%
BigDecimal除法的精度问题
Three traversal methods of binary tree
Design of electronic clock based on 51 single chip microcomputer
Embedded-c language-6
基于Redis实现延时队列的优化方案小结
ECU简介
PHP talent recruitment system development source code recruitment website source code secondary development
Judge whether a string is a full letter sentence
Redis+caffeine two-level cache enables smooth access speed
mysql5.6解析JSON字符串方式(支持复杂的嵌套格式)
【jmeter】jmeter脚本高级写法:接口自动化脚本内全部为变量,参数(参数可jenkins配置),函数等实现完整业务流测试
IDC报告:腾讯云数据库稳居关系型数据库市场TOP 2!
Using C language to realize palindrome number
Embedded-c Language-4
[Jianzhi offer] 62 The last remaining number in the circle
Zhang Ping'an: accélérer l'innovation numérique dans le cloud et construire conjointement un écosystème industriel intelligent
Machine learning 02: model evaluation
【7.7直播预告】《SaaS云原生应用典型架构》大咖讲师教你轻松构建云原生SaaS化应用,难题一一击破,更有华为周边好礼等你领!
Understand the usage of functions and methods in go language