当前位置:网站首页>Interpretation of SIGMOD '22 hiengine paper
Interpretation of SIGMOD '22 hiengine paper
2022-07-04 18:24:00 【Hua Weiyun】
Reading guide
Huawei cloud database innovation Lab stay One work The paper 《HiEngine: How to Architect a Cloud-Native Memory-Optimized Database Engine》 Huawei self study Of 、 Of Memory centric cloud native memory database engine HiEngine.SIGMOD, namely Special Interest Group on Management Of Data International Conference on Data Management , The meeting was yes By the American Computer Association (ACM) Data Management Professional Committee (SIGMOD The organization's 、 Database domain Of Of most top International academic meeting .HiEngine It is cloud database innovation LAB stay Cloud native memory database One of the key technological achievements achieved .
Abstract
High performance memory database engine has become an essential basic component in many systems and Applications , However, most existing systems are designed based on local memory storage , It doesn't give full play to Cloud computing Environmental advantages . Most of the existing cloud native database systems follow the design centered on external storage .HiEngine Key features include :1) except Adopt the separation of storage and accounting Out of architecture , In the calculation Use cloud foundation Facility reliability memory service to achieve fast persistence and reliability ;2) Achieve the same performance as the main memory database engine ;3) as well as Backward compatible with existing cloud native database systems .
HiEngine HUAWEI GaussDB(for MySQL) Integrate , Bring the advantages of an in memory database engine to the cloud , And coexist with disk based engine .HiEngine Performance is higher than traditional storage centric solutions 7.5 times .
Research background
1. Memory-centric Computing architecture
Memory centric computing has become a research hotspot in academia and industry . persistence Memory provides DRAM level Of The performance and Flash Flash memory level Of Capacity , Based on persistent memory Pooled memory Research and application of Has gradually become an exploration new Direction . academic circle Study the prototype system Yes HydraDB、RAM Cloud、NAM-DB、Hotpot、DDC And Infiniswap, Industrial systems such as FaRM、SAP HANA、SRSS SCM、WSCs、 And DAOS etc. .
Same as when , Customers of in memory databases migrate applications to the cloud , Providers provide cloud native Memory optimized OLTP Solution Become a trend .
2. OLTP Database Ecology

Most of the existing cloud local database systems are disk resident databases , Follow a storage centric design , Such as Aurora、PolarDB、GaussDB(for be used for MySQL) etc. . They have the following characteristics : Page block based IO、, Page oriented layout and buffer pool . Besides
Specially , They have buffer pools that the in memory database does not have , This directly affects how to build an engine in the cloud platform and make full use of the hardware performance of memory devices . At present , Most in memory databases are designed based on local deployment solutions , You can't work directly in the cloud . Although some memory databases are separated from computing ( Such as NAM-DB) It can provide cloud native features , But their access latency across the network is expensive .
.png)
3. Huawei Cloud Foundation facilities
Huawei cloud storage infrastructure services have the following characteristics :
.png)
- Hardware trends and challenges :1) Deposit is separate Introduce persistent memory into the architecture , Especially on the calculation side Persistent memory can provide high-speed transaction log cache And so on , But it's with Compute the Stateless Characteristics contradict .2) be based on ARM More nucleus Handle The device has Better cost performance and ideal energy consumption , however also bring Cross-NUMA Multi core expansion challenge .
- SRSS: As Huawei cloud Next generation distributed storage services , it Use RDMA Based on modern SSD/NVM Hardware above , use Log structure type Additional storage .
- SRSS The necessary persistent memory primitives are provided in the cloud .SRSS Support memory semantics and persistent storage on the computing side , customized mmapMMAP kernel The driver API Support persistence locally or remotely Storage tier consistency The read data ,SRSS Through memory mapping except open 、/ close 、/ Additional 、/ Read etc. Interface Outside , also Provide Memory semantics operation . The data is on the calculation side and the storage side Three copy storage , use have Low latency storage network . This allows computing nodes It can be on the calculation side Local Persistence and storage side remote Persistence , like Between storage tiers On the critical path No, Back and forth Network overhead .
HiEngine framework
This paper presents a cloud native memory optimized memory database engine HiEngine To address these challenges .HiEngine Architectural features include :
1) Introduce persistent state into the computing layer , To support fast persistence and low latency transactions .
2) Logs are data .
3) At the computing level SRSS Use persistent memory ( Such as Intel Optane Memory ) Store replica logs synchronously in three compute nodes , At the same time, asynchronously persist to remote storage .
4)HiEngine The system has three-layer physical structure and three-layer logical structure , The logical log layer and the computing layer are located in the same physical location .
.png)
1. Log centric Log-centric MVCC Storage engine overview
.png)
HiEngine Around “ Logs are databases ” The idea of , And some key technologies are used, such as lock free index 、MVCC Transaction model 、tuple-level Tuple level memory layout . It USES SRSS Realize data persistence and rapid recovery .HiEngine adopt rRowmap Data access ,rowmap It is HiEngine The core data structure of , Support MVCC、 Efficient checkpointing and parallel recovery .
2. Tuple-level Memory layout
HiEngine Use MVCC Transaction model , This fully excavates SRSS Performance and functional features . At the memory layout level , It uses lock-free Of ARTree Indexes 、 Use Row Map To map rowid That's ok ID To the specific data version version data .
.png)
Tuple-level Memory layout features include :
1) A version contains many key fields , Such as [tmin, tmax, nextver, loffset…] Field ;
2)Index The leaf node of is a rowid That's ok ID;
3) The key of the secondary index is defined by the user and the current row IDrowid form ;
4) The version chain is based on Epoch Space management mechanism and based on Session Controlled Non-blocking Garbage collection strategy of .
3. Transaction model
at present HiEngine Provide snapshot isolation level . When the transaction begins , It is assigned a read CSN And a globally unique TID, And submit tminTMIN and TMAXtmax In the field TID Replace with CSN.HiEngine Two timestamp authorization methods are proposed . The timestamp allocation delay of the logical clock is 40 Microsecond , The delay of the global clock without atomic clock is 20 Microsecond .
.png)
In distributed database ,Global Clock It is the best choice for high-performance timestamp timing and high-performance expansion .
4. PIA/RowMap
HiEngine Organize data records in the form of logs , No, “ page ” The concept of .PIA Record the version line ID Map to record address .
.png)
PIA There are the following benefits :
- The row update operation will not change the internal structure of the index
- Secondary index “ key ”=“ User defined key + RID”
- Checkpoints become lightweight , Because you only need persistence PIA Not real data
- Recovery will only rebuild PIA, Instead of reading tuple versions
5. Highly reliable and scalable Redo-Only Logging
HiEngine in ,WAL There are two purposes : Persistence assurance and 、 Data copy implementation .WAL It is synchronously persisted to the near end of the computing side SRSS SCM pool pool in , Then it is distributed asynchronously to the storage side SRSS PLOG.
SRSS adopt PLOG Provides an additional abstraction and segment structure .HiEngine Use distributed logging on the computing side , Once the transaction log record is persisted to the persistent memory of the computing side , The transaction will be committed . Logs are batched and asynchronously refreshed to the storage tier .
.png)
PLOGPLog In physical structure , Organize by segment , Then map to Plog. Each thread maintains an open PLOGPLog, Segments are dynamically allocated and released on demand . Each segment consists of PLOG Plog ID and PLOGPlog To identify .
HiEngine Distributed logging, It uses ::
- Add write and based on mmapMMAP Of read
- The updated version contains the complete content of a record
- Use SRSS The addition of Interface writes log records to segment / PLOGPlog
- Data are successfully 3、 ... and copy Persist to the computing side Persistent memory Submit after Business
6. Dataless Checkpointing and parallel recovery
To accelerate recovery ,HiEngine Run checkpoints in the background . Checkpoints become very lightweight , Just persist PIA.
Recovery is divided into loading stage and replay stage : 1) once PIA Setup completed , The recovery is complete ;2) Subsequent visits will be made through mmapMMAP Bring the data version into main memory . We also designed a parallel recovery algorithm :
1). Multiple replay threads scan logs in turn ( One per thread )
2). If the logging operation is an insert or update operation , Then the corresponding PIA The entry is updated to the offset in the log
3). Only when PIA When an entry points to an old record version , The replay thread will overwrite with the new record address PIA entry
meanwhile ,HiEngine Perform log merging regularly to do log garbage collection . Merge thread gets the current minimum read LSN Snapshot , The snapshot is stored locally as truncLSN, For partial consolidation . Complete consolidation requires deleting all versions and records of the table , In order to gather data into new storage space for repair loffset. Asynchronously after completing log merging ,HiEngine Will repair asynchronously PIA Medium loffset.

7. Index persistence and checkpoints
stay HiEngine in , Changes to the index tree are not immediately persistent . The checkpoint of an index tree is similar to a log structure merge tree . However, there is read amplification . Fortunately , Read amplification exists .

The index has the following features including :1)1 Main in memory R/W Trees + Persistent storage R/O The forest ;2) be based on AR-Tree Of lock-free Tree index ;3) adopt mmapMMAP Read the index of persistent storage ;4) The trees in the forest can be of different kinds ( It means you can have different kinds of trees ( For example B+ -tTree);5) Index merging : Merge multiple trees into one .
Deployment way
.png)
HiEngine Two deployment modes are proposed :
1. Vertical integration :HiEngine And GaussDB Existing InnoDB Engine coexistence ( in the light of MySQL), stay CREATE TABLE Use in statement WITH ENGINE=HiEngine Parameters , Inquire about ( Compiled or interpreted ) Will be routed to the corresponding storage engine for execution .
2. Horizontal integration . Put it in database The front of the table is used as a transparent ACID cache , Part or all of it as the front of the table ACID cache .
This article focuses on the deployment of vertical integration ,HiEngine HUAWEI GaussDB(for MySQL) Integrated into a single engine . This paper mainly studies the vertical integration mode .HiEngine And GaussDB Existing InnoDB Engine coexistence ( in the light of MySQL). Users only need to be in CREATE TABLE The statement declares that the engine type query will be routed to the corresponding storage engine .
System evaluation
This article focuses on the deployment of vertical integration ,HiEngine HUAWEI GaussDB(for MySQL) Integrated into a single engine .
The two engines share the same SQL layer , Besides HiEngine Using code generation technology . We use Sysbench And standards TPC-C Benchmark to compare HiEngine And three other industrial systems . All evaluations were conducted in two environments , Single server and cloud SRSS.
.png)
HiEngine The performance on both platforms is significantly better than DBMS-M. HiEngine Single server performance is up to 6500 ten thousand tpmC.
.png)
.png)
The end-to-end performance under Compilation execution is > 50%. We evaluate the target by setting the memory allocation policy and workload partition armARM The optimization of the . In all cases ,HiEngine The performance of the storage engine is better than DBMS-M Higher than 60%. Through to ARM On the platform TPC-C Model analysis , Span Socket Every increase in remote access 10%, Performance degradation 5%. The optimized RTO Performance improved 10 times .
.png)
summary
This paper proposes HiEngine, This is a cloud native memory optimized memory database engine . It uses modern cloud infrastructure and fast persistent memory on the computing side , And bring the advantages of the main memory database engine to the cloud , And coexist with disk based engine . Besides , Its performance is comparable to that of the local memory database engine .
1. modern Cloud Foundation Facilities have been developing rapidly , Especially in Modern hardware Technological development continues to upgrade . The new hardware includes Multi core processors are especially based on ARM The platform of 、 Big Capacity main memory and persistence SCM、 And RDMA The Internet etc. .
2. Existing cloud native Most database engines are storage centric , this Make the new The potential of hardware In the cloud native memory database To a large extent, it cannot be developed , At the same time, the cloud gives memory The database engine brings Some unique Challenge .
3. HiEngine Proposed a cloud native Memory optimized database engine , Its features include :1) Separate storage from calculation A high performance In-memory database Present to users on the cloud ;2) Adopt Huawei's high reliable Shared cloud storage services , Support log centric storage and computing side high performance persistent Sexual memory ;3) Optimization is based on ARM The multi-core processor of ;4) Maintain backward compatibility between memory centric and storage centric engines 、 Can be deployed as a single engine or in front of another engine ACID cache ;5) Compared with the previous system , Provide up to 7 The performance of The Times .
4. HiEngine Bridging the academic prototype Between the system and the cloud production system gap .
5. HiEngine It is the next generation of Huawei cloud Generate distributed memory The key to database engine .
边栏推荐
猜你喜欢

78 year old professor Huake impacts the IPO, and Fengnian capital is expected to reap dozens of times the return
![[HCIA continuous update] WAN technology](/img/31/8e9ed888d22b15eda5ddcda9b8869b.png)
[HCIA continuous update] WAN technology

Li Kou brush question diary /day7/6.30
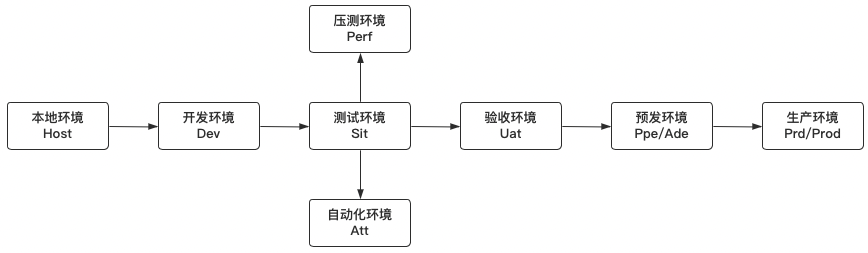
被忽视的问题:测试环境配置管理
Li Kou brush question diary /day6/6.28
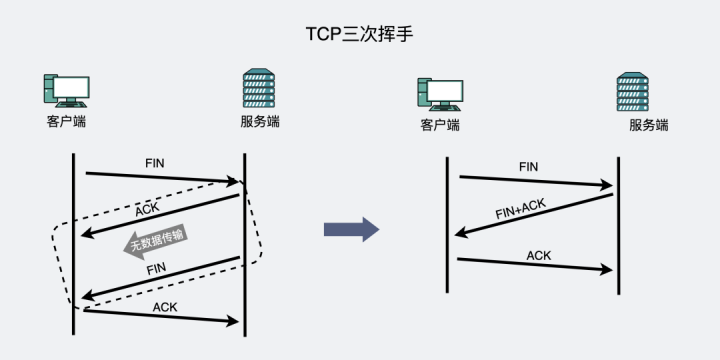
TCP waves twice, have you seen it? What about four handshakes?

How to improve development quality
力扣刷題日記/day6/6.28
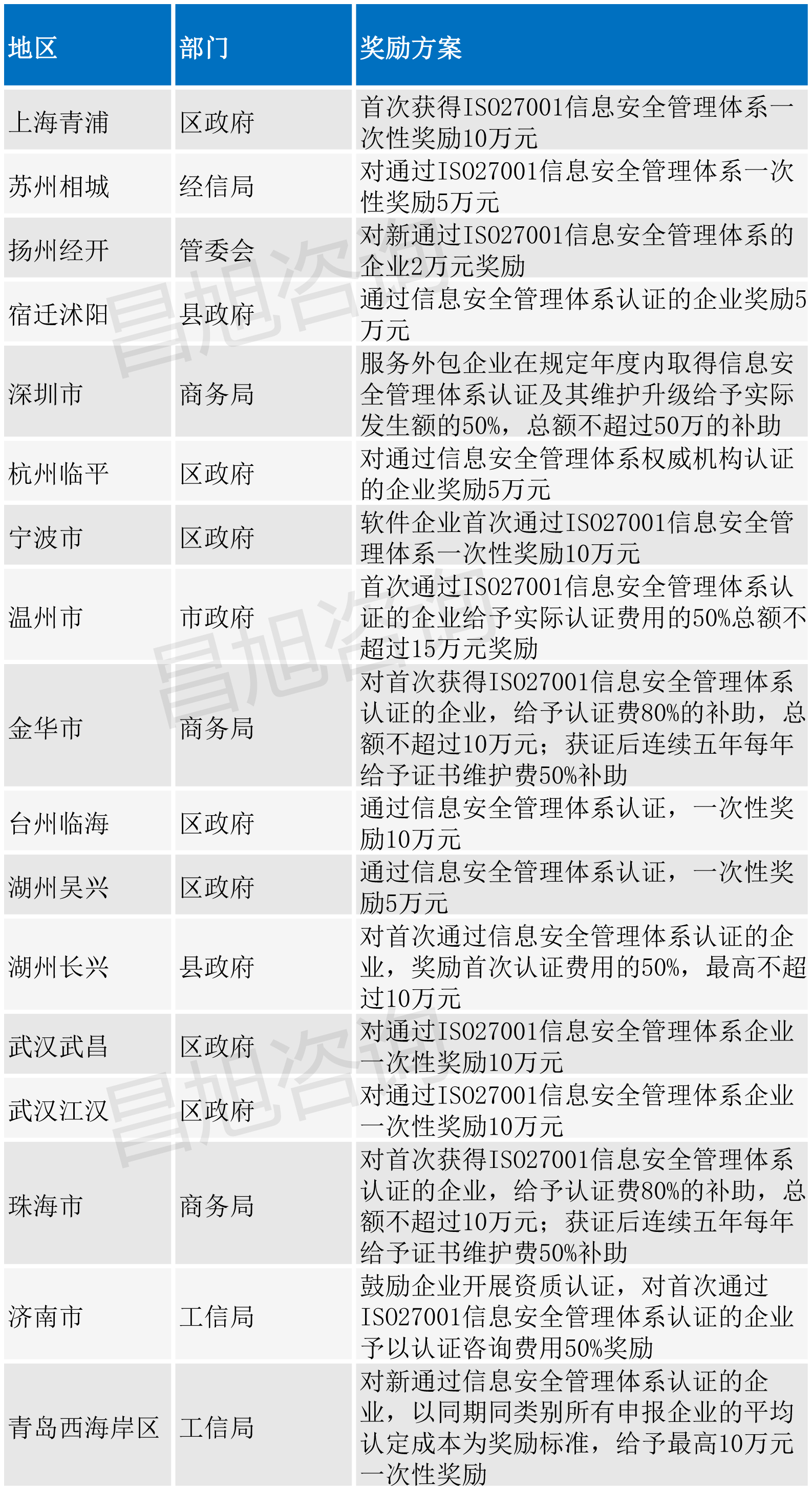
ISO27001 certification process and 2022 subsidy policy summary

要上市的威马,依然给不了百度信心
随机推荐
Win32 API access route encrypted web pages
Li Kou brush question diary /day6/6.28
Numpy 的仿制 2
项目通用环境使用说明
曾经的“彩电大王”,退市前卖猪肉
估值900亿,超级芯片IPO来了
被忽视的问题:测试环境配置管理
[cloud native] what is the "grid" of service grid?
Stars open stores, return, return, return
[daily question] 871 Minimum refueling times
The block:usdd has strong growth momentum
android使用SQLiteOpenHelper闪退
线上MySQL的自增id用尽怎么办?
怎么开户才是安全的,
Introduction of time related knowledge in kernel
S5PV210芯片I2C适配器驱动分析(i2c-s3c2410.c)
上市公司改名,科学还是玄学?
Reptile elementary learning
Blue bridge: sympodial plant
fopen、fread、fwrite、fseek 的文件处理示例