当前位置:网站首页>MySQL【视图】
MySQL【视图】
2022-08-03 13:37:00 【桜キャンドル淵】
目录
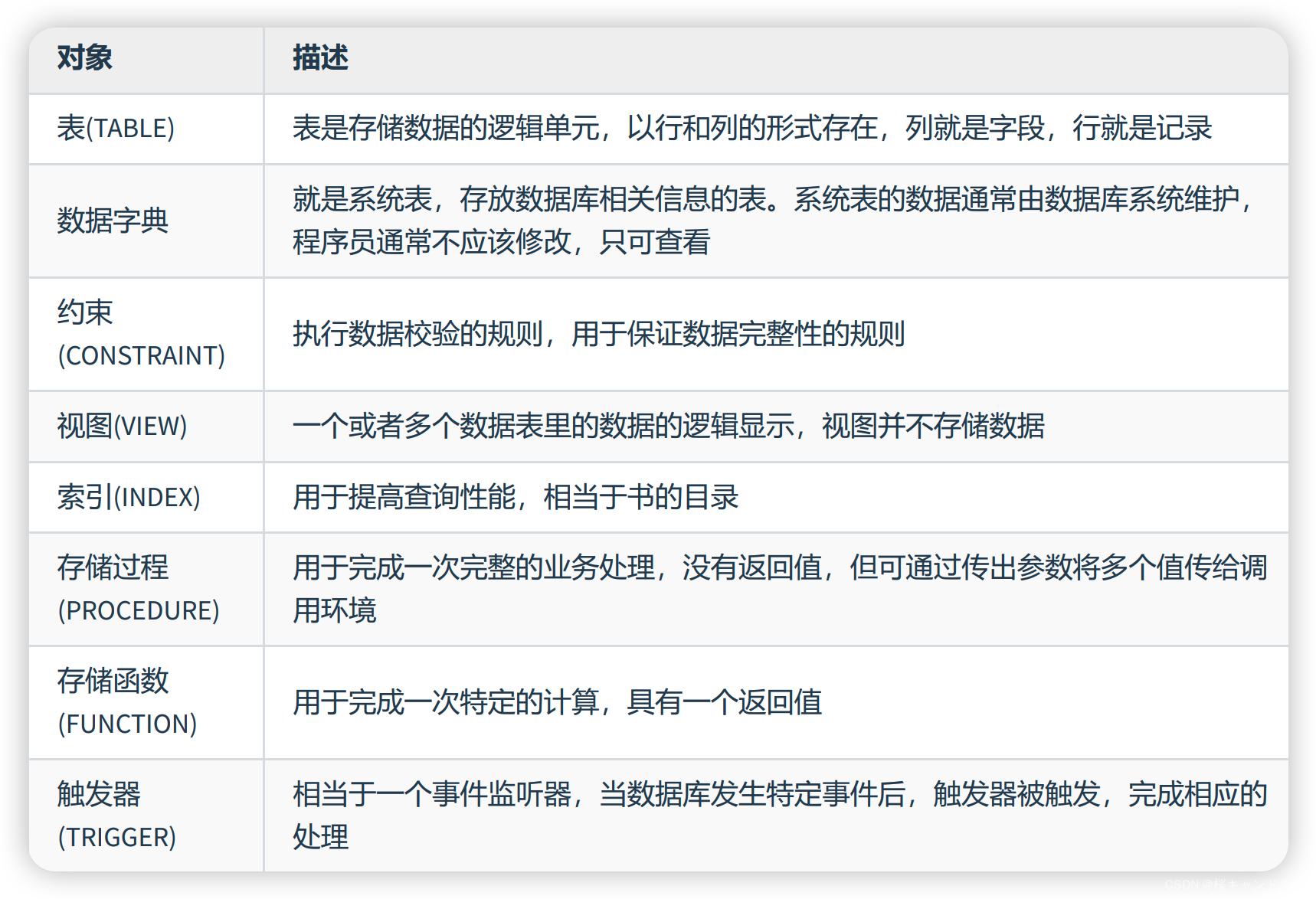
一、常见的数据库对象
二、视图概述
视图一方面可以帮我们使用表的一部分而不是所有的表,另一方面也可以针对不同的用户制定不同的查询视图。比如,针对一个公司的销售人员,我们只想给他看部分数据,而某些特殊的数据,比如采购的价格,则不会提供给他。再比如,人员薪酬是个敏感的字段,那么只给某个级别以上的人员开放,其他人的查询视图中则不提供这个字段。
视图是一种 虚拟表 ,本身是 不具有数据 的,占用很少的内存空间,它是 SQL 中的一个重要概念。
视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。
向视图提供数据内容为SELECT语句,可以将视图理解为存储起来的SELECT语句
在数据库中,视图不会保存数据,数据真正保存在数据表中。当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然
视图,是向用户提供基表数据的另一种表现形式。通常情况下,小型项目的数据库可以不使用视图,但是在大型项目中,以及数据表比较复杂的情况下,视图的价值就凸显出来了,它可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。理解和使用起来都非常方便。
三、创建视图
针对于单表
#针对于单表
#情况1:视图中的字段与基表的字段有对应关系
CREATE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary
FROM emps;
SELECT * FROM vu_emp1;
其别名
以下两种方式都可以给我们的视图中的字段起别名
#确定视图中字段名的方式1:
CREATE VIEW vu_emp2
AS
SELECT employee_id emp_id,last_name lname,salary #查询语句中字段的别名会作为视图中字段的名称出现
FROM emps
WHERE salary > 8000;
SELECT * FROM vu_emp2;
#确定视图中字段名的方式2:
CREATE VIEW vu_emp3(emp_id,NAME,monthly_sal) #小括号内字段个数与SELECT中字段个数相同
AS
SELECT employee_id,last_name,salary
FROM emps
WHERE salary > 8000;
SELECT * FROM vu_emp3;
#情况2:视图中的字段在基表中可能没有对应的字段
CREATE VIEW vu_emp_sal
AS
SELECT department_id,AVG(salary) avg_sal
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
SELECT * FROM vu_emp_sal;
针对于多表
# 针对于多表
CREATE VIEW vu_emp_dept
AS
SELECT e.employee_id,e.department_id,d.department_name
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept;
利用视图对数据进行格式化
#利用视图对数据进行格式化
CREATE VIEW vu_emp_dept1
AS
SELECT CONCAT(e.last_name,'(',d.department_name,')') emp_info
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept1;
基于视图创建视图
# 基于视图创建视图
CREATE VIEW vu_emp4
AS
SELECT employee_id,last_name
FROM vu_emp1;
SELECT * FROM vu_emp4; 
四、查看视图
查看数据库的表对象、视图对象
# 查看视图
# 语法1:查看数据库的表对象、视图对象
SHOW TABLES;可以看到在这个测试结果中,前两个是我们之前创建的表,后面的七个是我们的视图

查看视图的结构
#语法2:查看视图的结构
DESCRIBE vu_emp1;
查看视图的属性信息
#语法3:查看视图的属性信息
SHOW TABLE STATUS LIKE 'vu_emp1';
查看视图的详细定义信息
#语法4:查看视图的详细定义信息
SHOW CREATE VIEW vu_emp1;
五、更新视图中的数据
这里我们一开始的视图和表中的内容都是相同的。
# 一般情况,可以更新视图的数据
SELECT * FROM vu_emp1;
# 一般情况,可以更新视图的数据
SELECT * FROM vu_emp1;
这时我们修改一下部分数据
#更新视图的数据,会导致基表中数据的修改
UPDATE vu_emp1
SET salary = 20000
WHERE employee_id = 101;我们可以发现修改视图中的数据确实会影响我们表中的数据

#同理,更新表中的数据,也会导致视图中的数据的修改
UPDATE emps
SET salary = 10000
WHERE employee_id = 101;
我们发现修改表中的数据,我们的视图中的数据同样也会发生变化

#删除视图中的数据,也会导致表中的数据的删除
DELETE FROM vu_emp1
WHERE employee_id = 101;
SELECT employee_id,last_name,salary
FROM emps
WHERE employee_id = 101;
不能更新视图中的数据
SELECT * FROM vu_emp_sal;
这里的视图vu_emp_sal中的avg_sal在我们原来的基表中是不存在的,是通过聚合函数计算出来的,不能被更新。
#更新失败
UPDATE vu_emp_sal
SET avg_sal = 5000
WHERE department_id = 30;
#删除失败
DELETE FROM vu_emp_sal
WHERE department_id = 30;
要使视图可更新,视图中的行和底层基本表中的行之间必须存在 一对一 的关系。另外当视图定义出现如下情况时,视图不支持更新操作:
①在定义视图的时候指定了“ALGORITHM = TEMPTABLE”,视图将不支持INSERT和DELETE操作;
② 视图中不包含基表中所有被定义为非空又未指定默认值的列,视图将不支持INSERT操作;
③在定义视图的SELECT语句中使用了 JOIN联合查询 ,视图将不支持INSERT和DELETE操作;
④ 在定义视图的SELECT语句后的字段列表中使用了 数学表达式 或 子查询 ,视图将不支持INSERT,也不支持UPDATE使用了数学表达式、子查询的字段值;
⑤在定义视图的SELECT语句后的字段列表中使用 DISTINCT 、 聚合函数 、 GROUP BY 、 HAVING 、UNION 等,视图将不支持INSERT、UPDATE、DELETE;
⑥在定义视图的SELECT语句中包含了子查询,而子查询中引用了FROM后面的表,视图将不支持INSERT、UPDATE、DELETE;
⑦视图定义基于一个 不可更新视图 ;
⑧常量视图。
六、修改删除视图
修改视图
DESC vu_emp1;
#方式1
#如果没有就创建,如果有了就修改
CREATE OR REPLACE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email
FROM emps
WHERE salary > 7000;
SELECT * FROM dbtest14.vu_emp1;我们成功地将原来salary>8000的视图结果修改为salary>7000。

#方式2
ALTER VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email,hire_date
FROM emps;
SELECT * FROM dbtest14.vu_emp1;
删除视图
#查看所有的视图
SHOW TABLES;
#删除视图
DROP VIEW vu_emp4;
SHOW TABLES;
#如果存在就删掉
DROP VIEW IF EXISTS vu_emp2,vu_emp3;
SHOW TABLES;
七、总结
视图优点
1. 操作简单
将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简化了开发人员对数据库的操作。
2. 减少数据冗余
视图跟实际数据表不一样,它存储的是查询语句。所以,在使用的时候,我们要通过定义视图的查询语句来获取结果集。而视图本身不存储数据,不占用数据存储的资源,减少了数据冗余。
3. 数据安全
MySQL将用户对数据的 访问限制 在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。用户不必直接查询或操作数据表。这也可以理解为视图具有 隔离性 。视图相当于在用户和实际的数据表之间加了一层虚拟表。4. 适应灵活多变的需求 当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较大,可以使用视图来减少改动的工作量。这种方式在实际工作中使用得比较多
5. 能够分解复杂的查询逻辑 数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。
视图不足
如果我们在实际数据表的基础上创建了视图,那么,如果实际数据表的结构变更了,我们就需要及时对相关的视图进行相应的维护。特别是嵌套的视图(就是在视图的基础上创建视图),维护会变得比较复杂, 可读性不好 ,容易变成系统的潜在隐患。因为创建视图的 SQL 查询可能会对字段重命名,也可能包含复杂的逻辑,这些都会增加维护的成本。
边栏推荐
- svn安装包和客户端
- ideaIU-2020.1下载
- 中英文说明书丨Abbkine AbFluor 488-鬼笔环肽
- 一文详解什么是软件部署
- Golang GMP 原理
- MySQL数据表操作实战
- W11的右键如何改成和W10一样?(一行命令即可解决!)
- HCIP Fifteenth Day Notes (Three-layer Architecture of Enterprise Network, VLAN and VLAN Configuration)
- Golang 通道 channel
- PyTorch builds a neural network to predict temperature (dataset comparison, CPU vs GPU comparison)
猜你喜欢

力扣刷题 每日两题(一)
Nanoprobes金脂质偶联物的相关应用
STL——vector
【OpenCV】 级联分类器训练模型

scala安装包
使用Typora+EasyBlogImageForTypora写博客,无图床快速上传图片
数字孪生的4个最佳实践

typedef关键字的用法
Relia Tech活性VEGFR重组蛋白丨小鼠 VEGF120实例展示
![[Practical skills] APP video tutorial for updating APP in CANFD, I2C, SPI and serial port mode of single-chip bootloader (2022-08-01)](/img/df/69dc3cb061cd4544d1aae5a88c7b00.png)
[Practical skills] APP video tutorial for updating APP in CANFD, I2C, SPI and serial port mode of single-chip bootloader (2022-08-01)
随机推荐
第07章 InnoDB数据存储结构【2.索引及调优篇】【MySQL高级】
如何在 UE4 中制作一扇自动开启的大门
如何让history历史记录前带时间戳
Golang strings
ITSM软件与工单系统的区别是什么?
[OpenCV] Cascade classifier training model
【二叉树】从二叉树一个节点到另一个节点每一步的方向
Golang sync.WaitGroup
软件测试考证:ISTQB、软件评测师
TensorFlow离线安装包
安全狗《云原生安全威胁分析报告》首次提出双检测模型
An animation basic element movie clip effect
将移位距离和假设外推到非二值化问题
MySQL数据表操作实战
VLAN experiment
HCIP第十五天笔记(企业网的三层架构、VLAN以及VLAN 的配置)
TiFlash 计算层概览
【框架】idea找不到xxx依赖项怎么办
The maximum number of sliding window
Basic principle of the bulk of the animation and shape the An animation tip point