当前位置:网站首页>Voice assistant -- Qu -- semantic role annotation and its application
Voice assistant -- Qu -- semantic role annotation and its application
2022-06-12 07:34:00 【Turned_ MZ】
In this chapter, we will talk about semantic role tagging (Semantic Role Labeling (SRL)) And its application in voice assistant , It is mainly divided into 4 part : What is semantic role annotation 、 Why do we need semantic role annotation 、 How to achieve 、 Voice assistant applications
1、 What is semantic role annotation
Semantic Role Labeling (Semantic Role Labeling (SRL)) It is also called chunk analysis (query chunking), It is a shallow semantic analysis technology . Give a sentence , SRL The task of is to find out the corresponding semantic role components of predicates in sentences , Including core semantic roles ( As an agent 、 Patient, etc ) And subordinate semantic roles ( Such as location 、 Time 、 The way 、 Reasons, etc ). for instance : The yellow part is the result of semantic role annotation ,A0 For the practical ,A1 For the patient ,ARGM-ADV Is an adverbial .
The yellow part is the result of semantic role annotation ,A0 For the practical ,A1 For the patient ,ARGM-ADV Is an adverbial .
2、 Why do we need semantic role annotation
You can see from above , Through semantic role annotation , We can get the core part of a sentence , These core parts can represent the semantics of the sentence , Using this feature, we can realize semantic understanding . In previous chapters , We talk about the method of using intention slot model to identify semantics , But some types of scripts are not suitable for this method , such as :
- Time + Content : This kind of script needs to judge whether it needs to be called back to the schedule according to the type of content , such as : Tomorrow, 8 Hold a meeting (“ The meeting ” It's a verb , You can call back to the schedule reminder ), Tomorrow, 8 Point Weather (“ The weather ” Non verb , This should not be part of the schedule ). If this kind of script uses the intention slot model, it is easy to recall by mistake .
- action + Content : This kind of script needs to judge the intention according to the category of content , such as : Open blue and white porcelain ( Should play music ), Open the WeChat ( Should belong to open app), If the intention slot model is used in this kind of scripts, it is difficult to accurately identify the intention , because “ Content ” Knowledge is strongly related , At this point, we can use semantic role annotation to identify this kind of script , Then the content type is determined by combining the knowledge map to further determine the intention .
The above two types of scripts , All of them are strongly related to knowledge , It needs to be combined with the knowledge map to further determine the semantics .
meanwhile , Semantic role tagging is much more efficient than the intention slot model for some scenes , such as “ Set up ” This scene , We know that in mobile phones “ Set up ” This app Contains many operations , Want to control the operation , such as : Turn on the flashlight , Turn on do not disturb mode , Turn the volume to 25. There are hundreds of these operations , Imagine if you want to identify hundreds of intentions through an intention slot model or classification model , The difficulty is very high . In this case, semantic role annotation can be used , Identify “ action ”、“ Entity ”, combining “ Mobile phone knowledge map ” According to different combinations of actions and entities , Identify different semantics . Next, we will talk about the specific implementation here .
3、 How to implement semantic role annotation
So how to get the results of semantic role annotation ? Open source tools can be used “LTP”, Use it “ Semantic Role Labeling ” Result , Or use it “ dependency parsing ” The result of secondary processing , To fit your scene .
Of course, we can also train the model ourselves , This model is similar to “NER” The model is very similar , We can use BILSTM-CRF, perhaps Transformer, perhaps Bert, We don't need to expand here , The key is to label the data .
4、 Application examples in voice assistant
Here we take “ Set up ” Take the scenario as an example , The scene features are also mentioned above , Mainly for : The sentence is short 、 Many intentions 、 There are many ways to express . such as :” Turn on the flashlight “,” The room is too dark , Turn on the flashlight for me “,” Turn on the flash “, They all have the same intention .

Pictured above , For user input query, Using semantic role tagging to obtain sentence components , such as ” Turn on the flashlight “, Split into ” open ( action )“ and ” The flash ( Entity )“, And then to the action 、 Entities are disambiguated and normalized , Finally, combined with the functional map , Get the intention of this sentence .
边栏推荐
- Vs 2019 MFC connects and accesses access database class library encapsulation through ace engine
- Detailed explanation of coordinate tracking of TF2 operation in ROS (example + code)
- Summary of machine learning + pattern recognition learning (II) -- perceptron and neural network
- Keil installation of C language development tool for 51 single chip microcomputer
- In depth learning - overview of image classification related models
- VS2019 MFC IP Address Control 控件继承CIPAddressCtrl类重绘
- Golang quickly generates model and queryset of database tables
- [college entrance examination] prospective college students look at it, choose the direction and future, and grasp it by themselves
- VS2019 MFC IP Address Control 控件繼承CIPAddressCtrl類重繪
- 2022R2移动式压力容器充装试题模拟考试平台操作
猜你喜欢

AI狂想|来这场大会,一起盘盘 AI 的新工具!

Static coordinate transformation in ROS (analysis + example)

Introduction to JDE object management platform and use of from

Decryption game of private protocol: from secret text to plaintext

Pyhon的第四天

Fcpx plug-in: simple line outgoing text title introduction animation call outs with photo placeholders for fcpx

MySQL索引(一篇文章轻松搞定)

2022年G3锅炉水处理复训题库及答案
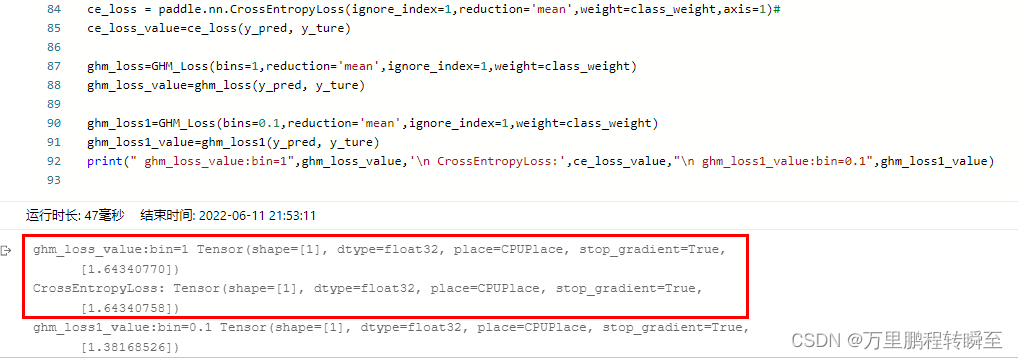
Paddepaddl 28 supports the implementation of GHM loss, a gradient balancing mechanism for arbitrary dimensional data (supports ignore\u index, class\u weight, back propagation training, and multi clas

右击文件转圈卡住、刷新、白屏、闪退、桌面崩溃的通用解决方法
随机推荐
VS 2019 MFC 通过ACE引擎连接并访问Access数据库类库封装
MySQL索引(一篇文章轻松搞定)
LED lighting experiment with simulation software proteus
There is no solid line connection between many devices in Proteus circuit simulation design diagram. How are they realized?
RT thread studio learning (I) new project
Class as a non type template parameter of the template
Interview computer network - transport layer
Set up a remote Jupiter notebook
2022 simulated test platform operation of hoisting machinery command test questions
Demonstrate "topic communication, action communication, service communication and parameter server" with a small turtle case
@Datetimeformat @jsonformat differences
Day 6 of pyhon
The function of C language string Terminator
TypeScript基础知识全集
2022r2 mobile pressure vessel filling test question simulation test platform operation
[wax chain tour] release a free and open source alien worlds script TLM
linux下怎么停止mysql服务
Explain in detail the use of dynamic parameter adjustment and topic communication in ROS (principle + code + example)
Node, topic, parameter renaming and global, relative and private namespaces in ROS (example + code)
Unity uses shaders to highlight the edges of ugu I pictures