当前位置:网站首页>Raki's notes on reading paper: memory replace with data compression for continuous learning
Raki's notes on reading paper: memory replace with data compression for continuous learning
2022-06-11 19:22:00 【Sleepy Raki】
Abstract & Introduction & Related Work
- Research tasks
Continuous learning - Existing methods and related work
- Facing the challenge
- The existing work is mainly based on a small memory buffer containing a small number of original data , This does not fully describe the old data distribution
- Existing work often requires training additional parameters or distilling old features
- Innovative ideas
- In this work , We propose memory replay with data compression , To reduce the storage cost of old training samples , This increases the number of buffers they can store in memory
- We propose a process based on the decisive point (DPPs) New method of , To effectively determine the appropriate compression quality of the currently arrived training samples , thus , Use a naive data compression algorithm with appropriate selection quality , More compressed data can be saved in limited storage space , So as to greatly improve the recent strong baseline
- The experimental conclusion
A lot of experiments show that , Use a simple data compression algorithm , And properly select the quality , More compressed data can be saved in the limited storage space , So as to greatly improve the memory playback
And DNN Medium " artificial " Memory playback is different , An important feature of biological memory is to encode and replay old experiences in a highly compressed form to overcome catastrophic forgetting

Data compression
Data compression aims to improve the storage efficiency of files , Including lossless compression and lossy compression . Lossless compression needs to perfectly reconstruct the original data from the compressed data , This limits its compression ratio (Shannon, 1948). by comparison , Lossy compression can achieve higher compression rate by reducing the original data , So it is widely used in practical applications . Typical handmade methods include JPEG( or JPG)(Wallace,1992), It is the most commonly used lossy compression algorithm (Mentzer wait forsomeone ,2020),WebP(Lian & Shilei,2012) and JPEG2000(Rabbani,2002). On the other hand , Neural compression methods usually rely on optimizing Shannon rate - Distortion tradeoffs , adopt RNNs(Toderici wait forsomeone ,2015;2017)、 Automatic encoder (Agustsson wait forsomeone ,2017) and GANs(Mentzer wait forsomeone ,2020) To achieve
METHOD
MEMORY REPLAY WITH DATA COMPRESSION
If the compression ratio is too high , It will affect the training effect , Intuitively speaking , This leads to a trade-off between quality and quantity : If storage space is limited , Reduce the quality of data compression q Will increase the amount of compressed data that can be stored in the memory buffer N q m b N_q^{mb} Nqmb, vice versa
ad locum , We use JPEG(Wallace, 1992) Compress the image to evaluate the proposed idea ,JPEG Is a simple but commonly used lossy compression algorithm .JPEG Can save quality in [1, 100] Images in range , Reducing the quality will result in smaller file sizes . The use is equivalent to each type 20 A memory buffer for the original image (Hou wait forsomeone ,2019 year ), We use a representative memory playback method , Such as LUCIR(Hou wait forsomeone ,2019 year ) and PODNet(Douillard wait forsomeone ,2020 year ) Yes JPEG Quality grid search . Pictured 2 Shown , The memory playback of compressed data with appropriate quality can greatly exceed the performance of the original data . However , Whether the mass is too large or too small , Will affect performance . especially , The quality of achieving optimal performance varies depending on the memory playback method . The methods of memory playback are different , But the segmentation is consistent for different number of incremental stages 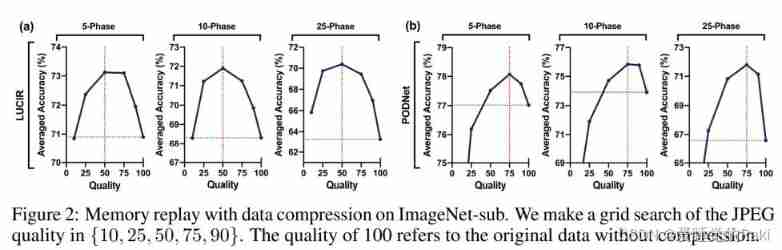
QUALITY-QUANTITY TRADE-OFF
q The smaller it is ( The higher the compression ) The larger the data set , That is to say, choose the right one q To reproduce the memory
use LUCIR Study 5 Stage ImageNet-sub after , Original subset ( Light dots ) And its compressed subset ( Dark dot ) Of t-SNE Visualization features . From left to right , The number from 37,85 Add to 200, and JPEG The quality of 90,50 Reduced to 10. We mapped the five categories in the latest task , And marked with different colors . The crossing area is distributed outside 
Choose the right one q To optimize the following maximum likelihood 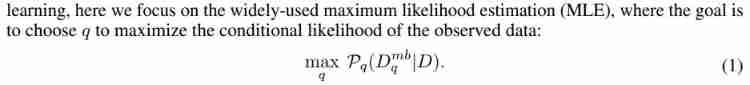
D q m b D_q^{mb} Dqmb The construction of can basically be seen as a sampling problem , We apply deterministic point processes (DPPs) To establish conditional possibilities ,DPPs Not just a beautiful probabilistic sampling model , It can describe the probability of each possible subset by determinant , It can also provide a geometric interpretation of probability by the capacity of all elements in the subset

Due to the high complexity , It is difficult to optimize directly 
Change to optimize M q ∗ M_q^* Mq∗


VALIDATE OUR METHOD WITH GRID SEARCH RESULTS

Now we use the grid search results to verify the quality determined by our method , among LUCIR and PODNet stay JPEG The quality is 50 and 75 Of ImageNet-sub We've got the best performance 
Because they are satisfying ∣ R q − 1 ∣ < ϵ |R_q - 1| < \epsilon ∣Rq−1∣<ϵ Minimum mass of . therefore , The quality determined by our method is consistent with the grid search results , But the calculation cost is saved 100 Many times . Interestingly , For each mass q q q, ∣ R − q − 1 ∣ < ϵ |R-q - 1| <\epsilon ∣R−q−1∣<ϵ Whether it is consistent in the average value of each incremental stage and all incremental stages . We're in the appendix D.4 Further discussion in R q R_q Rq A more dynamic situation
EXPERIMENT


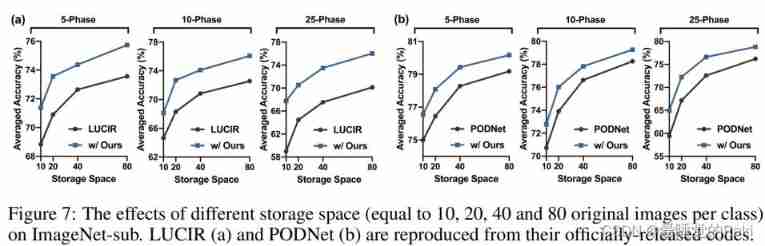


CONCLUSION
In this work , We have put forward , Use data compression with the appropriate selected compression quality , More compressed data can be saved in limited storage space , Thus, the efficiency of memory playback is greatly improved . In order to effectively determine the compression quality , We provide a process based on the decisive point (DPPs) New method of , To avoid repeated training , Our method is verified in the class incremental learning and semi supervised continuous learning of object detection . Our work not only provides an important but underexplored baseline , It also opens up a promising new way for continuous learning . Further work can be done to develop an adaptive compression algorithm for incremental data to improve the compression rate , Or propose a new regularization method to constrain the distribution changes caused by data compression . meanwhile , be based on DPPs The theoretical analysis can be used as a general framework to integrate the optimizable variables in memory playback , For example, the strategy of selecting prototypes . Besides , Our work also proposes how to save a batch of training data in a limited storage space , To best describe its distribution , This will promote a wider application in the field of data compression and data selection
Remark
Some improvements have been achieved by data compression , But I can't understand a bunch of complicated formulas , It proves that compressing data to store more pictures for recall can obtain better performance , Not bad , If it could be simpler, I would like it very much paper
边栏推荐
- leetcode:剑指 Offer 56 - II. 数组中数字出现的次数 II【简单排序】
- Hyper parameter optimization of deep neural networks using Bayesian Optimization
- cf:C. Restoring the Duration of Tasks【找规律】
- Database design graduation information management
- Software requirements engineering review
- First acquaintance with enterprise platform
- 求数据库设计毕业信息管理
- Flask CKEditor 富文本编译器实现文章的图片上传以及回显,解决路径出错的问题
- 干货丨MapReduce的工作流程是怎样的?
- Cf:b. array determinations
猜你喜欢

E-commerce (njupt)

Uni app Muke hot search project (I) production of tabbar

Given a project, how will you conduct performance testing?

Performance of MOS transistor 25n120 of asemi in different application scenarios

Hyper parameter optimization of deep neural networks using Bayesian Optimization

【Multisim仿真】利用运算放大器产生锯齿波

Introduction to go language (VI) -- loop statement

【Multisim仿真】利用运算放大器产生方波、三角波发生器
Merge multiple binary search trees
![Cf:e. price maximization [sort + take mod + double pointer + pair]](/img/a0/410f06fa234739a9654517485ce7a3.png)
Cf:e. price maximization [sort + take mod + double pointer + pair]
随机推荐
Visual slam lecture notes-10-2
基于华为云图像识别标签实战
【图像去噪】基于马尔可夫随机场实现图像去噪附matlab代码
cf:B. Array Decrements【模拟】
pstack和dmesg
更换目标检测的backbone(以Faster RCNN为例)
kubernetes 二进制安装(v1.20.15)(九)收尾:部署几个仪表盘
cf:D. Black and White Stripe【连续k个中最少的个数 + 滑动窗口】
Judge whether it is a balanced binary tree
关于富文本储存数据库格式转译问题
About my experience of "binary deployment kubernetes cluster"
视觉SLAM十四讲笔记-10-1
Visual slam lecture notes-10-1
"Case sharing" based on am57x+ artix-7 FPGA development board - detailed explanation of Pru Development Manual
[solution] codeforces round 798 (Div. 2)
Flask CKEditor 富文本编译器实现文章的图片上传以及回显,解决路径出错的问题
01. Telecommunications_ Field business experience
Cf:c. restoring the duration of tasks
Database design graduation information management
leetcode:926. 将字符串翻转到单调递增【前缀和 + 模拟分析】