当前位置:网站首页>如何实现一个延时队列 ?
如何实现一个延时队列 ?
2022-07-04 15:05:00 【InfoQ】
一、什么是延时队列

二、延时队列适用的场景?
2.1比如超时关单:
2.2 比如回调重试:
2.3 会议提醒:
2.4 各种延时提醒:
三、延时队列的实现方式?
四、如何用redis实现延时队列?
4.1我们使用redisson 来实现,首先引入redisson 包
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.3</version>
</dependency>4.2、配置redisson
redisson:
redisModel: SINGLE
singleConfig:
address: redis://127.0.0.1:63794.3延时服务:添加延时任务,取消延时任务
public class RedisDelayQueueServiceImpl implements RedisDelayQueueService {
@Autowired
private RedissonClient redissonClient;
/**
* 新增一个延时任务,添加job元信息
*
* @param job 元信息,job中包含 taskId 主键,topicId 队列id,retryNum 重试次数,delaytime 延时时间 等,此处不展开。
*/
@Override
public void addJob(Job job) {
//添加分布式锁,防止重复添加任务
RLock lock = redissonClient.getLock(RedisQueueKey.ADD_JOB_LOCK + job.getJobId());
try {
boolean lockFlag = lock.tryLock(RedisQueueKey.LOCK_WAIT_TIME, RedisQueueKey.LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BizException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL.getInfo());
}
String topicId = RedisQueueKey.getTopicId(job.getTopic(), job.getJobId());
// 1. 将job添加到 JobPool中,jobpool 作为一个全局索引,所有未执行任务都存在jobPool 中。
RMap<String, Job> jobPool = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY);
if (jobPool.get(topicId) != null) {
throw new BizException(ErrorMessageEnum.JOB_ALREADY_EXIST.getInfo());
}
jobPool.put(topicId, job);
// 2. 将job添加到 DelayBucket中,按延时时间进行排序
RScoredSortedSet<Object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.add(job.getDelay(), topicId);
} catch (InterruptedException e) {
log.error("addJob error", e);
throw new BizException("add delay job error,reason:" + e.getMessage());
} finally {
if (lock != null) {
lock.unlock();
}
}
}
/**
* 删除job信息,为什么要删除job 信息?
* 当我们确信上一个延时任务没有必要执行时,我们可以提前取消延时任务的执行。
*
* @param jobDie 元信息
*/
@Override
public void deleteJob(JobDie jobDie) {
RLock lock = redissonClient.getLock(RedisQueueKey.DELETE_JOB_LOCK + jobDie.getJobId());
try {
boolean lockFlag = lock.tryLock(RedisQueueKey.LOCK_WAIT_TIME, RedisQueueKey.LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BizException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL.getInfo());
}
String topicId = RedisQueueKey.getTopicId(jobDie.getTopic(), jobDie.getJobId());
//从全局索引中删除任务。
RMap<String, Job> jobPool = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY);
jobPool.remove(topicId);
//从zset 中删除任务
RScoredSortedSet<Object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.remove(topicId);
} catch (InterruptedException e) {
log.error("addJob error", e);
throw new BizException("delete job error,reason:" + e.getMessage());
} finally {
if (lock != null) {
lock.unlock();
}
}
}
}4.4搬运线程:
@Slf4j
@Component
public class CarryJobScheduled {
@Autowired
private RedissonClient redissonClient;
/**
* 启动定时开启搬运JOB信息
*/
@Scheduled(cron = "*/1 * * * * *")
public void carryJobToQueue() {
//System.out.println("carryJobToQueue --->");
RLock lock = redissonClient.getLock(RedisQueueKey.CARRY_THREAD_LOCK);
try {
boolean lockFlag = lock.tryLock(RedisQueueKey.LOCK_WAIT_TIME, RedisQueueKey.LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BizException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL.getInfo());
}
// 将到期的任务取出来
RScoredSortedSet<Object> bucketSet = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
long now = System.currentTimeMillis();
Collection<Object> jobCollection = bucketSet.valueRange(0, false, now, true);
if (CollectionUtils.isEmpty(jobCollection)) {
return;
}
// 将到期的任务搬运到消费队列中,zset 中的任务删除
List<String> jobList = jobCollection.stream().map(String::valueOf).collect(Collectors.toList());
RList<String> readyQueue = redissonClient.getList(RedisQueueKey.RD_LIST_TOPIC_PRE);
if (CollectionUtils.isEmpty(jobList)) {
return;
}
if (readyQueue.addAll(jobList)) {
bucketSet.removeAllAsync(jobList);
}
} catch (InterruptedException e) {
log.error("carryJobToQueue error", e);
} finally {
if (lock != null) {
lock.unlock();
}
}
}
}4.5消费线程:
@Slf4j
@Component
public class ReadyQueueContext {
@Autowired
private RedissonClient redissonClient;
@Autowired
private ConsumerService consumerService;
/**
* TOPIC消费
*/
@PostConstruct
public void startTopicConsumer() {
TaskManager.doTask(this::runTopicThreads, "开启TOPIC消费线程");
}
/**
* 开启TOPIC消费线程
* 将所有可能出现的异常全部catch住,确保While(true)能够不中断
*/
@SuppressWarnings("InfiniteLoopStatement")
private void runTopicThreads() {
while (true) {
RLock lock = null;
try {
lock = redissonClient.getLock(RedisQueueKey.CONSUMER_TOPIC_LOCK);
} catch (Exception e) {
log.error("runTopicThreads getLock error", e);
}
try {
if (lock == null) {
continue;
}
// 分布式锁时间比Blpop阻塞时间多1S,避免出现释放锁的时候,锁已经超时释放,unlock报错
boolean lockFlag = lock.tryLock(RedisQueueKey.LOCK_WAIT_TIME, RedisQueueKey.LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
continue;
}
// 1. 获取ReadyQueue中待消费的数据
RBlockingQueue<String> queue = redissonClient.getBlockingQueue(RedisQueueKey.RD_LIST_TOPIC_PRE);
String topicId = queue.poll(60, TimeUnit.SECONDS);
if (StringUtils.isEmpty(topicId)) {
continue;
}
// 2. 获取job元信息内容
RMap<String, Job> jobPoolMap = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY);
Job job = jobPoolMap.get(topicId);
// 3. 消费
FutureTask<Boolean> taskResult = TaskManager.doFutureTask(() -> consumerService.consumerMessage(job.getJobId(),job.getTopic(), job.getBody()), job.getTopic() + "-->消费JobId-->" + job.getJobId());
if (taskResult.get()) {
// 3.1 消费成功,删除JobPool和DelayBucket的job信息
jobPoolMap.remove(topicId);
} else {
/**
* 重试次数为0就直接返回
*/
if (job.getRetry() == 0) {
return;
}
int retrySum = job.getRetry() + 1;
// 3.2 消费失败,则根据策略重新加入Bucket
// 如果重试次数大于5,则将jobPool中的数据删除,持久化到DB
if (retrySum > RetryStrategyEnum.RETRY_FIVE.getRetry()) {
jobPoolMap.remove(topicId);
continue;
}
job.setRetry(retrySum);
long nextTime = job.getDelay() + RetryStrategyEnum.getDelayTime(job.getRetry()) * 1000;
// log.info("next retryTime is [{}]", DateUtil.long2Str(nextTime));
RScoredSortedSet<Object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.add(nextTime, topicId);
// 3.3 更新元信息失败次数
jobPoolMap.put(topicId, job);
}
} catch (Exception e) {
log.error("runTopicThreads error", e);
} finally {
if (lock != null) {
try {
lock.unlock();
} catch (Exception e) {
log.error("runTopicThreads unlock error", e);
}
}
}
}
}关于领创集团(Advance Intelligence Group)
往期回顾 BREAK AWAY
边栏推荐
- Position encoding practice in transformer
- 电子元器件B2B商城系统开发:赋能企业构建进销存标准化流程实例
- Readis configuration and optimization of NoSQL (final chapter)
- 线性时间排序
- How to implicitly pass values when transferring forms
- 科普达人丨一文看懂阿里云的秘密武器“神龙架构”
- Overflow: the combination of auto and Felx
- System. Currenttimemillis() and system Nanotime (), which is faster? Don't use it wrong!
- Visual Studio 2019 (LocalDB)MSSQLLocalDB SQL Server 2014 数据库版本为852无法打开,此服务器支持782
- How to decrypt worksheet protection password in Excel file
猜你喜欢
嵌入式软件架构设计-函数调用
Vscode setting outline shortcut keys to improve efficiency
函數式接口,方法引用,Lambda實現的List集合排序小工具
Filtered off site request to

Vscode prompt Please install clang or check configuration 'clang executable‘
电子元器件B2B商城系统开发:赋能企业构建进销存标准化流程实例
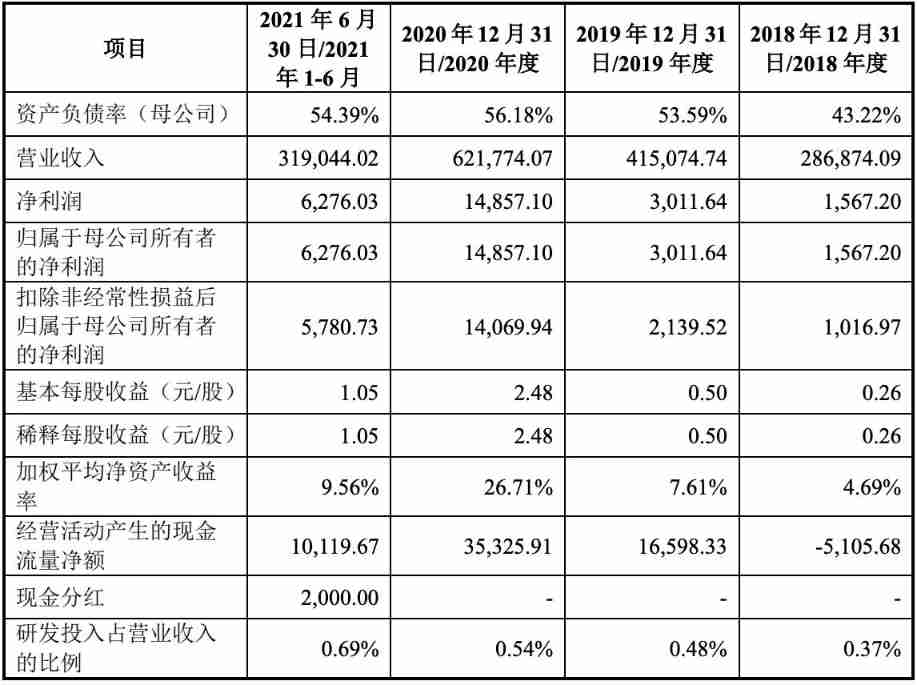
Yanwen logistics plans to be listed on Shenzhen Stock Exchange: it is mainly engaged in international express business, and its gross profit margin is far lower than the industry level
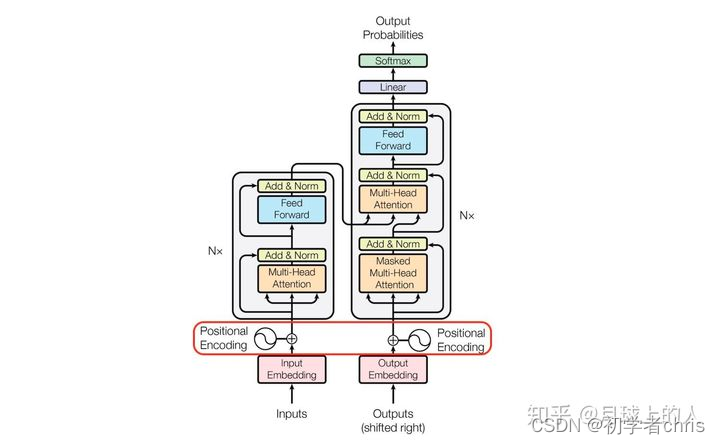
Position encoding practice in transformer

《吐血整理》保姆级系列教程-玩转Fiddler抓包教程(2)-初识Fiddler让你理性认识一下
The vscode waveform curve prompts that the header file cannot be found (an error is reported if the header file exists)
随机推荐
Understand ThreadLocal in one picture
GO开发:如何利用Go单例模式保障流媒体高并发的安全性?
C# 实现 FFT 正反变换 和 频域滤波
The vscode waveform curve prompts that the header file cannot be found (an error is reported if the header file exists)
The winning rate against people is 84%, and deepmind AI has reached the level of human experts in army chess for the first time
Maximum subarray and matrix multiplication
Why do you say that the maximum single table of MySQL database is 20million? Based on what?
Communication mode based on stm32f1 single chip microcomputer
线程池的使用和原理
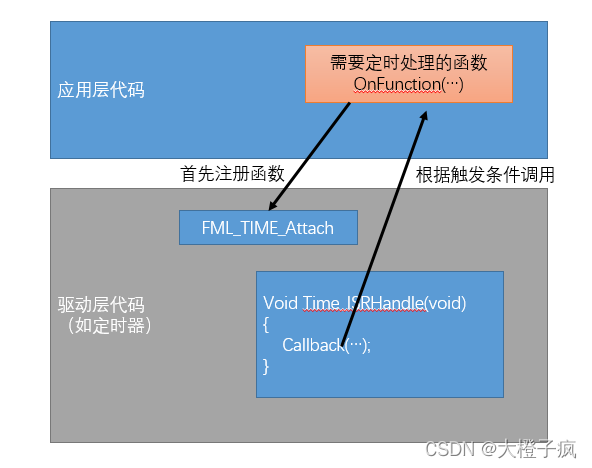
嵌入式软件架构设计-函数调用
Height residual method
L1-072 scratch lottery
新的职业已经出现,怎么能够停滞不前 ,人社部公布建筑新职业
高度剩余法
.Net 应用考虑x64生成
Overflow: the combination of auto and Felx
Position encoding practice in transformer
Application of clock wheel in RPC
Readis configuration and optimization of NoSQL (final chapter)
Understand the rate control mode rate control mode CBR, VBR, CRF (x264, x265, VPX)