当前位置:网站首页>Summary of scaling and coding methods in Feature Engineering
Summary of scaling and coding methods in Feature Engineering
2022-07-27 13:45:00 【deephub】
Data preprocessing is a very important part of machine learning life cycle . Feature engineering is also an important part of data preprocessing , The most common feature engineering methods are as follows :
- code
- The zoom
- transformation
- discretization
- Separate
wait
In this paper, we mainly introduce the main methods of feature scaling and feature coding .

Feature scaling
Feature scaling is a technology that standardizes independent features in data within a fixed range . Some machine learning models are based on distance matrix , for example :k - nearest - neighbors, SVM and Neural Network. For these models , Feature scaling is very important , Especially when the scope of features is very different . Features with a large range have a great influence on distance calculation .
Standardization Standarization
The standardization of data is to scale the data , To fall into a small, specific area , Convert data into systems ⼀ Standards for .z-score Standardization , That is zero - Mean normalization ( Common methods )
- Standardization ( or z Fractional normalization ) After zooming , The characteristic becomes a standard normal distribution , have μ= 0 and σ= 1, among μ mean value ,σ Is the standard deviation of the mean .
- By standardizing about 68% The value is between -1 and 1 Between .

from sklearn.preprocessing import StandardScaler
scale = StandardScaler().fit(data)
scaled_data = scale.transform(data)
Normalization ( normalization )Normalization
Normalization is to turn data into (0,1) Decimal between . Mainly for the convenience of data processing , Map data to 0~1 Within limits , It can make the processing process more convenient 、 Fast .
Normalization is often used as part of machine learning data preparation . The goal of normalization is to change the value of a numeric column in a dataset , To use a universal scale , Without distorting the difference in value range or losing information
The most common method is minimal - Maximum zoom , The formula is as follows :

from sklearn.preprocessing import MinMaxScaler
norm = MinMaxScaler().fit(data)
transformed_data = norm.transform(data)
Dividing each value of a feature by the maximum value is another way to normalize . It is usually used with sparse data ( Such as images ).
data_norm = data['variable']/np.max(data['variable'])
Another normalization method is RobustScalar, Used to deal with outliers .RobustScalar Use the quartile range (IQR), Therefore, it is robust to outliers .
from sklearn.preprocessing import RobustScaler
rob = RobustScaler().fit(data)
data_norm = rob.transform(data)
The difference between standardization and normalization
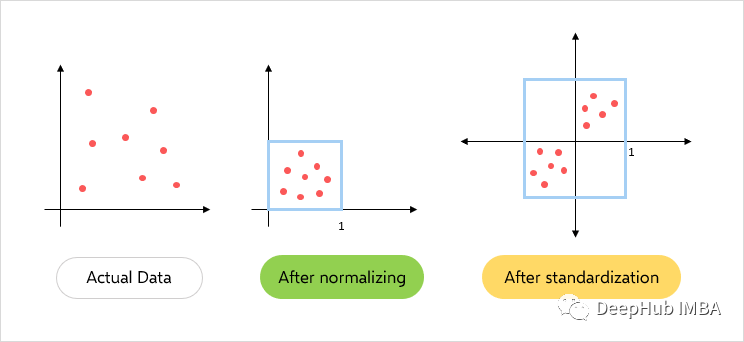
- In normalization, only the range of data is changed , In standardization, the shape of data distribution will be changed .
- Normalization rescales these values to [0,1] Within the scope of . It is very effective when all parameters need to have the same positive scale . But outliers in the dataset will be lost .
- In standardization , The data is scaled to the average (μ) by 0, Standard deviation (σ) by 1( Unit variance ).
- Normalized in 0 To 1 Between scaling data , All data are positive . The positive and negative values of the standardized data centered on zero .
How to choose which zoom method to use ?
- When the data has a recognition scale and the algorithm used will not affect the distribution of the data , such as K-Nearealt Neighbors and Artificial Neural Networks , Normalization is useful .
- When the data is a recognition scale , And the algorithm used does have Gauss ( normal ) Make assumptions based on distributed data , For example, linear regression , The standardization of logistic regression and linear discriminant analysis is very useful .
Although it is said that , But using that scaling to process data requires actual verification , In practice, the original data can be used to fit the model , Then standardize and normalize and compare , That good performance is to use that , The following figure is a list of algorithms that require feature scaling :

Feature code
Above, we have introduced the feature scaling for numerical variables , This section will introduce the feature coding for classification variables , Before entering the details , Let's look at the different types of feature coding .

NOMINAL CATEGORICAL It is the categorical variable that we don't need to care about permutation or order . Such as gender , Product category , National Area , These categorical variables have no concept of order .
ORDINAL CATEGORICAL Is an ordinal category , The categories here also contain information about order , For example, our exam scores , optimal 、 good 、 in 、 Bad , Excellent is the best , Bad is the worst . Or our educational level , Primary school , Middle school , university , master , It is also arranged in order .
After knowing the above types , Let's start with the introduction of feature coding :
Hot coding alone (ONE HOT)
We have one containing 3 Columns of categorical variables , Then each heat code will be created for a classification variable in a heat code 3 Column .
Single hot coding is also called one bit effective coding . The method is to use N position Status register N Status Encoding , Each state has its own register bit , And at any time , Only one of them works .

Dummy variable trap
Dummy variable traps are generally required when introducing virtual variables m Qualitative variables , Introduce... Into the model m-1 Virtual variables . Otherwise, if m Virtual variables , It will lead to complete collinearity between the explanatory variables of the model .
So in the example above , We can skip any column. Here we choose to skip the first column “red”

Single heat coding is simple , But pages have obvious shortcomings :
Suppose a column has 100 A categorical variable . Now, if you try to convert classified variables into dummy variables , We will get 99 Column . This will increase the dimension of the entire dataset , This leads to dimensional curse .
So basically , If there are many categorical variables in a column, we should not use this method . Here is a simple solution , Only those categories with the most repetitions are considered , For example, consider only the former 10 The largest number of categories , And apply coding only to these categories .

from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(drop='first',sparse=False,dtype=np.int32)
counts = df['brand'].value_counts()
df['brand'].nunique()
threshold = 100
repl = counts[counts <= threshold].index
pd.get_dummies(df['brand'].replace(repl, 'uncommon')).sample(5)

Serialization tag encoding (ORDINAL ENCODING)
This encoding method is only used for ordinal categories , Because the ranking is based on the importance of categories . For example, the following table PHD Considered the highest degree , So I gave it the highest label .

from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['Poor','Average','Good'],['School','UG','PG']])
oe.fit(X_train)
X_train = oe.transform(X_train)
Tag code (LABEL ENCODING)
The tag encoding is the same as the serialization tag encoding , But its encoded number does not contain the meaning of sequence .

from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(y_train)
le.classes_
Serialization encoding of goal guidance
This method calculates the average value of each classification variable according to the output , Then rank them . As shown in the following table
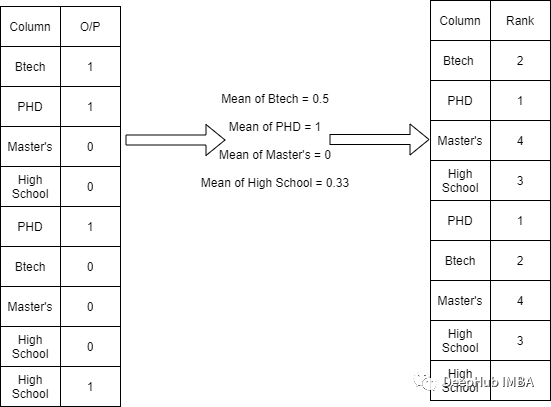
In the ordinal category , We can apply this technology , Because our final output contains information about the order .
Average coding (MEAN ENCODING)
In this method, the category will be converted to its average value according to the output . In the case of classification variables with many specific columns , This type of method can be applied .
for example , In the table below , We group according to the categories of features , Then find the average , And use the average value obtained to replace the category

author :sumit sah
边栏推荐
- Fiddler抓包工具+夜神模拟器
- leetcode——83,24; Machine learning - neural networks
- Seata 在蚂蚁国际银行业务的落地实践
- Additional: [urlencoder.encode (string to be encoded, "encoding method");] (what is it?; why do we use this to encode when we set values in cookies?) (to be improved...)
- 滑环的分类以及用途
- SNMP (Simple Network Management Protocol)
- Install the wireless network card driver
- 产品经理经验谈100篇(十一)-策略产品经理:模型与方法论
- 剑指Offer 07 重建二叉树 -- 从中序与后序遍历序列构造二叉树
- MFC FTP creates multi-level folders and uploads files to the specified directory of FTP
猜你喜欢

v-show

Additional: [urlencoder.encode (string to be encoded, "encoding method");] (what is it?; why do we use this to encode when we set values in cookies?) (to be improved...)

Evconnlistener of libevent_ new_ bind
常见分布式理论(CAP、BASE)和一致性协议(Gosssip、Raft)

Product manager experience 100 (XI) - Strategic Product Manager: model and methodology

期货开户的条件和流程
libevent 之 evconnlistener_new_bind

Verilog's system tasks - $fopen, $fclose and $fddisplay, $fwrite, $fstrobe, $fmonitor

Dat.gui control custom placement and dragging
Go language series: how to build a go language development environment?
随机推荐
"Digital economy, science and technology for the good" talk about dry goods
js基础知识整理之 —— 数组
纵横靶场-图片的奥秘
Li Hang, director of ByteDance AI Lab: past, present and future of language model
Text style
【300+精选大厂面试题持续分享】大数据运维尖刀面试题专栏(九)
Training in the second week of summer vacation on July 24, 2022
在“元宇宙空间”UTONMOS将打开虚实结合的数字世界
基于frp实现内网穿透——借助公网服务器实现ssh远程连接内网服务器
Seata 在蚂蚁国际银行业务的落地实践
v-text
OPPO 自研大规模知识图谱及其在数智工程中的应用
Add index to the field of existing data (Damon database version)
[introduction to C language] zzulioj 1021-1025
电滑环的常用类型
Double material first!
【每日一题】1206. 设计跳表
【LeetCode】592. 分数加减运算
egg-swagger-doc 图形验证码解决方案
evutil_make_internal_pipe_: pipe: Too many open files