当前位置:网站首页>一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
2022-08-05 01:28:00 【冰露可乐】
一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,看书学不到推荐系统的关键技术。看书学不到推荐系统的关键技术。看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
提示:文章目录
文章目录
前言:双塔模型可以看作是矩阵补充的升级版
上一篇文章讲了矩阵补充模型,这篇文章讲的内容是双塔模型。
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
双塔模型可以看作是矩阵补充的升级版,下面是之前介绍的矩阵补充模型。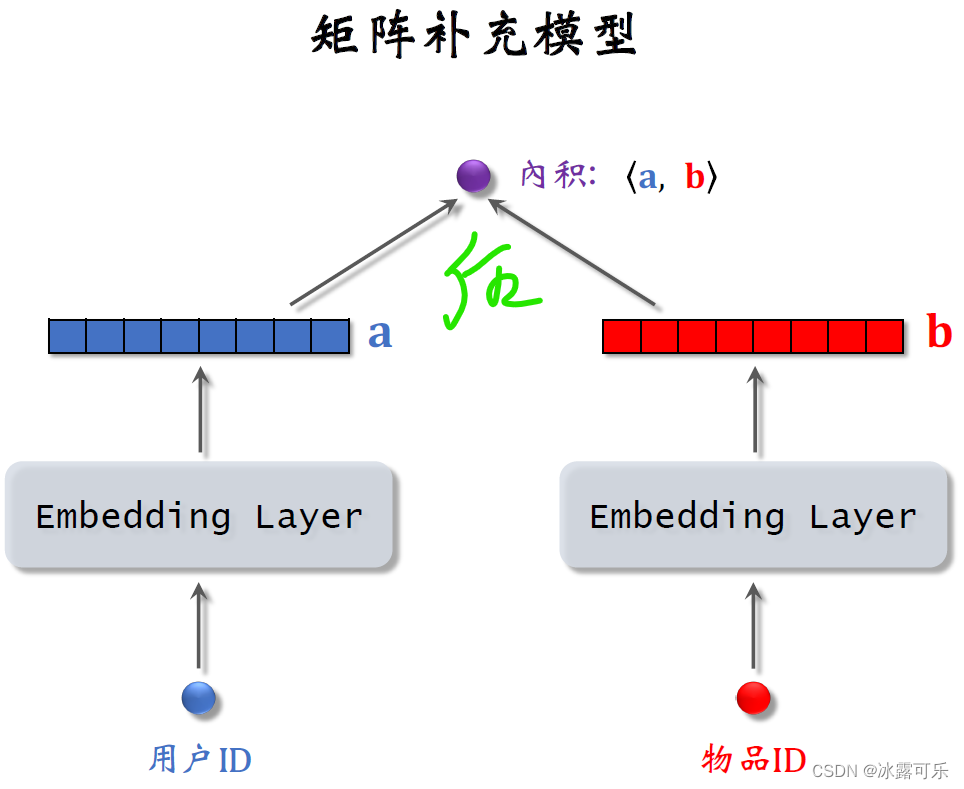
模型的输入是一个用户ID和一个物品ID,模型用两个embedding层把两个ID映射到两个向量,
用两个向量的内积来预估用户对物品的兴趣分数。
这个模型比较弱,只用到了用户和物品的ID,没有用到用户和物品的属性。
今儿个介绍的双塔模型可以看作是矩阵补充模型的升级。
下面开始讲双塔模型的结构
我们先来看用户的特征,我们知道用户ID还能从用户填写的资料和用户行为中获取很多特征,包括离散特征和连续特征。
所有这些特征不能直接输入神经网络,而是要先做一些处理,比如用embedding层把用户ID映射到一个向量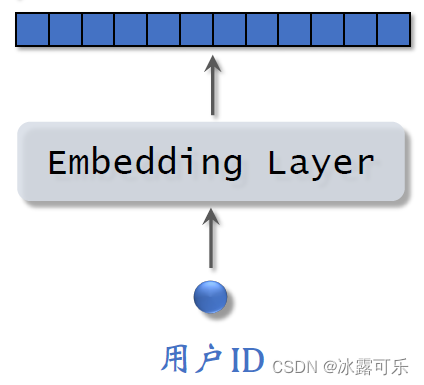
跟之前我们讲过的离散特征的做法相同,用户还有很多离散特征,比如所在城市感兴趣的话题等等。
用embedding层把用户的离散特征映射成向量,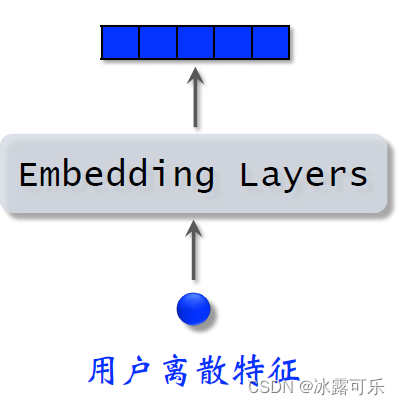
对于每个离散特征,用单独一个embedding层得到一个向量,比如用户所在城市,用一个embedding层
用户感兴趣的话题,用另一个embedding层
对于性别这样类别数量很少的离散特征,直接用one hot编码就行,可以不做embedding
用户还有很多连续特征,比如年龄、活跃程度、消费金额等等。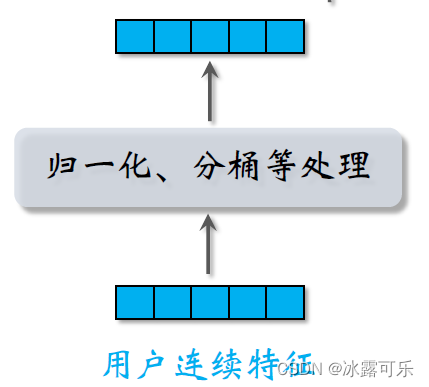
不同类型的连续特征有不同的处理方法,最简单的是做归一化,让特征均值是零,标准差是一。
有些长尾分布的连续特征需要特殊处理,比如取log,比如做分筒,
做完特征处理,得到很多特征向量,把这些向量都拼起来输入神经网络。
神经网络可以是简单的全连接网络,也可以是更复杂的结构,比如深度交叉网络。
神经网络输出一个向量,这个向量就是对用户的表征。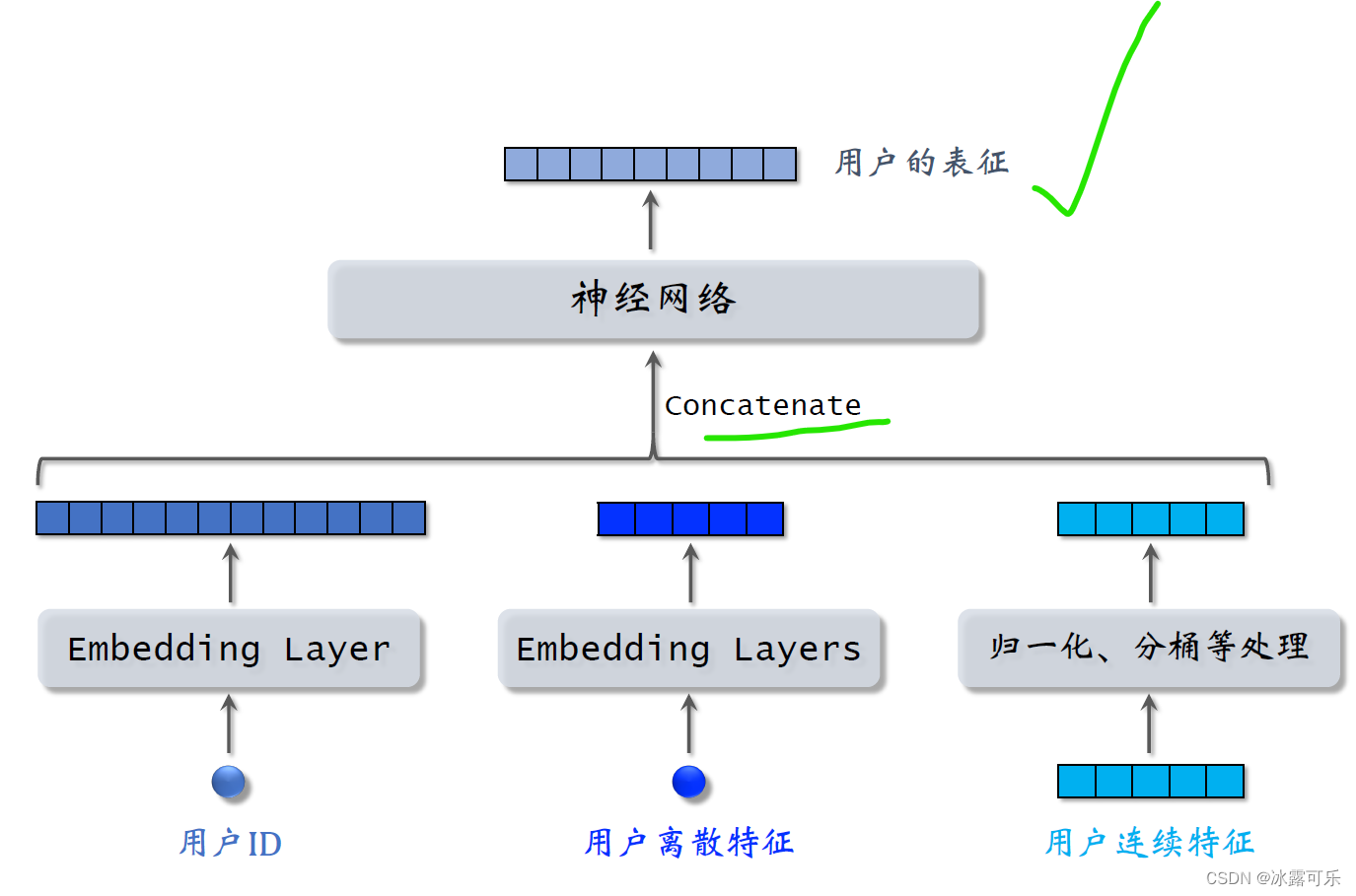
做召回用到这个向量,
同理,物品的特征也是用类似的方法处理。
用embedding层处理物品ID和其他离散特征,
用归一化取对数或者分桶等方法处理物品的连续特征,
把得到的特征输入一个神经网络。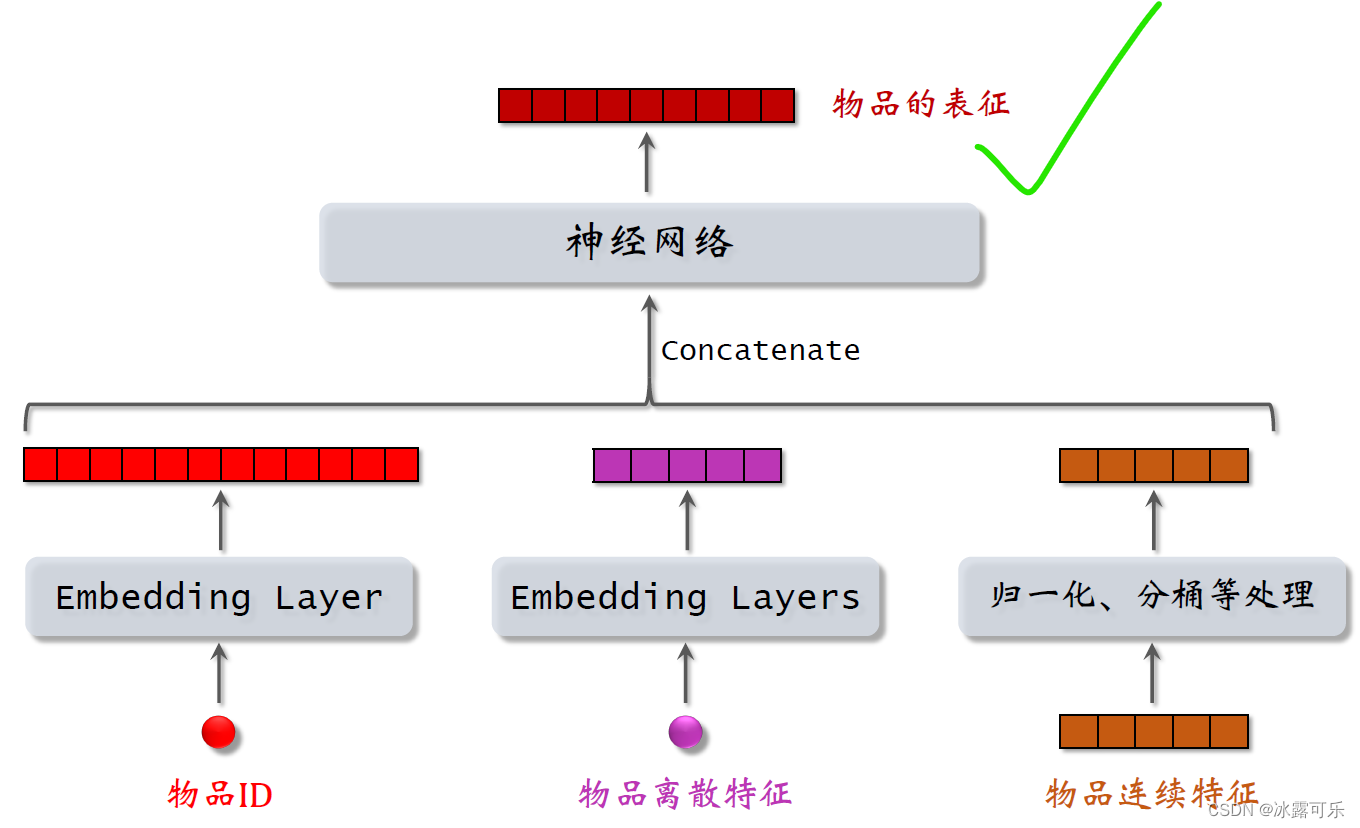
神经网络输出的向量就是物品的表征,用于召回。
双塔模型
下面这样的模型就叫双塔模型,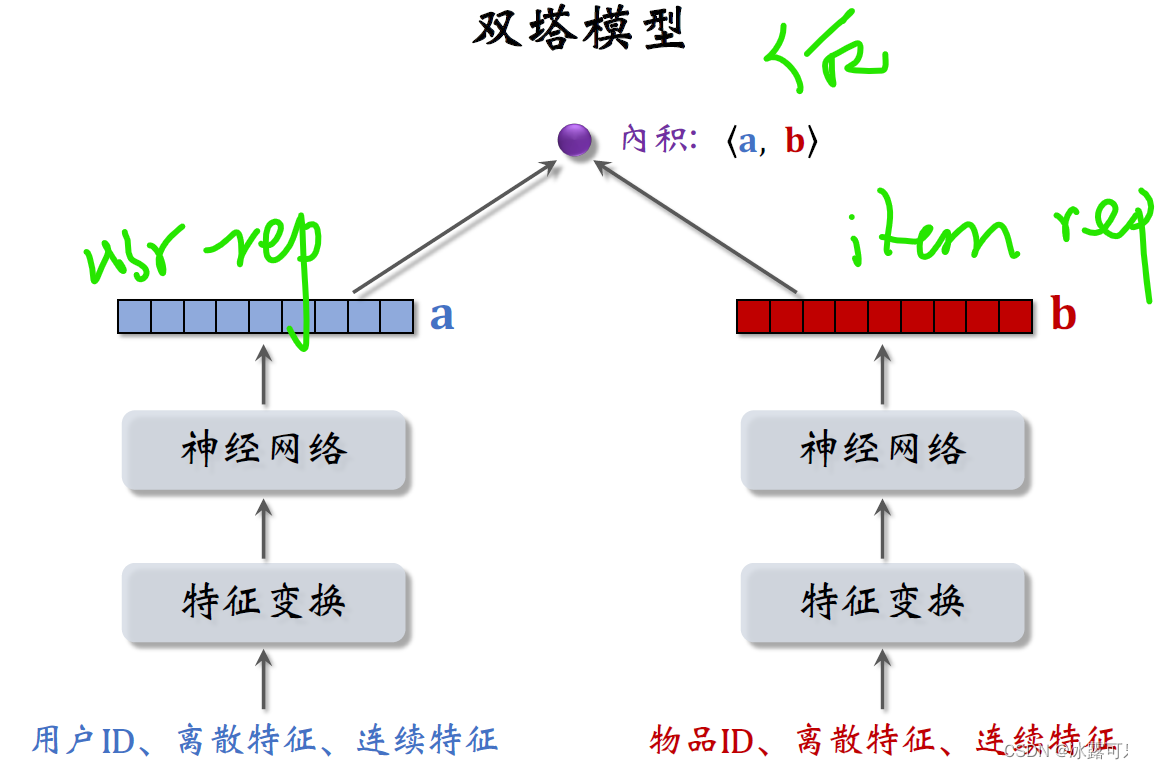
**尤其要注意:**本模型直接拿用户表征rep和物品表征rep去融合,史称后端特征融合模型!!
——这是召回的用法,绝对不能提前concat再灌入神经网络又去映射一个打分rate(那是精排的做法!)
左边的塔提取用户的特征
右边的它提取物品的特征
跟上一篇文章的矩阵补充模型相比,双塔模型的不同之处就在于使用了ID 之外的多种特征,
作为双塔的输入,两个塔各输出一个向量记作a和b,
两个向量的内积就是模型最终的输出rate,它即预估用户对物品的兴趣。
现在更常用的输出方法是余弦相似度。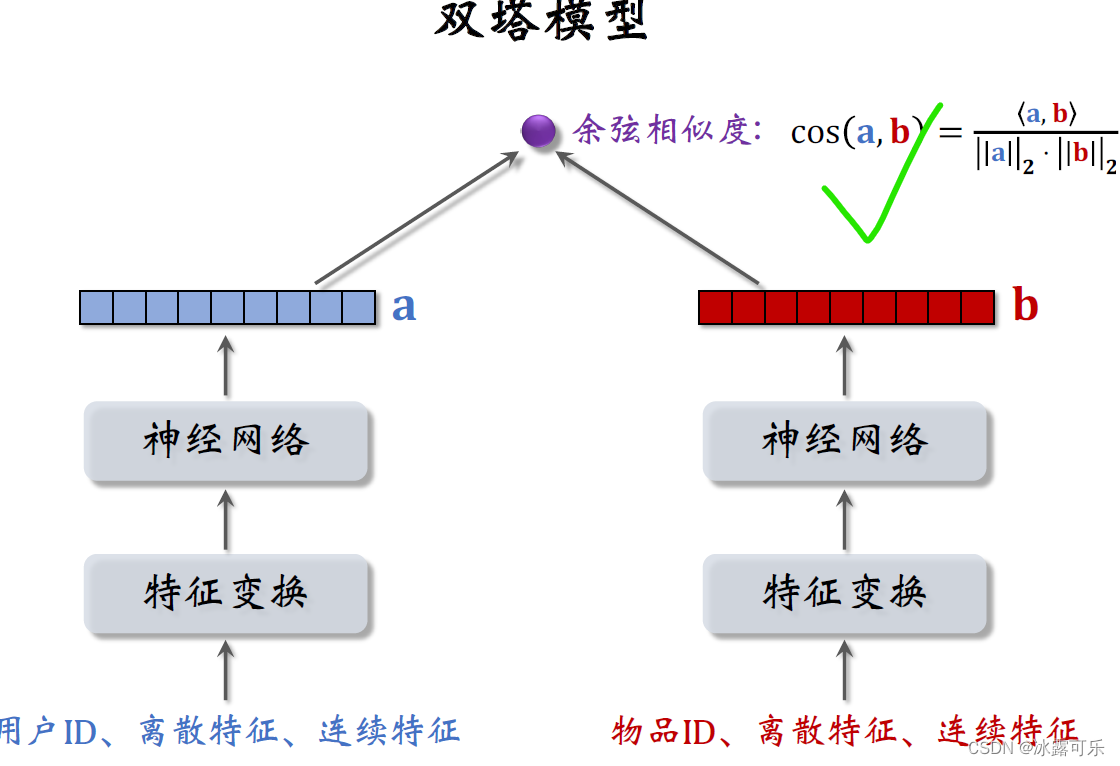
两个塔的输出,分别记作向量a和b,余弦相似度意思是两个向量夹角的余弦值,
它等于向量内积除以a的二范数,再除以b的二范数,
其实就相当于先对两个向量做归因化,然后再求内积
余弦相似度的大小介于负一到正一之间。
双塔模型的训练方法:pointwise,parawise,listwise
有三种训练双塔模型的方式

第一种是pointwise训练,独立看待每个正样本和负样本,
做简单的二元分类训练模型,把正样本、负样本组成一个数据集。
在数据集上做随机梯度下降训练双塔模型。
第二种训练双塔模型的方式是parawise,每次取一个正样本,一个负样本组成一个二元组。
损失函数用triplely hing loss或者triple logistic loss
可以参考下面这篇Facebook发的论文。
《Jui-Ting Huang et al. Embedding-based Retrieval in Facebook Search. InKDD, 2020.》
第三种训练双塔模型的方式是listwise,每次取一个正样本和多个负样本组成一个list。
训练方式类似于多元分类,参考下面的文献二,这是Youtube发的论文,
《Xinyang Yi et al. Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations. In RecSys, 2019.》
训练的时候要用到正样本和负样本。
那么该如何选择正负样本?
正样本很简单,就是用户点击过的物品,用户点击过一个物品,就说明用户对这个物品感兴趣,
负样本的意思是用户不感兴趣的,负样本的选择没有。
那么显然,在实践中负样本的选择是比较讲究的,有几种看起来比较合理的副样本:
比如没有被召回的
召回了,但是被粗排,精排淘汰的
还有曝光了,但是用户没有点击的
该用哪种?下一篇文章我们再详细讲解如何选择正负样本,
感兴趣的话,可以自己阅读刚才提到的两篇论文,
论文讲解了Facebook Youtube如何选择正负样本,
我们小红书基本是照着做的,再加一些自己的小技巧,取得了很好的效果。
具体讲解三种训练双塔模型的方式
Pointwise训练
第一种是pointwise训练,pointwise是最简单的训练方式,
我们把召回看作简单的二元分类任务,正样本意思是历史记录显示用户对物品感兴趣
对于正样本,我们要鼓励向量a和b的cos相似度接近+1
负样本的意思是用户对物品不感兴趣,对于负样本,我们要鼓励向量a和b的cos相似度接近-1
这就是个很典型的二元分类问题。
如果做pointwise训练,可以把正负样本的数量控制在1 : 2或者1 : 3。
我也不知道为什么,但是互联网大厂的人都这么做,这算是业内的经验。
Pairwise训练
第二种训练双塔模型的方式是pair wise,做训练的时候,每一组的输入是一个三元组,包括一个用户ID和两个物品ID。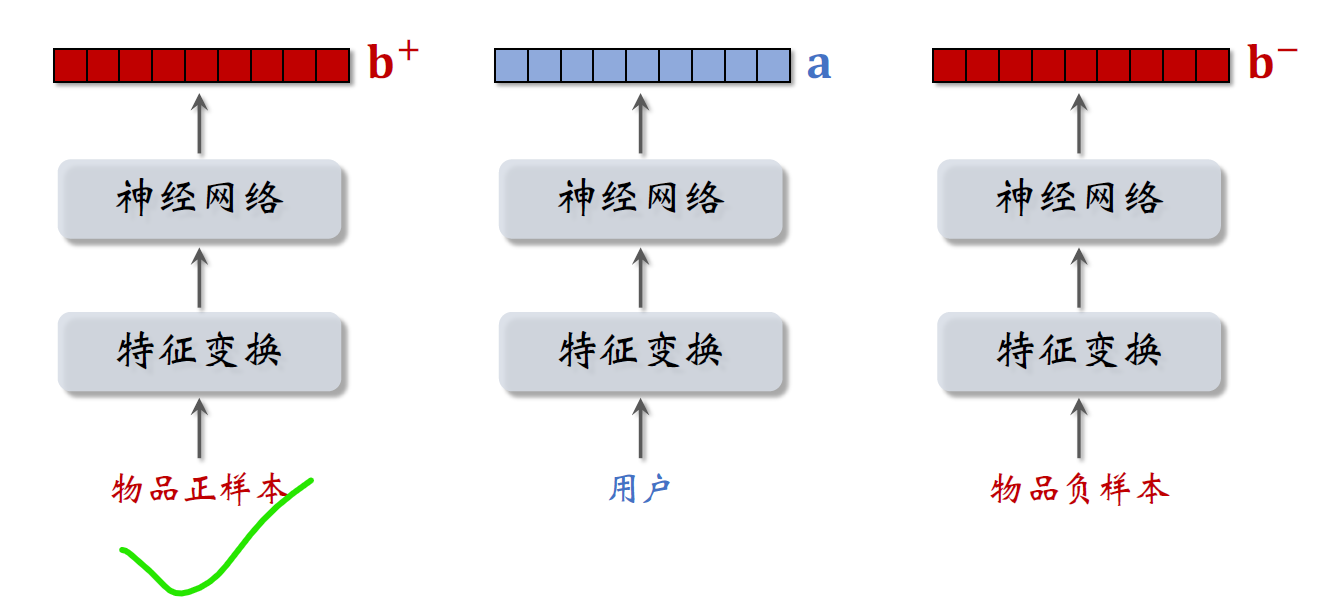
左边的物品是这样的,就是用户感兴趣的物品。
右边的物品是负样本,是用户不感兴趣的物品,
把用户的特征和物品的特征各自做变换,然后输入神经网络,最终输出三个向量,
用户的特征向量记作a,
两个物品的特征,向量记作B加和B减两个物品,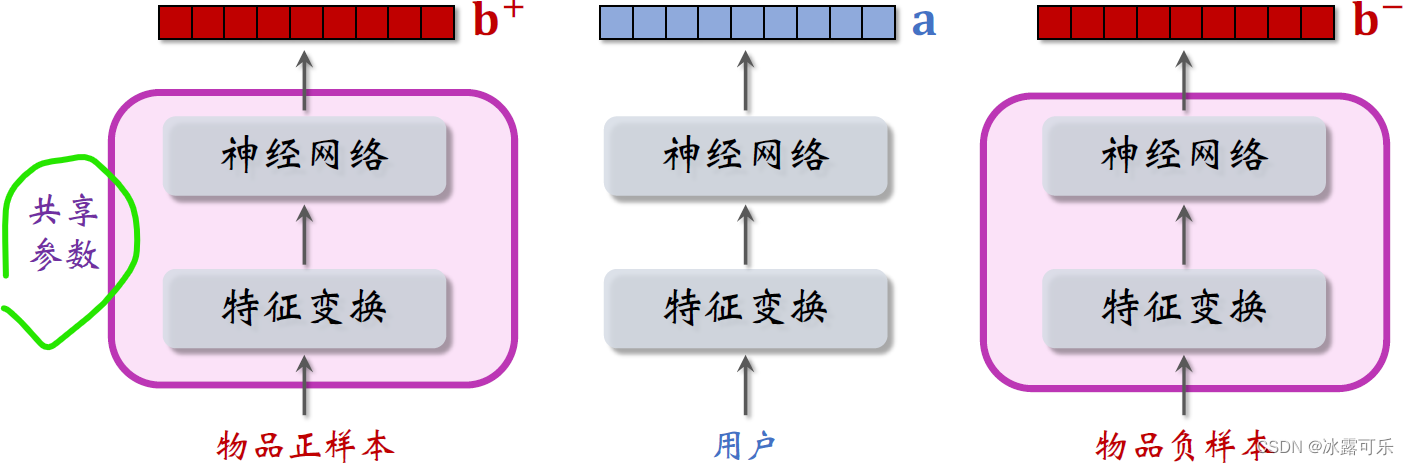
特征变换映射物品的embedding结构是相同的,里面的embedding层和全连接层都用一样的参数
分别计算用户对两个物品的兴趣
用户对正样本的兴趣是向量a和向量b加的余弦相似度,这个值越大越好,最好是接近+1。
用户对负样本的兴趣是向量a和向量b减的余弦相似度,这个值越接近-1越好。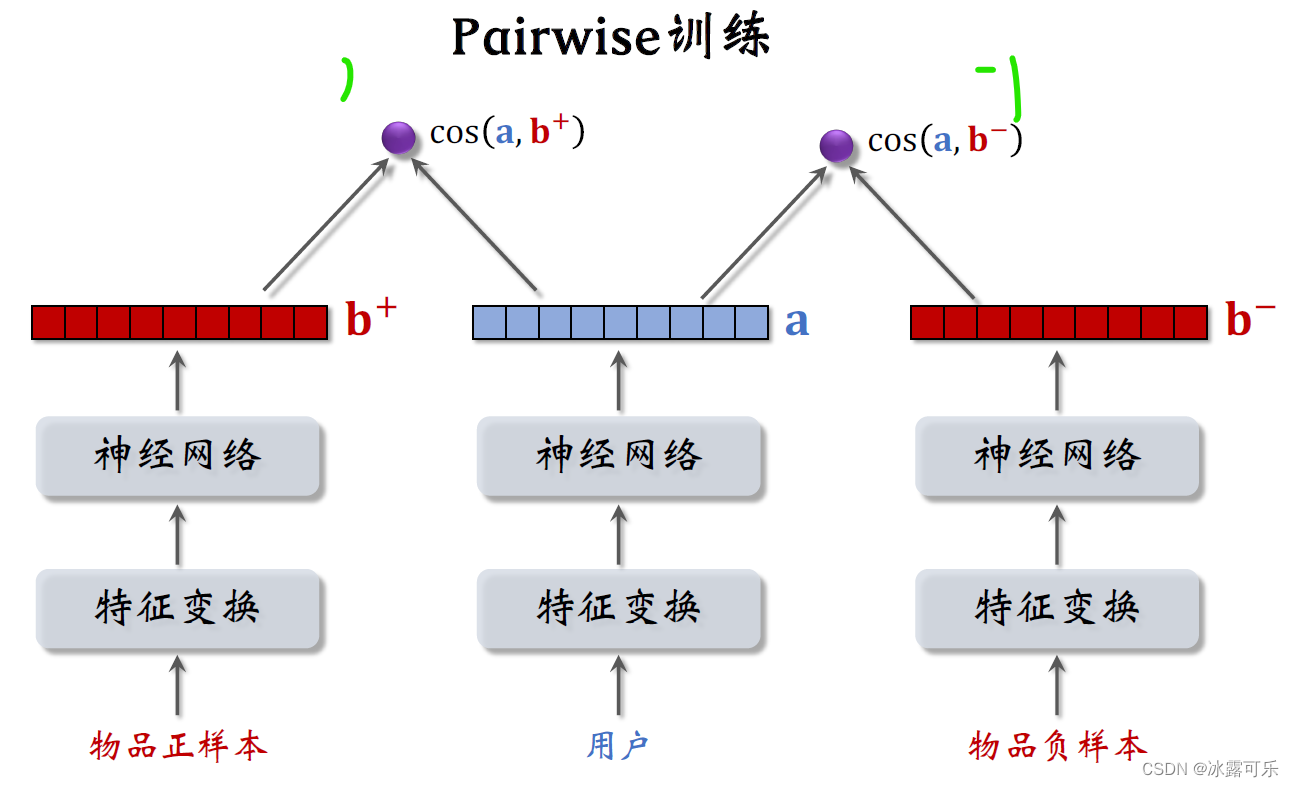
做pair wise训练的基本想法是让用户对正样本的兴趣尽量大,对负样本的兴趣尽量小。
也就是让向量a和b加的运行相似度大于向量a和b减的余弦相似度,而且两者之差越大越好。
我们来推导一下损失函数,
我们希望看到用户对正样本的兴趣很大,而对负样本的兴趣很小,最好是前者比后者大M这么多。
这个M是个超参数,需要调,比如设置成1,
如果前者比后者大了M,那么就没有损失,
否则如果用户对正样本的兴趣不够大,没有比负样本的兴趣大M这么多,就会有损失,
损失等于cos(a,b减)加上M,再减去cos(a,b加)【这个loss是正数,需要让它降到0才行】
这样就推导出了triple hinge loss。
如果熟悉孪生网络sign is network,应该见过这种损失函数。
训练的时候每个训练样本都是个三元组,向量a是用户的表征,B加和B减分别是物品正样本和负样本的表征,
我们希望损失函数越小越好,训练的过程就是对损失函数求最小化,
用梯度更新双塔神经网络的参数,
Triplely hinge loss只是一种损失函数,还有别的损失函数起到同样的作用。
triplet logistic loss是这样定义的,其实就是把logistic函数作用到这一项最小化,
Logistic函数会鼓励这一项尽量小,也就是让cos( a,b减)尽量小。
让cos( a,b加)尽量大,
跟上面的Triplely hinge loss道理是一样的,
都是让用户对正样本的兴趣分数尽量高,用户对负样本的兴趣分数尽量低。
这里的sigma是个大于零的超参数控制损失函数的形状,Sigma需要手动设置。
稳了,我们已经推导出了Triplely hinge loss和Triplely logistic loss,可以通过最小化这样的损失函数来训练双塔模型。
训练样本都是三元组,其中一个用户,一个正样本物品,还有一个负样本物品。
Listwise训练
第三种训练双塔模型的方式是list wise。
做list wise训练的时候,每次取一个正样本和很多负样本,
需要一个用户把它的特征向量记作a,
取一个正样本,意思是历史记录显示用户喜欢这个物品,把这个物品的特征向量记作B加,
还需要取N个负样本,把它们的特征向量去做B1减到BN减。
做训练的时候要鼓励a和正样本b+的余弦相似度尽量大,
鼓励a和负样本bn-的余弦相似度尽量小。
下面我演示一下list white训练具体怎么做。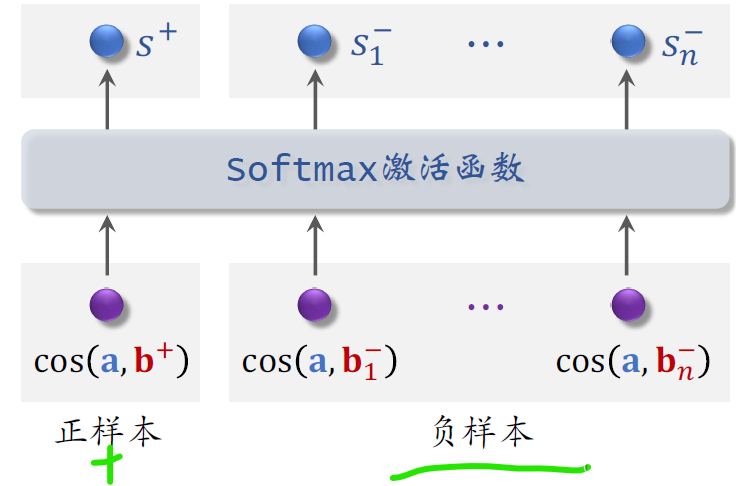
向量a和B加的余弦相似度是个介于负一到正一之间的实数,意思是用户对正样本物品兴趣的预估分数。
这个分数越大越好,最好是接近正一
其余的cos相似度对应负样本,它们是用户对N个负样本兴趣的预估分数,这N个分数越小越好,最好是接近负一
把这N个负样本的分,和正样本的分,全部输入soft max激活函数【它就是将整体归一化为0–1的函数】,
激活函数输出N+1个分数,这些分数都介于零到一之间,
最左边的分数S加对应正样本,我们希望这个分数越大越好,最好是能接近1。
右边的N个分数对应负样本,我们希望这些分数越小越好,最好都接近零。
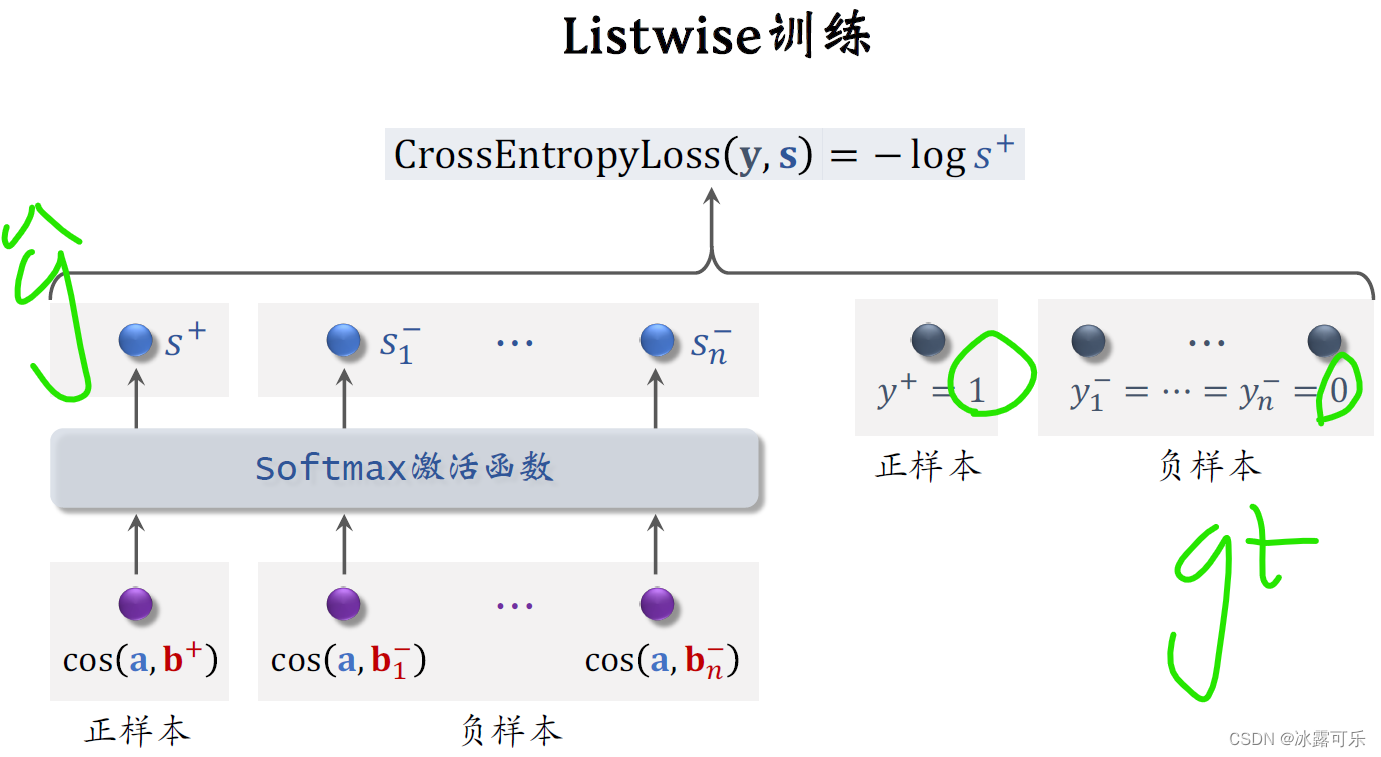
上图中,y+=1是正样本的标签,意思是鼓励S+接近1
负样本的标签是Y1减到YN减,把它们都设置成0,意思是鼓励S1减到SN减都接近0,
我们用Y和S的交叉熵作为损失函数。
训练的时候,最小化交叉熵,意思是鼓励soft max,输出的预测值S,尽可能接近标签Y,
其实交叉商就等于负的log s加【上面公式】
训练的时候最小化交叉商也就是最大化S加,
这就等价于最大化正样本的余弦相似度,
最小化负样本的余弦相似度。
懂???三种训练方法的本质都是让用户和正样本物品的余弦相似度大,而用户跟负样本的余弦相似度小。
我已经讲完了双塔模型和三种训练方式,最后总结一下这本文讲过的内容,
双塔模型,顾名思义有两个塔,一个用户塔,一个物品塔,
两个塔各输出一个向量,
向量的余线相似度就是对兴趣的预估值,这个值越大,用户就越有可能对物品感兴趣。
有三种训练双塔模型的方式,
一种是pointwise,每次用一个用户和一个物品,物品可以是正样本也可以是负样本,
第二种训练方式是pair wise,每次取一个用户一个这样本物品,一个负样本物品
训练的目标是最小化Triplely hinge loss和Triplely logistic loss,
也就是让正样本的余弦相似度尽量大,与负样本余弦相似度尽量小。
第三种训练方法是list wise,每次取一个用户,一个正样本物品,很多个负样本物品
训练的时候用soft max激活函数
用交叉熵损失函数训练,也是鼓励正样本余弦相似度尽量大
负样本余弦相似度尽量小
看清楚召回是后端特征融合,而精排是前端特征融合
在结束之前,我们讨论一种错误的召回模型的设计,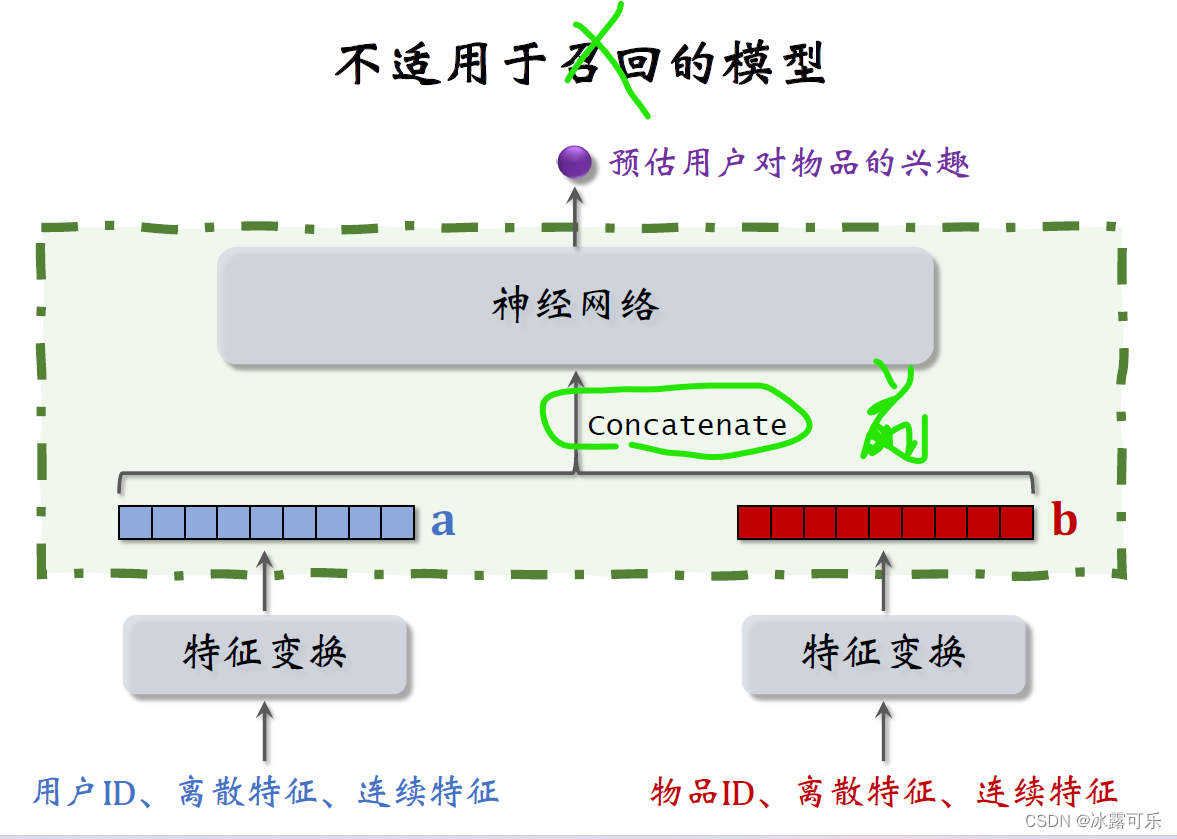
大家一看到这种结构就应该知道这是粗排或者精排的模型,而不是召回的模型,这种模型没办法应用到召回。
下面这块结构跟双塔模型是一样的,都是分别提取用户和物品的特征,得到两个特征向量,
但是上层的结构就不一样了,这里直接把两个向量做concat。
然后输入一个神经网络,神经网络可以有很多层,这种神经网络结构属于前期融合,
在进入全连接层之前就把特征向量拼起来了。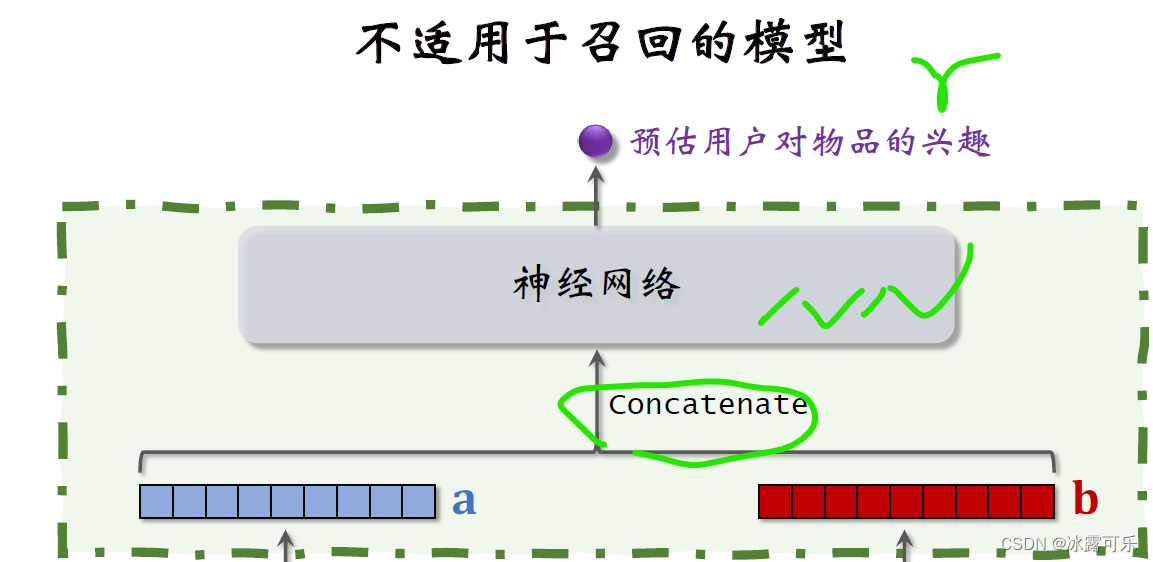
看一下精排模型图中的神经网络,神经网络最终输出一个实数作为预估分数,表示用户对物品的兴趣,
把两个特征向量拼起来输入神经网络,这种前期融合的模型不适用于召回。
这种前期融合的神经网络结构跟前面讲的双塔模型有很大区别,双塔模型属于后期融合,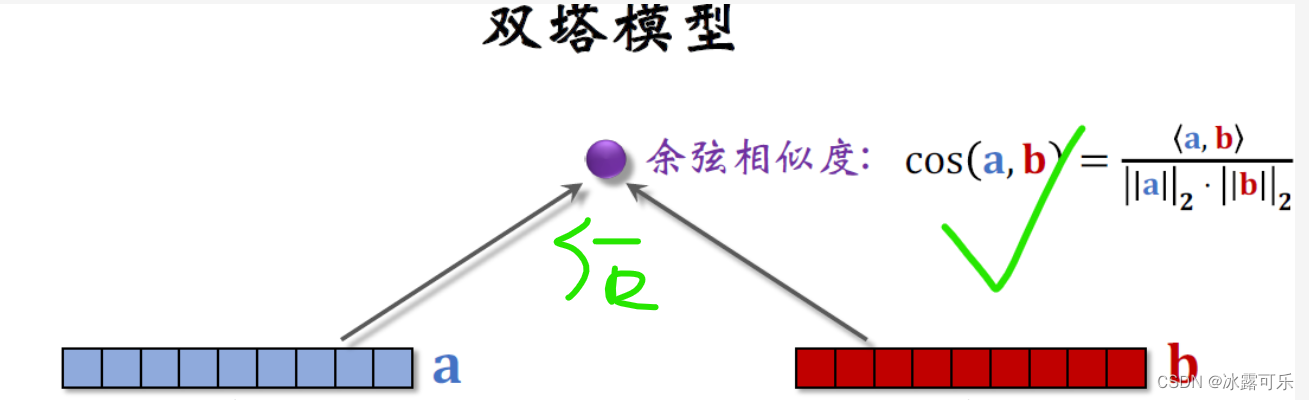
两个塔在最终输出相似度的时候才融合起来。【前面压根没用神经网络去输出相似度哦】
假如把这种精排的模型用于召回,就必须把所有物品的特征都挨个输入模型,预估用户对所有物品的兴趣。
假设一共有1亿个物品,每给用户做一次召回,就要把这个模型跑1亿次,这种计算量显然不可行。
如果用这种模型,就没办法用近似最近邻查找来加速计算。
这种模型通常用于精排排序,即从几千个候选物品中选出几百个,计算量不会太大。
以后大家一看到这种前期融合的模型,就要明白这是排序模型,不是召回模型。
召回只能用双塔那样的后期融合模型。
okay,今天讲解了双塔模型的神经网络结构和三种训练的方式。
做训练的时候需要选择正负样本,这部分内容下文我再详细给你说。
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:三种训练方法的本质都是让用户和正样本物品的余弦相似度大,而用户跟负样本的余弦相似度小。前期融合的模型是排序模型,不是召回模型,召回模型都是后期融合的,直接求余弦相似度,表示用户对它的喜好程度。
边栏推荐
猜你喜欢
Kubernetes 网络入门

Creative code confession
超越YOLO5-Face | YOLO-FaceV2正式开源Trick+学术点拉满

如何发现一个有价值的 GameFi?
oracle create tablespace

LiveVideoStackCon 2022 Shanghai Station opens tomorrow!
day14--postman interface test
新来个技术总监,把DDD落地的那叫一个高级,服气
pytorch的使用:卷积神经网络模块
If capturable=False, state_steps should not be CUDA tensors
随机推荐
Exercise: Selecting a Structure (1)
GCC: compile-time library path and runtime library path
软件测试技术之最有效的七大性能测试技术
蓝牙Mesh系统开发四 ble mesh网关节点管理
Software testing interview questions: Have you used some tools for software defect (Bug) management in your past software testing work? If so, please describe the process of software defect (Bug) trac
oracle create user
深度学习:使用nanodet训练自己制作的数据集并测试模型,通俗易懂,适合小白
第十四天&postman
如何创建rpm包
Memory Forensics Series 1
Countdown to 1 day!From August 2nd to 4th, I will talk with you about open source and employment!
Binary tree [full solution] (C language)
tcp中的三次握手与四次挥手
GCC:编译时库路径和运行时库路径
3. pcie.v file
PCIe 核配置
Is DDOS attack really unsolvable?Do not!
GCC: paths to header and library files
接口自动化测试框架postman tests常用方法
2022 Hangzhou Electric Power Multi-School Session 3 K Question Taxi