当前位置:网站首页>Use of pytorch: Convolutional Neural Network Module
Use of pytorch: Convolutional Neural Network Module
2022-08-05 00:58:00 【The romance of cherry blossoms】
1.读取数据
- 分别构建训练集和测试集(验证集)
- DataLoader来迭代取数据
- 使用transforms将数据转换为tensor格式
# 定义超参数
input_size = 28 #图像的总尺寸28*28
num_classes = 10 #标签的种类数
num_epochs = 3 #训练的总循环周期
batch_size = 64 #一个撮(批次)的大小,64张图片
# 训练集
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
# 测试集
test_dataset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# 构建batch数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
1.Convolutional Neural Network Module
pytorch与tensorflow 2相比,pytorch更注重过程,pytochThe convolution module needs to specify the number of input channels and the number of output channels,The total number of parameters of the convolution kernel is 卷积核K x 卷积核K x 输入通道数 x 输出通道数,卷积模块padding也需要自己计算,如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1,pytochWhen calculating the feature size of the next layer,The principle of rounding down is used,另外pytorch特征维度为batch*channels*h*w,channels在第二维度.
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)
nn.Conv2d(
in_channels=1, # 灰度图
out_channels=16, # 要得到几多少个特征图
kernel_size=5, # 卷积核大小
stride=1, # 步长
padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1
), # 输出的特征图为 (16, 28, 28)
nn.ReLU(), # relu层
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14)
)
self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)
nn.ReLU(), # relu层
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2), # 输出 (32, 7, 7)
)
self.conv3 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(32, 64, 5, 1, 2), # 输出 (32, 14, 14)
nn.ReLU(), # 输出 (32, 7, 7)
)
self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层得到的结果
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7)
output = self.out(x)
return output3.训练网络模型
Define accuracy as a validation set evaluation metric
def accuracy(predictions, labels):
pred = torch.max(predictions.data, 1)[1]
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels)
# 实例化
net = CNN()
#损失函数
criterion = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法
#开始训练循环
for epoch in range(num_epochs):
#当前epoch的结果保存下来
train_rights = []
for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环
net.train()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = accuracy(output, target)
train_rights.append(right)
if batch_idx % 100 == 0:
net.eval()
val_rights = []
for (data, target) in test_loader:
output = net(data)
right = accuracy(output, target)
val_rights.append(right)
#准确率计算
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(
epoch, batch_idx * batch_size, len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.data,
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))当前epoch: 0 [0/60000 (0%)] 损失: 2.300918 训练集准确率: 10.94% 测试集正确率: 10.10% 当前epoch: 0 [6400/60000 (11%)] 损失: 0.204191 训练集准确率: 78.06% 测试集正确率: 93.31% 当前epoch: 0 [12800/60000 (21%)] 损失: 0.039503 训练集准确率: 86.51% 测试集正确率: 96.69% 当前epoch: 0 [19200/60000 (32%)] 损失: 0.057866 训练集准确率: 89.93% 测试集正确率: 97.54% 当前epoch: 0 [25600/60000 (43%)] 损失: 0.069566 训练集准确率: 91.68% 测试集正确率: 97.68% 当前epoch: 0 [32000/60000 (53%)] 损失: 0.228793 训练集准确率: 92.85% 测试集正确率: 98.18% 当前epoch: 0 [38400/60000 (64%)] 损失: 0.111003 训练集准确率: 93.72% 测试集正确率: 98.16% 当前epoch: 0 [44800/60000 (75%)] 损失: 0.110226 训练集准确率: 94.28% 测试集正确率: 98.44% 当前epoch: 0 [51200/60000 (85%)] 损失: 0.014538 训练集准确率: 94.78% 测试集正确率: 98.60% 当前epoch: 0 [57600/60000 (96%)] 损失: 0.051019 训练集准确率: 95.14% 测试集正确率: 98.45% 当前epoch: 1 [0/60000 (0%)] 损失: 0.036383 训练集准确率: 98.44% 测试集正确率: 98.68% 当前epoch: 1 [6400/60000 (11%)] 损失: 0.088116 训练集准确率: 98.50% 测试集正确率: 98.37% 当前epoch: 1 [12800/60000 (21%)] 损失: 0.120306 训练集准确率: 98.59% 测试集正确率: 98.97% 当前epoch: 1 [19200/60000 (32%)] 损失: 0.030676 训练集准确率: 98.63% 测试集正确率: 98.83% 当前epoch: 1 [25600/60000 (43%)] 损失: 0.068475 训练集准确率: 98.59% 测试集正确率: 98.87% 当前epoch: 1 [32000/60000 (53%)] 损失: 0.033244 训练集准确率: 98.62% 测试集正确率: 99.03% 当前epoch: 1 [38400/60000 (64%)] 损失: 0.024162 训练集准确率: 98.67% 测试集正确率: 98.81% 当前epoch: 1 [44800/60000 (75%)] 损失: 0.006713 训练集准确率: 98.69% 测试集正确率: 98.17% 当前epoch: 1 [51200/60000 (85%)] 损失: 0.009284 训练集准确率: 98.69% 测试集正确率: 98.97% 当前epoch: 1 [57600/60000 (96%)] 损失: 0.036536 训练集准确率: 98.68% 测试集正确率: 98.97% 当前epoch: 2 [0/60000 (0%)] 损失: 0.125235 训练集准确率: 98.44% 测试集正确率: 98.73% 当前epoch: 2 [6400/60000 (11%)] 损失: 0.028075 训练集准确率: 99.13% 测试集正确率: 99.17% 当前epoch: 2 [12800/60000 (21%)] 损失: 0.029663 训练集准确率: 99.26% 测试集正确率: 98.39% 当前epoch: 2 [19200/60000 (32%)] 损失: 0.073855 训练集准确率: 99.20% 测试集正确率: 98.81% 当前epoch: 2 [25600/60000 (43%)] 损失: 0.018130 训练集准确率: 99.16% 测试集正确率: 99.09% 当前epoch: 2 [32000/60000 (53%)] 损失: 0.006968 训练集准确率: 99.15% 测试集正确率: 99.11%
边栏推荐
- ### Error querying database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionExcep
- 10年测试经验,在35岁的生理年龄面前,一文不值
- CNI(Container Network Plugin)
- Binary tree [full solution] (C language)
- Bit rate vs. resolution, which one is more important?
- 2021年11月网络规划设计师上午题知识点(上)
- Difference between MBps and Mbps
- 码率vs.分辨率,哪一个更重要?
- 5.PCIe官方示例
- 进程间通信和线程间通信
猜你喜欢
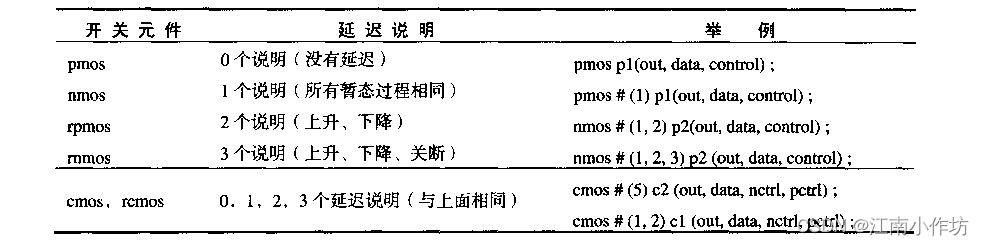
第十一章 开关级建模

【FreeRTOS】FreeRTOS与stm32内置堆栈的占用情况
Jin Jiu Yin Shi Interview and Job-hopping Season; Are You Ready?
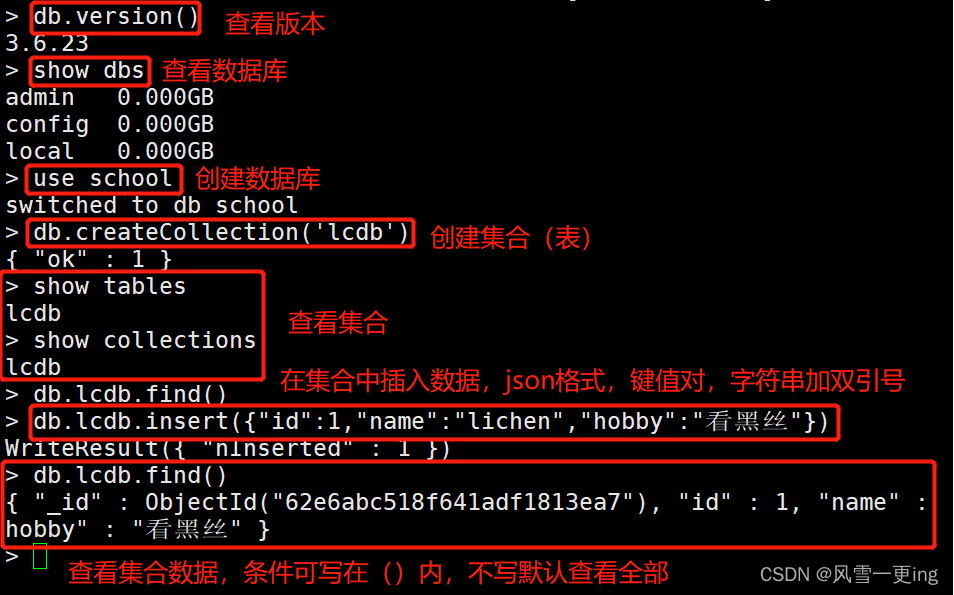
MongoDB搭建及基础操作
Redis visual management software Redis Desktop Manager2022

深度学习:使用nanodet训练自己制作的数据集并测试模型,通俗易懂,适合小白
多线程涉及的其它知识(死锁(等待唤醒机制),内存可见性问题以及定时器)
OPENWIFI实践1:下载并编译SDRPi的HDL源码
![[230] Execute command error after connecting to Redis MISCONF Redis is configured to save RDB snapshots](/img/fa/5bdc81b1ebfc22d31f42da34427f3e.png)
[230] Execute command error after connecting to Redis MISCONF Redis is configured to save RDB snapshots

【Redis】Linux下Redis安装
随机推荐
Getting Started with Kubernetes Networking
JWT简单介绍
More than 2022 cattle school training topic Link with the second L Level Editor I
阶段性测试完成后,你进行缺陷分析了么?
matlab 采用描点法进行数据模拟和仿真
node uses redis
Memory Forensics Series 1
pytorch的使用:卷积神经网络模块
蓝牙Mesh系统开发四 ble mesh网关节点管理
2022 Hangzhou Electric Multi-School 1004 Ball
Software testing interview questions: What stages should a complete set of tests consist of?
执掌图表
快速批量修改VOC格式数据集标签的文件名,即快速批量修改.xml文件名
Software testing interview questions: test life cycle, the test process is divided into several stages, and the meaning of each stage and the method used?
OPENWIFI实践1:下载并编译SDRPi的HDL源码
4. PCIe interface timing
Creative code confession
手把手基于YOLOv5定制实现FacePose之《YOLO结构解读、YOLO数据格式转换、YOLO过程修改》
oracle create user
僵尸进程和孤儿进程