当前位置:网站首页>深度学习原理学习小结 - Self-Attention/Transformer
深度学习原理学习小结 - Self-Attention/Transformer
2022-08-05 00:51:00 【WBZhang2022】
文章目录
深度学习原理学习小结 - Self-Attention/Transformer
Self-Attention基本原理
引入
Self-Attention(译为:自注意力机制),最早在自然语言处理研究领域中提出来的,其目的是根据序列数据前驱后继的语义关系设置对应的关注权重的方法,其基本构想如图所示:序列中每一个“个体”都需要考虑所有排在它前面的“个体”,以及排在它后面的所有“个体”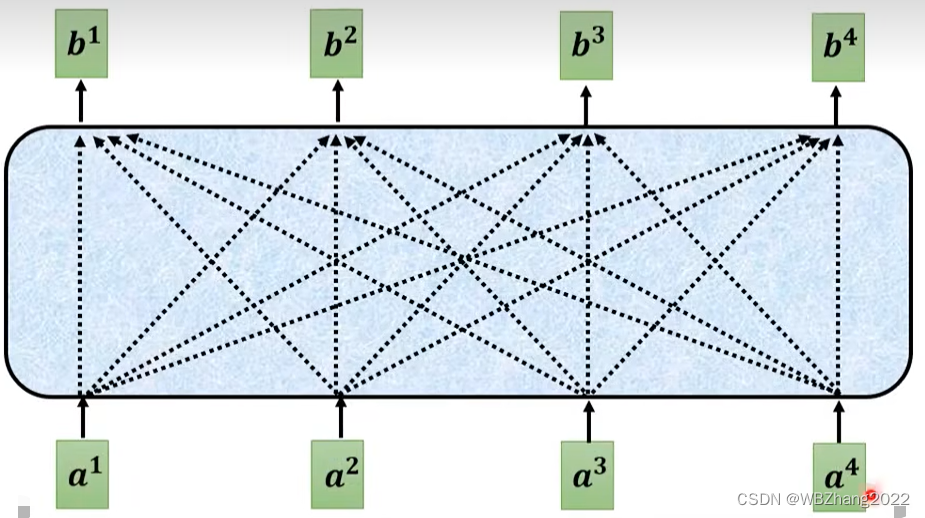
核心概念
至于 a 1 , a 2 , a 3 , a 4 a_1,a_2,a_3,a_4 a1,a2,a3,a4 如何映射到 b 1 , b 2 , b 3 , b 4 b_1,b_2,b_3,b_4 b1,b2,b3,b4我们需要事先直到几组基本概念:
- q u e r y query query (简写 q q q), k e y key key (简写 k k k), v a l u e value value (简写 v v v): q q q 我们可以表示为当前在处理序列数据中正在处理的“个体”; k k k 我们可以表示为每一个和 q q q 进行比对的“个体”,通常指的是序列数据中所有的“个体”; v v v 我们可以表示为当前在处理序列数据中正在处理的“个体”对应的标签;
- Dot-Product 计算方法:这是计算注意力权重的常用方法,通过对 q q q 和 k k k 进行相关性比较(站在数学的角度来讲就是两个向量的数量积)得到 α \alpha α
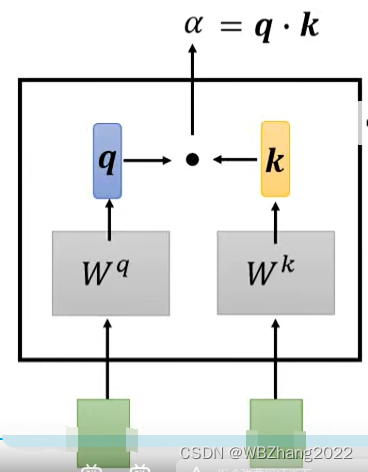
计算方法
我们以输出 b 1 b_1 b1 为例子详细地介绍注意力分数以及 b 1 b_1 b1 是如何计算的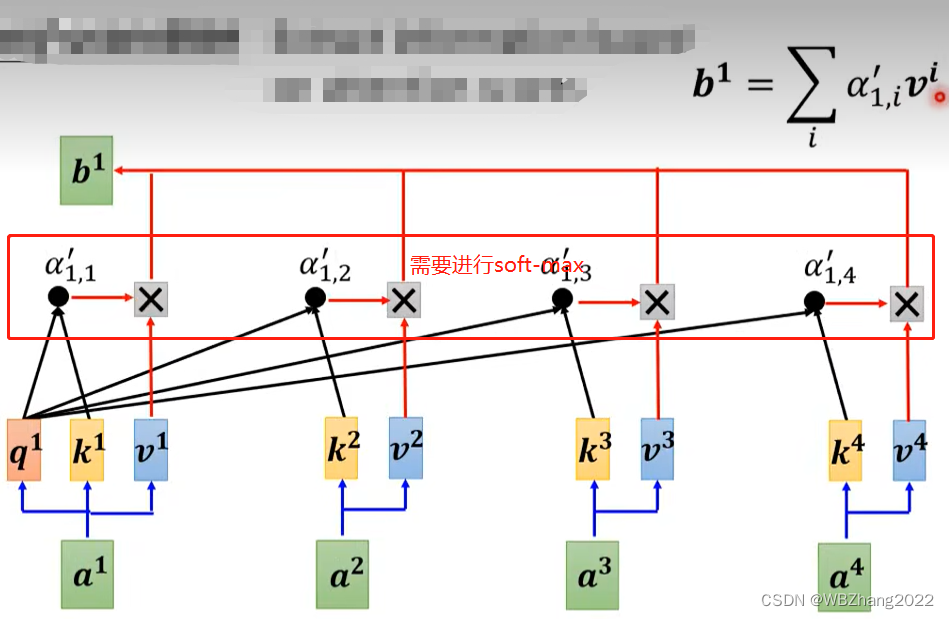
将原始输入序列通过 W q W^q Wq, W k W^k Wk, W v W^v Wv 权重矩阵进行线性变换得到 q q q, k k k, v v v,其中 W q W^q Wq, W k W^k Wk, W v W^v Wv ,可以视为神经网络模型中的模型参数,可以通过常用的优化算法得到一组合适的模型参数
q 1 = W q ⋅ a 1 k 1 = W k ⋅ k 1 k 2 = W k ⋅ a 2 q 3 = W k ⋅ a 3 k 4 = W k ⋅ a 4 q^1=W^q\cdot a^1\quad k^1=W^k\cdot k^1 \quad k^2=W^k\cdot a^2 \quad q^3=W^k\cdot a^3 \quad k^4=W^k \cdot a^4 q1=Wq⋅a1k1=Wk⋅k1k2=Wk⋅a2q3=Wk⋅a3k4=Wk⋅a4
以 a 1 a^1 a1 作为查找的“基准点”, a 2 a^2 a2, a 3 a^3 a3, a 4 a^4 a4 作为语义相似度对比 (注意也要自己和自己对比)
α 1 , 1 = q 1 ⋅ k 1 α 1 , 2 = q 1 ⋅ k 2 α 1 , 3 = q 1 ⋅ k 3 α 1 , 4 = q 1 ⋅ k 4 \alpha_{1,1}=q^{1} \cdot k^{1}\quad \alpha_{1,2}=q^{1} \cdot k^{2}\quad \alpha_{1,3}=q^1\cdot k^3\quad \alpha_{1,4}=q^{1}\cdot k^4 α1,1=q1⋅k1α1,2=q1⋅k2α1,3=q1⋅k3α1,4=q1⋅k4
将原始输入序列通过 W q W^q Wq, W k W^k Wk, W v W^v Wv 权重矩阵进行线性变换得到 q q q, k k k, v v v
q 1 = W q ⋅ a 1 k 1 = W k ⋅ k 1 k 2 = W k ⋅ a 2 k 3 = W k ⋅ a 3 k 4 = W k ⋅ a 4 q^1=W^q\cdot a^1\quad k^1=W^k\cdot k^1 \quad k^2=W^k\cdot a^2 \quad k^3=W^k\cdot a^3 \quad k^4=W^k \cdot a^4 q1=Wq⋅a1k1=Wk⋅k1k2=Wk⋅a2k3=Wk⋅a3k4=Wk⋅a4
对 α 1 , 1 \alpha_{1,1} α1,1, α 1 , 2 \alpha_{1,2} α1,2, α 1 , 3 \alpha_{1,3} α1,3, α 1 , 4 \alpha_{1,4} α1,4 进行soft-max 分别得到 α 1 , 1 ′ \alpha_{1,1}^{\prime} α1,1′, α 1 , 2 ′ \alpha_{1,2}^{\prime} α1,2′, α 1 , 3 ′ \alpha_{1,3}^{\prime} α1,3′, α 1 , 4 ′ \alpha_{1,4}^{\prime} α1,4′
将每个序列的标签 v v v 和对应注意力得分 α ′ \alpha^{\prime} α′ 相乘并累加
b 1 = ∑ j = 1 N α 1 , j ′ ⋅ v j b_1=\sum^{N}_{j=1}\alpha_{1,j}^{\prime}\cdot v_j b1=∑j=1Nα1,j′⋅vj
Transformer基本原理
在章节设置上,博主本人花了大篇幅讲解self-attention的目的在这一章节以及后续的章节就逐渐体现出来了,Transformer 模型本质就是一个带有 self-attention 的 Encoder-Decoder 模型,其模型架构如图所示: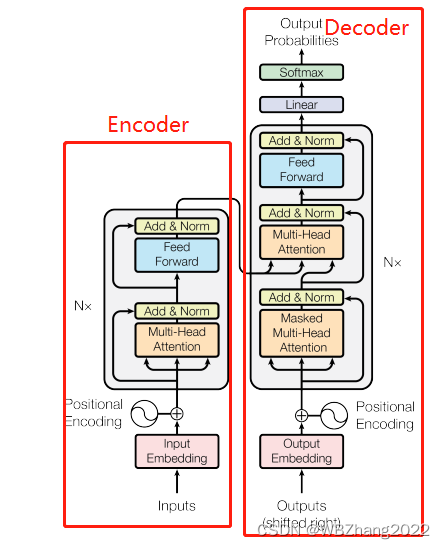
知识补充
addnorm:要把这一功能分为两个部分,一个是add,类似于残差神经网络的思想,输出的结果再加上输入的结果;另一部分是normalization对输出的数据进行归一化处理:归一化通常需要求出 x 1 , x 2 , . . . , x K x_1,x_2,...,x_K x1,x2,...,xK 的均值 m m m 和 标准差 σ \sigma σ,随后对每一个 x i x_i xi 进行 x i ′ = x i − m σ x_{i}^{\prime}=\frac{x_i-m}{\sigma} xi′=σxi−m
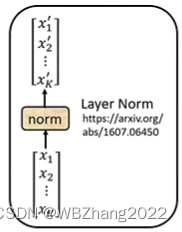
masked self-attention:简单的理解就是在序列数据中瞻前不顾后

编码器(Encoder)与 解码器(Decoder)
如图所示,无论是编码器部分还是解码器部分都是由一个个重复的小模块堆叠构成的;下面博主针对编码器和解码器构成的小模块进行解读:
- 编码器(Encoder)中的小模块:可以由两个阶段构成,第一个阶段经过self-attention模块中,随后self-attention得出来的结果需要进行一次残差处理;第二个阶段放入一个全连接层,随后也要进行一次残差处理;
- 解码器(Decoder)中的小模块:由三个阶段构成,第二个阶段和第三个阶段与编码器的模块趋于一致,唯一与编码器阶段不同的就是第一个阶段,它的自注意力机制采用的是 masked self-attention;
Transformer关键代码解读
多头注意力
- 多头注意力模型结构
【构造函数的参数说明】: k e y _ s i z e , q u e r y _ s i z e , v a l u e _ s i z e key\_size,query\_size,value\_size key_size,query_size,value_size,原始序列长度; n u m _ h i d d e n s num\_hiddens num_hiddens表示原始序列经过 W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv线性变换之后序列的长度, n u m _ h e a d s num\_heads num_heads表示的是 每一个 q u e r i e s , k e y , v a l u e queries,key,value queries,key,value拥有的分支数;
【注意力模块】:在第二部分讲述注意力模块原理中我们提到我们采用的是 D o t − p r o d u c t Dot-product Dot−product 方法class MultiHeadAttention(nn.Module): def __init__(self,key_size,query_size,value_size,num_hiddens, num_heads,dropout,bias=False,**kwargs): ## num_hiddens-输出的长度 num_heads-输出q,k,v对应的分支数 super(MultiHeadAttention,self).__init__(**kwargs) self.num_heads = num_heads self.attention = d2l.DotProductAttention(dropout) self.W_q = nn.Linear(query_size,num_hiddens,bias=bias) self.W_k = nn.Linear(key_size,num_hiddens,bias=bias) self.W_v = nn.Linear(value_size,num_hiddens,bias=bias) self.W_o = nn.Linear(num_hiddens,num_hiddens,bias=bias) def forward(self,queries,keys,values,valid_lens): queries = transpose_qkv(self.W_q(queries),self.num_heads) keys = transpose_qkv(self.W_k(keys),self.num_heads) values = transpose_qkv(self.W_v(values),self.num_heads) if valid_lens is not None: valid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0) output = self.attention(queries,keys,values,valid_lens) output_concat = transpose_output(output,self.num_heads) return self.W_o(output_concat) - 补充两个为了计算方便,要调整矩阵的尺寸的函数
## 修改尺寸便于计算 def transpose_qkv(X,num_heads): X = X.reshape(X.shape[0],X.shape[1],num_heads,-1) X = X.permute(0,2,1,3) return X.reshape(-1,X.shape[2],X.shape[3]) def transpose_output(X,num_heads): """逆转 transpose_qkv 函数的操作""" X = X.reshape(-1,num_heads,X.shape[1],X.shape[2]) X = X.permute(0,2,1,3) return X.reshape(X.shape[0],X.shape[1],-1)
Transfomer
基于位置的前馈网络:其实质就是两个全连接层
class PositionWiseFFN(nn.Module): def __init__(self,ffn_num_input,ffn_num_hiddens,ffn_num_output, **kwargs): super(PositionWiseFFN,self).__init__(**kwargs) self.dense1 = nn.Linear(ffn_num_input,ffn_num_hiddens) self.relu = nn.ReLU() self.dense2 = nn.Linear(ffn_num_hiddens,ffn_num_output) def forward(self,X): return self.dense2(self.relu(self.dense1(X)))使用残差链接和层归一化:类似于 ResNet 网络的思想,可以理解为将输入拷贝成两组相同的数据一组数据经过网络得到输出结果,另一组数据直接加上前一组数据经过网络输出得到的结果;
class AddNorm(nn.Module): def __init__(self,normalized_shape,dropout,**kwargs): super(AddNorm,self).__init__(**kwargs) self.dropout = nn.Dropout(dropout) self.ln = nn.LayerNorm(normalized_shape) def forward(self,X,Y): return self.ln(self.dropout(Y)+X)实现编码器中的模块:根据论文提出的 Transformer 的模型,编码器中的模块由两个阶段构成:第一个阶段是计算注意力分数,另一部分是送入全连接层;注意两者阶段都需要引入残差的思想,这样做在一定的程度上缓解了在训练过程中梯度消失的情况
## 实现编码器模块中的其中一层 class EncoderBlock(nn.Module): def __init__(self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias=False, **kwargs): super(EncoderBlock, self).__init__(**kwargs) ## 第一阶段 self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout, use_bias) self.addnorm1 = AddNorm(norm_shape, dropout) ## 第二阶段 # 实质上就是一个全连接神经网络 self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens) self.addnorm2 = AddNorm(norm_shape, dropout) def forward(self, X, valid_lens): Y = self.addnorm1(X, self.attention(X, X, X, valid_lens)) return self.addnorm2(Y, self.ffn(Y))Transformer 编码器:由若干个注意力+全连接网络块堆叠而成的,因此构造成 Transformer 的编码器我们首先将 position-encoding 化的序列和原始序列拼接起来,随后设置需要多少块注意力+全连接网络
## Transformer 编码器部分 class TransformerEncoder(d2l.Encoder): def __init__(self, vocab_size, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, use_bias=False, **kwargs): super(TransformerEncoder, self).__init__(**kwargs) self.num_hiddens = num_hiddens self.embedding = nn.Embedding(vocab_size, num_hiddens) self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout) ## 设置编码器部分需要几个模块堆叠 self.blks = nn.Sequential() for i in range(num_layers): self.blks.add_module("block"+str(i), EncoderBlock(key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias)) def forward(self, X, valid_lens, *args): ## 经过position encoding与原始序列数据进行拼接 X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens)) self.attention_weights = [None] * len(self.blks) for i, blk in enumerate(self.blks): X = blk(X, valid_lens) ## 计算每一次注意力分数 self.attention_weights[i] = blk.attention.attention.attention_weights return X实现解码器中的一层:根据论文提出的 Transformer 的模型,区别于解码器中第一阶段的Multi-Head Attention,它采用的是Masked,第二阶段与第三阶段与编码器模块一致,需要注意的是编码器与解码器之间的连接处数据的传递
class DecoderBlock(nn.Module): def __init__(self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i, **kwargs): super(DecoderBlock, self).__init__(**kwargs) self.i = i self.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout) self.addnorm1 = AddNorm(norm_shape, dropout) self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout) self.addnorm2 = AddNorm(norm_shape, dropout) self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens) self.addnorm3 = AddNorm(norm_shape, dropout) def forward(self,X,state): enc_outputs,enc_valid_lens = state[0],state[1] if state[2][self.i] is None: key_values = X else: key_values = torch.cat((state[2][self.i],X),axis=1) state[2][self.i] = key_values ## 设置网络是否为训练模式,如果是训练模式是拿句子的目标值进行参考而不是生成序列 if self.training: batch_size,num_steps,_ = X.shape dec_valid_lens = torch.arange(1,num_steps+1, device=X.device).repeat(batch_size,1) else: dec_valid_lens = None X2 = self.attention1(X,key_values,key_values,dec_valid_lens) Y = self.addnorm1(X,X2) Y2 = self.attention2(Y,enc_outputs,enc_outputs,enc_valid_lens) Z = self.addnorm2(Y,Y2) return self.addnorm3(Z,self.ffn(Z)),stateTransformer 解码器:由若干个解码器块堆叠而成的,只需设置需要多少块解码器块
## 实现一个完整的Transformer Encoder模块 class TransformerDecoder(d2l.AttentionDecoder): def __init__(self, vocab_size, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, **kwargs): super(TransformerDecoder, self).__init__(**kwargs) self.num_hiddens = num_hiddens self.num_layers = num_layers self.embedding = nn.Embedding(vocab_size, num_hiddens) self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout) self.blks = nn.Sequential() for i in range(num_layers): self.blks.add_module("block"+str(i), DecoderBlock(key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i)) self.dense = nn.Linear(num_hiddens, vocab_size) def init_state(self, enc_outputs, enc_valid_lens, *args): return [enc_outputs, enc_valid_lens, [None] * self.num_layers] def forward(self, X, state): X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens)) self._attention_weights = [[None] * len(self.blks) for _ in range (2)] for i, blk in enumerate(self.blks): X, state = blk(X, state) # 解码器自注意力权重 self._attention_weights[0][i] = blk.attention1.attention.attention_weights # “编码器-解码器”自注意力权重 self._attention_weights[1][i] = blk.attention2.attention.attention_weights return self.dense(X), state @property def attention_weights(self): return self._attention_weights训练过程我们可以先把编码器解码器组合起来组合成一个模型,调用函数:
d2l.EncoderDecoder(encoder,decoder)来解决,随后调用d2l.train_seq2seq函数训练模型
边栏推荐
- [idea] idea configures sql formatting
- GCC:编译时库路径和运行时库路径
- Software testing interview questions: What are the strategies for system testing?
- 深度学习:使用nanodet训练自己制作的数据集并测试模型,通俗易懂,适合小白
- tiup update
- 软件测试面试题:您如何看待软件过程改进?在您曾经工作过的企业中,是否有一些需要改进的东西呢?您期望的理想的测试人员的工作环境是怎样的?
- sqlite--nested exception is org.apache.ibatis.exceptions.PersistenceException:
- ora-00604 ora-02429
- SV class virtual method of polymorphism
- 3. pcie.v 文件
猜你喜欢

](/img/4d/2d81dc75433c23c5ba6b31453396f0.png)




随机推荐
Software testing interview questions: the difference and connection between black box testing, white box testing, and unit testing, integration testing, system testing, and acceptance testing?
2022牛客多校第三场 A Ancestor
软件测试面试题:您以往所从事的软件测试工作中,是否使用了一些工具来进行软件缺陷(Bug)的管理?如果有,请结合该工具描述软件缺陷(Bug)跟踪管理的流程?
金九银十面试跳槽季;你准备好了吗?
软件测试面试题:什么是软件测试?软件测试的目的与原则?
Software testing interview questions: Have you used some tools for software defect (Bug) management in your past software testing work? If so, please describe the process of software defect (Bug) trac
matlab 采用描点法进行数据模拟和仿真
软件测试面试题:手工测试与自动测试有哪些区别?
node uses redis
软件测试面试题:系统测试的策略有?
Lattice PCIe Learning 1
Theory of Software Fundamentals
could not build server_names_hash, you should increase server_names_hash_bucket_size: 32
leetcode: 266. All Palindromic Permutations
[idea] idea configures sql formatting
2022 Hangzhou Electric Power Multi-School Session 3 Question B Boss Rush
2022 Multi-school Second Session K Question Link with Bracket Sequence I
TinyMCE disable escape
PCIe Core Configuration
Dynamic Programming/Knapsack Problem Summary/Summary - 01 Knapsack, Complete Knapsack