当前位置:网站首页>Zero shot image retrieval (zero sample cross modal retrieval)
Zero shot image retrieval (zero sample cross modal retrieval)
2022-07-25 12:02:00 【Shangshanxianger】
The last blog post briefly sorted Meta learning and less sample learning , This article focuses on sorting out several articles that use zero sample learning to do retrieval . The difficulty of this problem is that human sketches are used as queries to retrieve photos from invisible categories :
- Sketches and pictures differ greatly across modal domains .sketch Only the outline of the object , And image Compared with little information .
- Because different people have different painting styles ,sketch The intra class variance of is also large .
- How to adapt to large-scale retrieval , Adaptation from Unseen Image retrieved from .

A Zero-Shot Framework for Sketch Based Image Retrieval
come from ECCV2018. The main idea is to use generative models to solve problems , The advantage of this is by generating models , You can add some sketch Information , Thus, the model can learn to draw the outline of the sketch 、 Local shape and other features are associated with the corresponding features of the image . The specific model is shown in the figure above , On the left and right are the author's two architectures CVAE and CAAE, That is, two mainstream generation models are used for testing (VAE and GAN).
- CVAE It's using Conditional variational self encoder , That is, a certain feature as a condition to participate in VAE Reconstruction of , Then you can get the loss directly L = − D K L ( a ( z ∣ x i m g , x s k e t c h ) ∣ ∣ p ( z ∣ x s k e t c h ) ) + E [ l o g p ( x i m g ∣ z , x s k e t c h ) ] L=-D_{KL}(a(z|x_{img,x_{sketch}})||p(z|x_{sketch}))+E[log p(x_{img}|z,x_{sketch})] L=−DKL(a(z∣ximg,xsketch)∣∣p(z∣xsketch))+E[logp(ximg∣z,xsketch)] In order to retain sketch Potential alignment relationship , Join the reconstruction loss, That is... In the picture regularrization loss: L r e c = λ ∣ ∣ f N N ( x i m g ′ ) − x s k e t c h ∣ ∣ 2 2 L_{rec}=\lambda||f_{NN}(x'_{img})-x_{sketch}||^2_2 Lrec=λ∣∣fNN(ximg′)−xsketch∣∣22
- CAAE Is to use an antagonistic self encoder . alike , Continue to use GAN The idea of confrontation , The previous feature generator acts as a generator G To minimize losses E z [ l o g p ( x i m g ∣ z , x s k e t c h ) ] + E i m g [ l o g ( 1 − D ( E ( x i m g ) ) ) ] E_z[log p(x_{img}|z,x_{sketch})]+E_{img}[log (1-D(E(x_{img})))] Ez[logp(ximg∣z,xsketch)]+Eimg[log(1−D(E(ximg)))] And the discriminator D Maximize losses E [ l o g [ D ( z ) ] ] + E i m g [ l o g ( 1 − D ( E ( x i m g ) ) ) ] E_[log[D(z)]]+E_{img}[log (1-D(E(x_{img})))] E[log[D(z)]]+Eimg[log(1−D(E(ximg)))] Also add reconstruction loss L r e c = λ ∣ ∣ f N N ( x i m g ′ ) − x s k e t c h ∣ ∣ 2 2 L_{rec}=\lambda||f_{NN}(x'_{img})-x_{sketch}||^2_2 Lrec=λ∣∣fNN(ximg′)−xsketch∣∣22
The author's experiment proves CVAE Than CAAE Better , Probably because of CAAE The training of confrontation model is unstable .

Semantically Tied Paired Cycle Consistency for Zero-Shot Sketch-based Image Retrieval
come from CVPR2019. Its complex structure is shown in the figure above , share 4 Generators and 3 A discriminator .
- The four generators have their own functions , Learn mapping semantics in different directions , It can take into account the learning of semantics in the mode , It can also complete cross modal semantic alignment G s k : X − > S , G i m : Y − > S , F s k : S − > X , F i m : S − > Y G_{sk}:X->S, G_{im}:Y->S, F_{sk}:S->X, F_{im}:S->Y Gsk:X−>S,Gim:Y−>S,Fsk:S−>X,Fim:S−>Y
- The discriminator is also corresponding to distinguishing its own characteristics in the two modes , There is another one for distinguishing the characteristics between modes .
What's more interesting is that Cycle Consistency Loss, This blogger is in Cross modal Retrieval Have been sorted out , It's an old way to solve cross modal . So that features can not only be mapped to the corresponding semantic space , It can also map back to the original feature space from the semantic space , This can strengthen the learning of characteristics . L c y c = E [ ∣ ∣ F s k ( G s k ( x ) ) − x ∣ ∣ 1 ] + E [ ∣ ∣ G s k ( F s k ( s ) ) − s ∣ ∣ 1 ] L_{cyc}=E[||F_{sk}(G_{sk}(x))-x||_1]+E[||G_{sk}(F_{sk}(s))-s||_1] Lcyc=E[∣∣Fsk(Gsk(x))−x∣∣1]+E[∣∣Gsk(Fsk(s))−s∣∣1]

Doodle to Search Practical Zero-Shot Sketch-based Image Retrieval
come from CVPR2019. Or try to find a mapping relationship , Just introduce GRL Provide Reward To guide embedding . There will be three losses :
- Triplet loss, Construct positive case pairs and negative case pairs , Then this makes pair The score of belonging to the same class is higher than that of different classes .
- Domain loss, Use GRL Project the features of the two modes into the same space , To get a domain independent embedding .
- Semantic loss, There will be introduction word Embedding To strengthen the connection between the two . That is, mandatory embedding contains semantic information by reconstructing word meaning .
The final loss function consists of three of them : L = α 1 L t + α 2 L d + α 3 L s L=\alpha_1L_t+\alpha_2L_d+\alpha_3L_s L=α1Lt+α2Ld+α3Ls

Zero-Shot Sketch-Based Image Retrieval via Graph Convolution Network
come from AAAI2020. The author believes that the above generation models , For generating possible image features, side information cannot be effectively used , And unstable . So a GCN Model to alleviate the above shortcomings . The model diagram is shown above ,SketchGCN The model contains three subnetworks , Coding network 、 Semantic maintenance network and semantic reconstruction network .
- Coding networks try to embed sketches and images into a common semantic space .
- The semantic preserving network takes features as input , Use side information to force them to maintain category level relationships . Here is mainly to learn the relationship between categories ( After all, the key to the task is from seen To unseen Learning from , So category knowledge is very important ), To transfer knowledge . So here we directly use the feature information to compose the picture, and then GCN That's it . H ( l + 1 ) = σ ( A ′ H ( l ) W ( l ) ) H^{(l+1)}=\sigma(A'H^{(l)}W^{(l)}) H(l+1)=σ(A′H(l)W(l)) The graph construction here actually uses semantic features to calculate similarity a i , j = e − ∣ ∣ s i − s j ∣ ∣ 2 2 t a^{i,j}=e^{-\frac{||s_i-s_j||^2_2}{t}} ai,j=e−t∣∣si−sj∣∣22
- The semantic reconstruction network further forces the extracted features to retain their semantic relationships . Here is the same as the previous models , use CVAE, restructure loss, semantics loss And so on to constrain the learning of space .

Learning Cross-Aligned Latent Embedding for Zero-Shot Cross-Modal Retrieval
come from AAAI2020, This work is to use text to cross modal retrieval . Methods do not directly use class embedding as semantic space , And trained a multimode variational automatic encoder (VAE), The potential embedding of learning , Especially with class As bridge, Then align by matching their parametric distributions . The model is shown above , First learn one for each of these three modes VAE, then image and text Do the conversion of circular consistency , Then rebuild each other .
What is more meaningful is that two constraints are made in the alignment of transmembrane space :
- Take class embedding as a bridge , Align the potentially embedded multivariate Gaussian distribution in pairs . Specifically, I counted one 2-Wasserstein distance.
- Because the association between image and text patterns is built implicitly through class embedding , Therefore, another scheme is considered here to explicitly enhance the semantic relevance of these two patterns . Specifically, forget maximum mean discrepancy (MMD).
final loss Or the above loss The sum of .
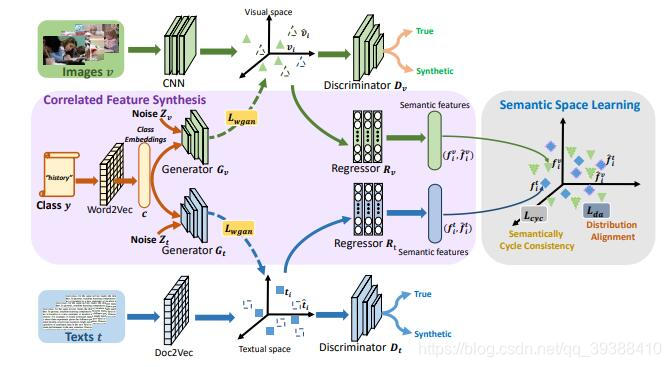
Correlated Features Synthesis and Alignment for Zero-Shot Cross-Modal Retrieval
come from SIGIR2020, The author is the same as the last article , So the practice is similar , But will VAE Instead of GAN, Then do work within and between modes .
The model architecture diagram is shown above , First pair class and image Between doing WGAN, Right again class and text do WGAN( So in fact, the point similar to the previous article is that class As a bridge ), Then it is also calculated by respective discriminators loss, Then calculate unified Semantic Space Cyclic consistency and distribution alignment loss, Finally, it's all about the whole episode loss.
边栏推荐
- 软件测试阶段的风险
- 【AI4Code】《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
- Power BI----这几个技能让报表更具“逼格“
- JS中的函数
- Learning to Pre-train Graph Neural Networks(图预训练与微调差异)
- 【云驻共创】AI在数学界有哪些作用?未来对数学界会有哪些颠覆性影响?
- 30 sets of Chinese style ppt/ creative ppt templates
- LeetCode 50. Pow(x,n)
- pycharm连接远程服务器ssh -u 报错:No such file or directory
- 【AI4Code】《Pythia: AI-assisted Code Completion System》(KDD 2019)
猜你喜欢

【Debias】Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in RS(KDD‘21)
【Debias】Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in RS(KDD‘21)

What is the global event bus?

Start with the development of wechat official account

brpc源码解析(一)—— rpc服务添加以及服务器启动主要过程

dirReader.readEntries 兼容性问题 。异常错误DOMException

JS process control

Heterogeneous graph neural network for recommendation system problems (ackrec, hfgn)

【6篇文章串讲ScalableGNN】围绕WWW 2022 best paper《PaSca》

对比学习的应用(LCGNN,VideoMoCo,GraphCL,XMC-GAN)
随机推荐
Solutions to the failure of winddowns planning task execution bat to execute PHP files
php 一台服务器传图片到另一台上 curl post file_get_contents保存图片
PHP curl post x-www-form-urlencoded
【GCN-CTR】DC-GNN: Decoupled GNN for Improving and Accelerating Large-Scale E-commerce Retrieval WWW22
Meta learning (meta learning and small sample learning)
基于TCP/IP在同一局域网下的数据传输
程序员送给女孩子的精美礼物,H5立方体,唯美,精致,高清
Brpc source code analysis (VIII) -- detailed explanation of the basic class eventdispatcher
微星主板前面板耳机插孔无声音输出问题【已解决】
Meta-learning(元学习与少样本学习)
【GCN-RS】Region or Global? A Principle for Negative Sampling in Graph-based Recommendation (TKDE‘22)
Application of comparative learning (lcgnn, videomoco, graphcl, XMC GaN)
LeetCode 50. Pow(x,n)
Transformer variants (routing transformer, linformer, big bird)
Functions in JS
Introduction to redis
brpc源码解析(七)—— worker基于ParkingLot的bthread调度
R语言ggplot2可视化:使用ggpubr包的ggviolin函数可视化小提琴图、设置add参数在小提琴内部添加抖动数据点以及均值标准差竖线(jitter and mean_sd)
Javescript loop
JaveScript循环