当前位置:网站首页>Work report of epidemic data analysis platform [1] data collection
Work report of epidemic data analysis platform [1] data collection
2022-06-12 04:13:00 【m0_ fifty-five million six hundred and seventy-five thousand ei】
Data collection and acquisition
edit :
First of all, I'll post the relevant information fastcode:
1. BeautifulSoup Of find Method
# for example
soup.find('a') # Look by tag name
soup.find(id='link1') # Find... By attributes
soup.find(attrs={
'id':'link1'}) # Find... By attributes
soup.find(test='aaa') # Find... Based on the label text content
2. Tag object
find Method returns Tag object , Has the following properties
Tag Object corresponds to the in the original document html label
name: Tag name
attrs: Key and value of tag attribute
text: The string text of the tag
3. Regular expressions
. \d
+*?
()
[]
\
r Original string
import re
rs = re.findall('\d','123')
rs = re.findall('\d*','456')
rs = re.findall('\d+','789')
rs = re.findall('a+','aaabcd')
print(rs)
import re
# The use of groups
rs = re.findall('\d{1,2}','chuan13zhi2')
rs = re.findall('aaa(\d+)b','aaa91b')
print(rs)
# A general regular expression matches a \ We need four \
rs = re.findall('a\\\\bc','a\\bc')
print(rs)
print('a\\bc')
# Use r Original string
rs = re.findall(r'a\\rbc','a\\rbc')
print(rs)
4. json String conversion python data
import json
json_str = '''[{
"a":"thia is a",
"b":[1,2,3]},{
"a":"thia is a",
"b":[1,2,3]}]'''
rs = json.loads(json_str)
print(rs)
print(type(rs)) # <class 'list'>
print(type(rs[0])) # <class 'dict'>
print(type(json_str)) # <class 'str'>
import json
json_str = '''[
{
"a": "this is a",
"b": [1, 2," Panda "]
},
{
"c": "thia is c",
"d": [1, 2, 3]
}
]'''
rs = json.loads(json_str)
json_str = json.dumps(rs,ensure_ascii=False)
print(json_str)
5. json Format file conversion python data
# json Format file to python data
with open('data/test.json') as fp:
python_list = json.load(fp)
print(python_list)
print(type(python_list)) # <class 'list'>
print(type(python_list[0])) # <class 'dict'>
print(type(fp)) # <class '_io.TextIOWrapper'>
with open("data/test1.json",'w') as fp:
json.dump(rs,fp,ensure_ascii=False)
The channels for sorting out the epidemic situation are as follows , Here are just a few common :
Tencent news https://news.qq.com/zt2020/page/feiyan.htm#%2F=
China Health Commission http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml
Sina news https://news.sina.cn/zt_d/yiqing0121
Netease news https://wp.m.163.com/163/page/news/virus_report/index.html
TRT https://www.trt.net.tr/chinese/covid19
Tableau https://www.tableau.com/zh-cn/covid-19-coronavirus-data-resources/global-tracker
Outbreak https://www.outbreak.my/zh/world
xinhua http://my‐h5news.app.xinhuanet.com/h5activity/yiqingchaxun/index.html
Ifeng.com https://news.ifeng.com/c/special/7uLj4F83Cqm
Sina.com https://news.sina.cn/zt_d/yiqing0121
WHOhttps://covid19.who.int/
Tableau: https://www.tableau.com/covid‐19‐coronavirus‐data‐resources
Johns Hopkins:https://coronavirus.jhu.edu/map.html
Worldometers: https://www.worldometers.info/coronavirus/
CDC: https://www.cdc.gov/covid‐data‐tracker/#cases
The health committees of the provinces 、 The homepage of the epidemic prevention and control department
Let's focus on that , Some anti crawling problems encountered when crawling the world epidemic data from overseas websites .
verification headers Medium User-Agent Field
We're going to use Selenium, There must be header fields , So this point is self defeating .
Restrict users from having to log in
If you are not logged in or have insufficient permissions , The forum is directly forbidden to visit .
The author has obtained dozens of different authorized accounts from various channels , Log in normally , obtain cookie, Group one cookies pool . Choose a random one at the beginning of the program cookie load .
Same account number / Unified IP Continuous access in a short time will return to the advertising page
Use multiple authorized accounts to create cookie pool ; Use multiple native IP build cookie pool ;
Add random... To the crawl cycle sleep;
Cookies
The forum is verifying cookie There is a special mechanism on . Except for two for authenticating user names and id Of memberID、userPasshash outside , There is also a randomly generated to verify the legitimacy of the account igneous Field .
Multiple accounts cookie Build pool ; Clear after each visit cookie;
AJAX
Page refresh combines Ajax And the traditional model .
Is to overcome Ajax The use of Selenium. This kind of automation tool like headless browser can handle very well Ajax Dynamic pull problem .
Verification Code
In order to prevent the same Ip Too many visits are blocked , We used SoftEther To get a lot of native Ip. If you go overseas to visit , There is a certain chance that Google Verification code of the platform ReCaptcha.
We use foreign access platforms to . Different from some small workshop figures / Subtitle verification code , Google's ReCaptcha It's still not easy . At first, I wanted to deploy a deep learning model locally , however ReCaptcha There are too many types of , Or turn to a professional code receiving platform . It's just a little expensive .
We still focus on the code related to various anti - crawling countermeasures .
verification headers Medium User-Agent Field
We're going to use Selenium, Take a look at the relevant code .
options = webdriver.ChromeOptions()
prefs = {
"profile.managed_default_content_settings.images": 2}
options.add_experimental_option("prefs", prefs)
driver_title = webdriver.Chrome(options=options, executable_path=chrome_driver)
driver_user = webdriver.Chrome(options=options, executable_path=chrome_driver)
driver_content = webdriver.Chrome(options=options, executable_path=chrome_driver)
Restrict users from having to log in
If you are not logged in or have insufficient permissions , The forum is directly forbidden to visit .
Take a look at the login simulation , obtain cookie Code for .
try:
driver.get("https://bbs.nga.cn/thread.php?fid=-7")
time.sleep(40)
with open('cookies.txt', 'w') as cookiefile:
# take cookies Save as json Format
cookiefile.write(json.dumps(driver.get_cookies()))
Have a look cookie The code of the pool storage section .
REDIS_HOST = 'localhost'
REDIS_PASSWORD = None
class RedisClient(object):
def __init__(self,type,website,host=REDIS_HOST,port=REDIS_PORT,password=REDIS_PASSWORD):
self.db = redis.StrictRedis(host=host,port=port,password=password,decode_responses=True)
self.type = type
self.website = website
def name(self):
return "{type}:{website}".format(type=self.type,website=self.website)
def set(self,usename,value):
return self.db.hset(self.name(),usename,value)
def get(self,usename):
return self.db.hget(self.name(),usename)
def delete(self,usename):
return self.db.hdel(self.name(),usename)
def count(self):
return self.db.hlen(self.name())
def random(self):
return random.choice(self.db.hvals(self.name()))
def usernames(self):
return self.db.hkeys(self.name())
def all(self):
return self.db.hgetall(self.name())
Take a look at the generation section .
def __init__(self,username,password,browser):
self.url = ''
self.browser = browser
self.wait = WebDriverWait(browser,10)
self.username = username
self.password = password
def open(self):
self.browser.get(self.url)
self.wait.until(EC.presence_of_element_located((By.ID,'dologin'))).click()
self.browser.switch_to.frame('loginIframe')
self.wait.until(EC.presence_of_element_located((By.ID,'switcher_plogin'))).click()
self.wait.until(EC.presence_of_element_located((By.ID,'u'))).send_keys(self.username)
self.wait.until(EC.presence_of_element_located((By.ID,'p'))).send_keys(self.password)
time.sleep(2)
self.wait.until(EC.presence_of_element_located((By.ID,"login_button"))).click()
def password_error(self):
try:
# When the password is wrong, a prompt will pop up , We only need to catch the error prompt to know whether there is an input error
return bool(self.wait.until(EC.presence_of_element_located((By.ID,'err_m'))))
except ex.TimeoutException:
return False
def get_cookies(self):
return self.browser.get_cookies()
Same account number / Unified IP Continuous access in a short time will return to the advertising page
It's already seen cookie Pool related code , Let's take a look IP Pool related parts .
IP Pools are generic , We use open source directly here GitHub The above project proxy_list.
# Persistence
PERSISTENCE = {
'type': 'redis',
'url': 'redis://127.0.0.1:6379/1'
}
Number of concurrent processes
# Use when crawling down an agent to test availability , Reduce network io The waiting time of
COROUTINE_NUM = 50
How many delegates are saved
Default 200, If stored 200 If a proxy is not deleted, it will not crawl to a new proxy
PROXY_STORE_NUM = 300
If the number of saved proxy entries has reached the threshold , Crawl process sleep seconds
Default 60 second , Storage full 200 The crawler process sleeps after 60 second , When you wake up, if you still sleep with your full head
PROXY_FULL_SLEEP_SEC = 60
# How many seconds does the saved agent check for availability
PROXY_STORE_CHECK_SEC = 1200
#web api
Specify the interface IP And port
WEB_API_IP = '127.0.0.1'
WEB_API_PORT = '8111'
Verification Code
In order to prevent the same Ip Too many visits are blocked , We used SoftEther To get a lot of native Ip. If you go overseas to visit , There is a certain chance that Google Verification code of the platform ReCaptcha.
Take a look at the code of the foreign code receiving platform . The code receiving platform has no disadvantages except that it costs money . This price is actually acceptable , After all, we climb alone , It won't take much .
Construct a request to the coding platform .
import requests
response = requests.get(url)
print(response.json())
https://2captcha.com/in.php?key=c0ae5935d807c28f285e5cb16c676a48&method=userrecaptcha&googlekey=6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-&pageurl=https://www.google.com/recaptcha/api2/demo&json=1
When the page appears ReCaptcha Verification code , This verification code is placed on an external frame Inside . We can find the unique verification code id. Let's just put this id Submit to the coding platform . Probably 10-30 Seconds will return the result . Then the platform will return the interface id.
Through interface id Get the final result , It's an encrypted token.
Put this token Assign a value to the form corresponding to the verification code and submit it .
document.getElementById("g-recaptcha-response").innerHTML="TOKEN_FROM_2CAPTCHA";
Environmental Science :python 3.8
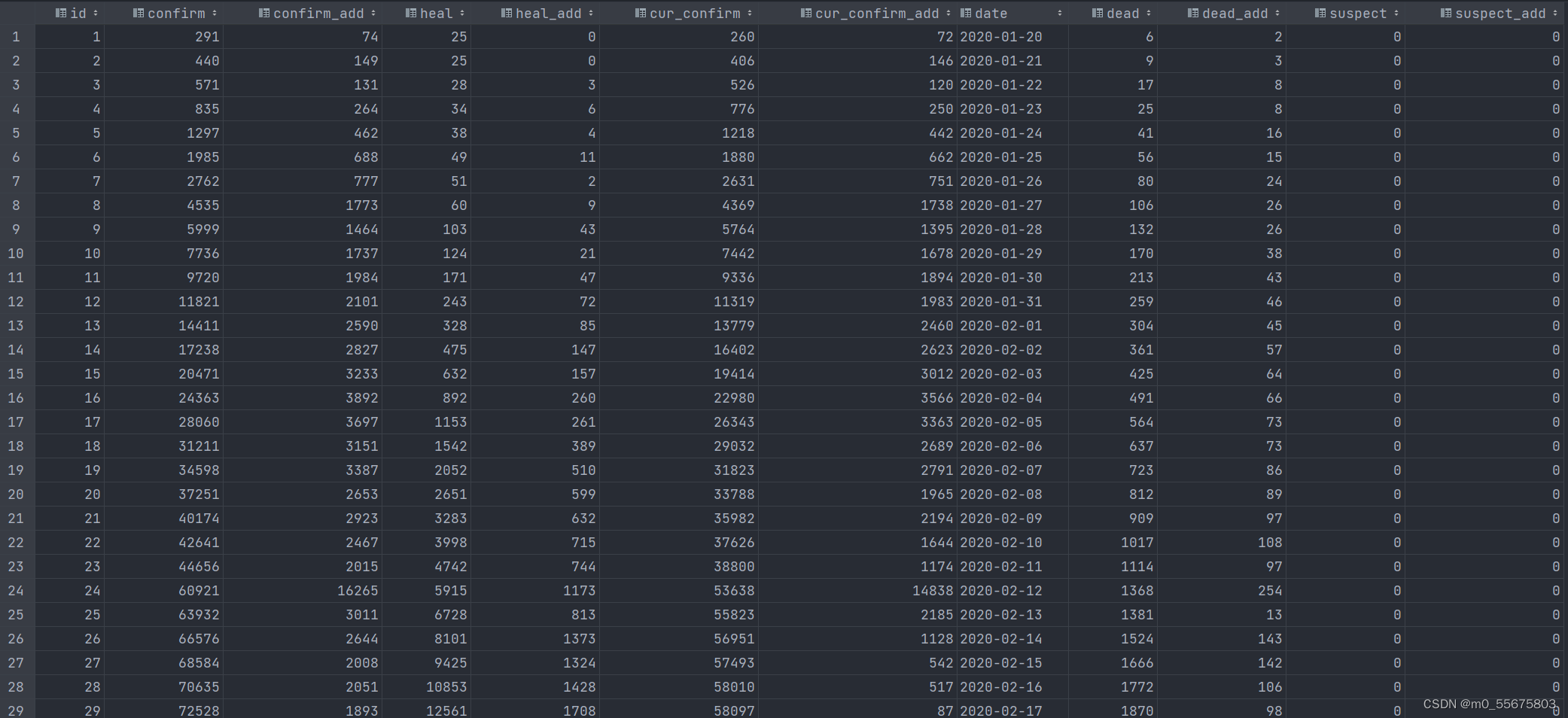
for example , Crawl the epidemic data from Tencent .


import requests
import json
import pprint
import pandas as pd
Send a request
url = ‘https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&_=1638361138568’
response = requests.get(url, verify=False)
Copy
get data
json_data = response.json()[‘data’]
Copy
Parsing data
json_data = json.loads(json_data)
china_data = json_data[‘areaTree’][0][‘children’] # list
data_set = []
for i in china_data:
data_dict = {}
data_dict[‘province’] = i[‘name’]
data_dict[‘nowConfirm’] = i[‘total’][‘nowConfirm’]
data_dict[‘dead’] = i[‘total’][‘dead’]
data_dict[‘heal’] = i[‘total’][‘heal’]
data_dict[‘healRate’] = i[‘total’][‘healRate’]
data_set.append(data_dict)
Copy
Save the data
df = pd.DataFrame(data_set)
df.to_csv(‘data.csv’)
import requests
import json
import csv
url='https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery351007009437517570039_1629632572593&_=1629632572594'
head={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
response = requests.get(url,headers=head).text
print(response)
dict1 =json.loads(response[42:132060])# The slice position will change , We need to analyze the location that changes every day , Then slice
d = json.loads(dict1['data'])#json Is to convert the captured data format ,json.load Is to convert a string into a dictionary format
print(d)
all_dict={
}
all_dict[' Count the time ']=d["lastUpdateTime"]
chinaTotal = d['chinaTotal']
all_dict[' Cumulative confirmed cases '] = chinaTotal['confirm']
all_dict[' Current diagnosis '] = chinaTotal['nowConfirm']
all_dict[' Cured cases '] = chinaTotal['heal']
all_dict[' Death cases '] = chinaTotal['dead']
all_dict[' The mainland yesterday added '] = chinaTotal['suspect']
all_dict[' Import from abroad '] = chinaTotal['importedCase']
all_dict[' Asymptomatic infections '] = chinaTotal['noInfect']
print(all_dict)
print(chinaTotal)
with open('yqin.csv','w+',newline='')as f:
f1= csv.writer(f)
list1=[]
f1.writerow(all_dict)
for i in all_dict:
list1.append(all_dict[i])
f1.writerow(list1)
# print(chinaTotal)
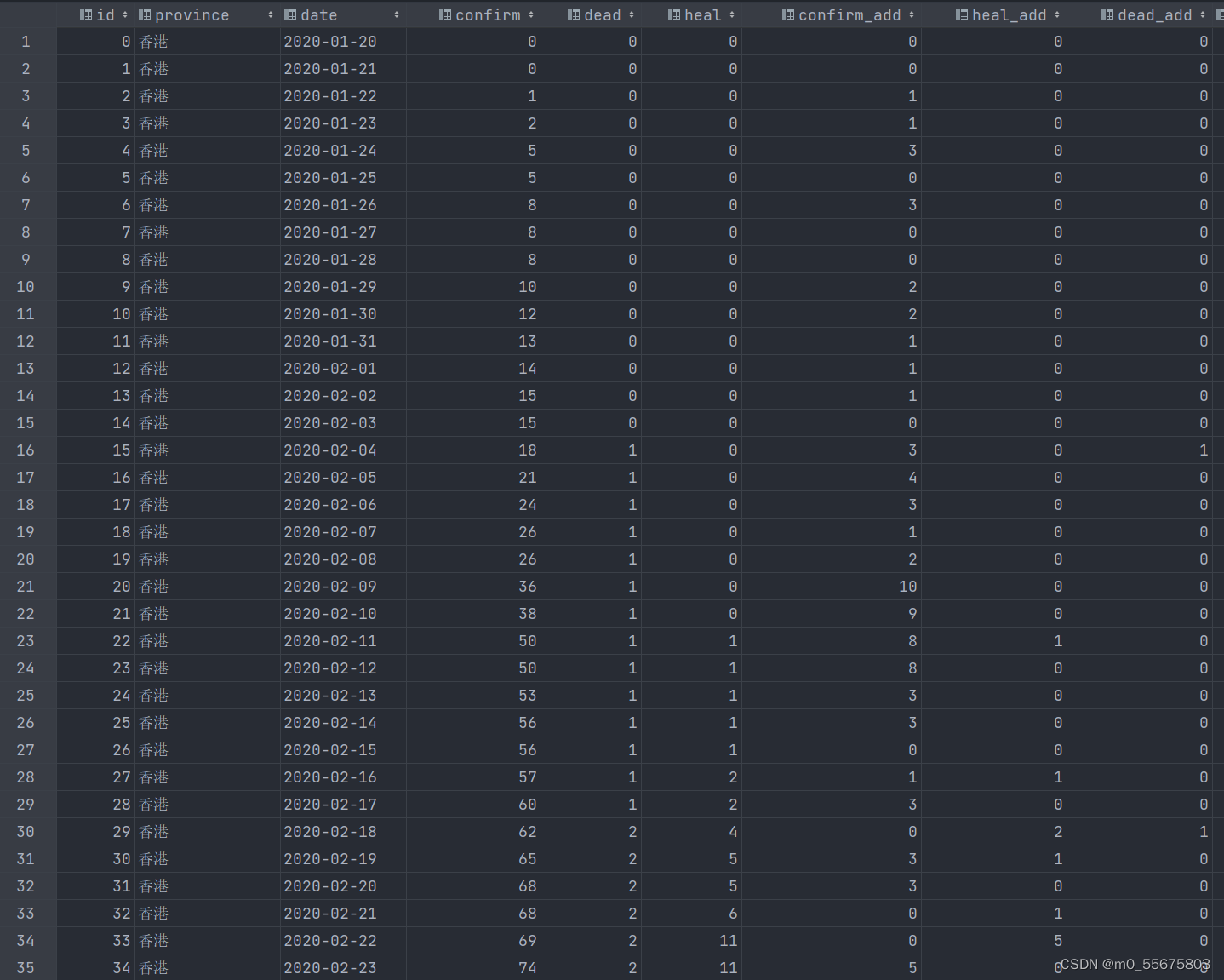
area = d['areaTree'][0]
# for i in area:
# print(area[i])
children = area['children']
with open('yq1.csv','w+',newline = '')as f:
list1= [' Province ',' Existing cases ',' New yesterday ',' Cumulative cases ',' The number of deaths ',' The number of people cured ']
f1 = csv.writer(f)
f1.writerow(list1)
for i , index,in enumerate(children):
cc = children[i]
dd = []
dd.append(cc['name'])
dd.append(cc['total']['nowConfirm'])
dd.append(cc['today']['confirm'])
dd.append(cc['total']['confirm'])
dd.append(cc['total']['dead'])
dd.append(cc['total']['heal'])
f1.writerow(dd)
print(dd)
import json
import re
import requests
import datetime
today = datetime.date.today().strftime('%Y%m%d')
def crawl_dxy_data():
""" Crawl through the real-time statistics of dingxiangyuan , Save in data Under the table of contents , Take the current date as the file name , The file format is json Format
"""
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia') # send out get request
print(response.status_code) # Print status code
try:
url_text = response.content.decode() # Get the response's html page
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', # re.search() Used to scan a string to find the first position where a regular expression pattern produces a match , Then return to the corresponding match object
url_text, re.S) # In string a in , Contains line breaks \n, In this case : If not applicable re.S Parameters , Match only within each line , If a line doesn't have , Just switch to the next line and start matching again
texts = url_content.group() # Get the overall result of the matching regular expression
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') # Remove redundant characters
json_data = json.loads(content)
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('<Response [%s]>' % response.status_code)
crawl_dxy_data()
# Obtain the domestic epidemic data of that day
def get_data(request):
response_data = json.loads(request.text)
all_data = response_data['data'] # Returned data
last_update_time = all_data['lastUpdateTime'] # Last updated
# Overall data
china_total = all_data['chinaTotal'] # A total of
total_confirm = china_total['confirm'] # Cumulative diagnosis
total_heal = china_total['heal'] # Cumulative cure
total_dead = china_total['dead'] # Cumulative death
now_confirm = china_total['nowConfirm'] # Existing diagnosis (= Cumulative confirmation - Cumulative cure - Cumulative death )
suspect = china_total['suspect'] # Suspected
now_severe = china_total['nowSevere'] # Existing severe
imported_case = china_total['importedCase'] # Import from abroad
noInfect = china_total['noInfect'] # Asymptomatic infection
local_confirm = china_total['localConfirm'] # Local diagnosis
# The new data
china_add = all_data['chinaAdd'] # newly added
add_confirm = china_add['confirm'] # Add cumulative diagnosis ?
add_heal = china_add['heal'] # Add healing
add_dead = china_add['dead'] # New deaths
add_now_confirm = china_add['nowConfirm'] # Add existing data
add_suspect = china_add['suspect'] # Add suspected
add_now_sever = china_add['nowSevere'] # Add existing severe diseases
add_imported_case = china_add['importedCase'] # New overseas input
add_no_infect = china_add['noInfect'] # New asymptomatic
# print(china_add)
area_Tree = json.loads(response_data['data'])['areaTree'] # Data by Region
for each_province in area_Tree[0]['children']:
# print(each_province)
province_name = each_province['name'] # Provincial name
province_today_confirm = each_province['today']['confirm'] # The total number of confirmed cases in the province today
province_total_confirm = each_province['total']['nowConfirm'] # The total number of existing diagnoses in the province
province_total_confirmed = each_province['total']['confirm'] # The total number of confirmed cases in the province
province_total_dead = each_province['total']['dead'] # The total number of deaths in the province
province_total_heal = each_province['total']['heal'] # The total number of cured in the province
province_total_localConfirm = each_province['total']['provinceLocalConfirm'] # Number of local confirmations in the province
for each_city in each_province['children']:
city_name = each_city['name'] # City name
city_today_confirm = each_city['today']['confirm'] # The number of confirmed cases in the city today
city_total_confirm = each_city['total']['nowConfirm'] # The number of confirmed cases in the city
city_total_confirmed = each_city['total']['confirm'] # The total number of confirmed cases in the city
city_total_dead = each_city['total']['dead'] # Number of deaths in the city
city_total_heal = each_city['total']['heal'] # Number of cured in the city
city_grade = '' # City risk level
if 'grade' in each_city['total']:
city_grade = each_city['total']['grade']
print(" Province :" + province_name +
" region :" + city_name +
" Today's diagnosis is new :" + str(city_today_confirm) +
" Existing diagnosis :" + str(city_total_confirm) +
" Risk level :" + city_grade +
" Cumulative diagnosis :" + str(city_total_confirmed) +
" Cure :" + str(city_total_heal) +
" Death :" + str(city_total_dead))
if __name__ == '__main__':
# Interface
api = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,' \
'diseaseh5Shelf '
head = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, ' \
'like Gecko) Chrome/18.0.1025.166 Safari/535.19 '}
req = requests.get(api, headers=head)
print(req.text)
get_data(req)
边栏推荐
- Enterprise Architect v16
- PostgreSQL basic introduction and deployment
- The solution to the error "xxx.pri has modification time XXXX s in the futrue" in the compilation of domestic Kirin QT
- MongoDB精华总结
- [C language] analysis of variable essence
- Page crash handling method
- 【FPGA混沌】基于FPGA的混沌系统verilog实现
- 疫情数据分析平台工作报告【42】CodeNet
- [automation] generate xlsx report based on openstack automated patrol deployed by kolla
- JSP实现银柜台业务绩效考核系统
猜你喜欢

Image mosaic based on transformation matrix

Zabbix6.0新功能Geomap 地图标记 你会用吗?

Review of technical economy and Enterprise Management Chapter 4

DS18B20 digital thermometer (I) electrical characteristics, power supply and wiring mode

Concept and introduction of microservice

树莓派4B使用Intel Movidius NCS 2来进行推断加速

MySQL的check约束数字问题
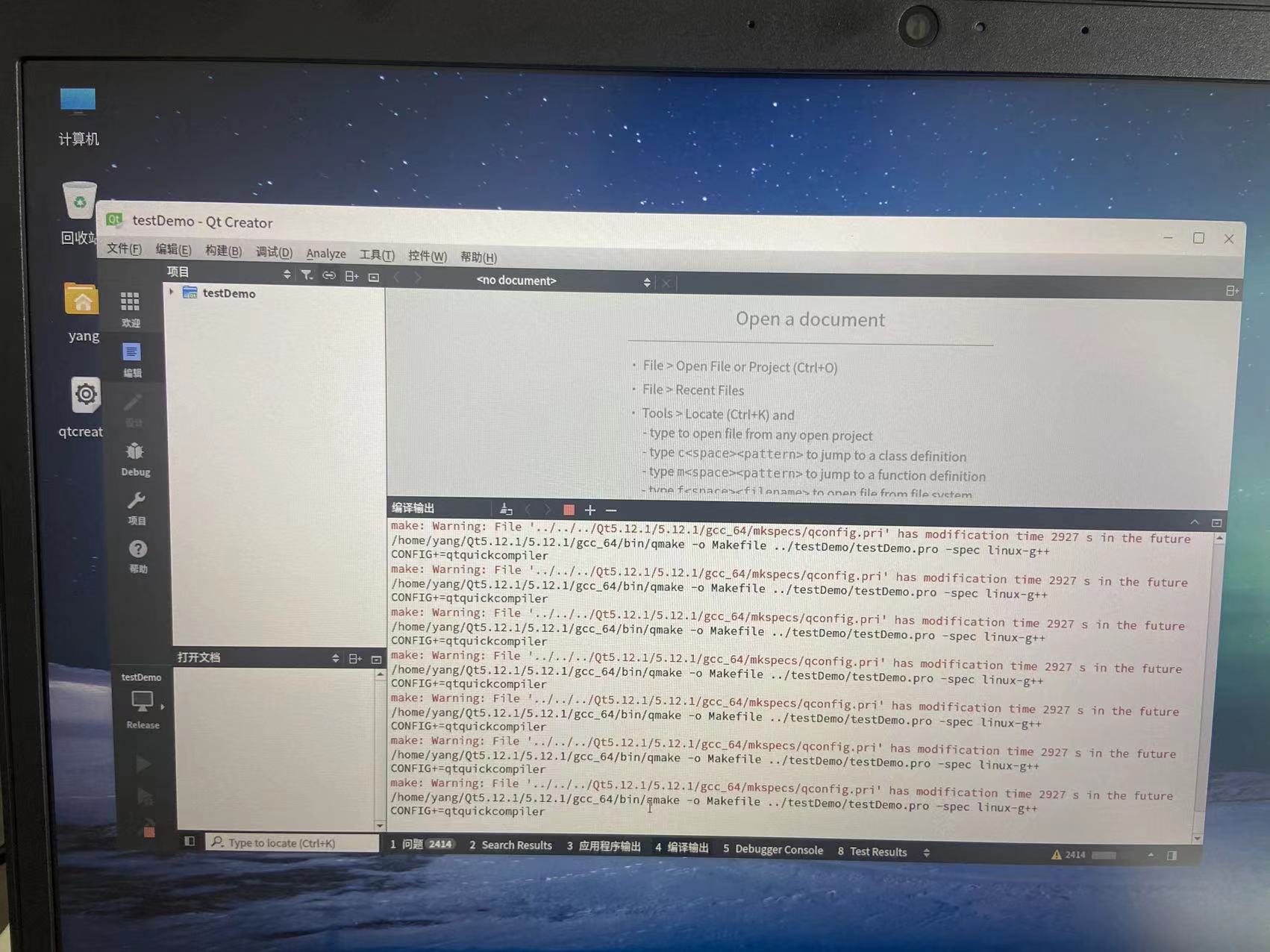
关于 国产麒麟Qt编译报错“xxx.pri has modification time xxxx s in the futrue“ 的解决方法

Detailed explanation of software testing process

Esp32c3 remote serial port
随机推荐
spacy中en_core_web_sm安装问题
Kotlin starts the process, the difference between launch and async, and starts the process in sequence
【C语言】封装接口(加减乘除)
Centernet2 practice: take you through the training of custom datasets with centernet2
【C语言】变量本质分析
Zabbix6.0新功能Geomap 地图标记 你会用吗?
动规(15)-最低通行费
Concept and introduction of microservice
SqEL简单上手
【FPGA+GPS接收器】基于FPGA的双频GPS接收器详细设计介绍
双目标定学习资料整理
sed命令
Database selected 60 interview questions
[Yugong series] March 2022 asp Net core Middleware - current limiting
[C language] analysis of variable essence
Absolute positioning three ways to center the box
[automation] generate xlsx report based on openstack automated patrol deployed by kolla
VIM command Encyclopedia
Page crash handling method
Sqel easy to use