当前位置:网站首页>哈希冲突和一致性哈希
哈希冲突和一致性哈希
2022-08-02 01:43:00 【Ysming88】
文章目录
哈希冲突
哈希函数又称“散列函数”,通过某种算法,可以将任意长度的输入转换为固定长度的输出。
如在Java中,哈希码用整型int表示,这意味着一共只有2的32次方个哈希码,而对象的个数可以理解为无限个,哈希函数可以将无限个对象实例转换成有限个的哈希码。Object::hashCode默认就是通过对象所在的内存地址经过处理计算而得出的。
哈希函数的目的是将任意长度的输入转换为固定长度的输出,这就意味着,不同的输入可能会转换成相同的输出,这就导致了「哈希冲突」,也叫「哈希碰撞」。哈希冲突是客观事实,只能尽量避免,无法彻底解决。
处理哈希冲突
一个设计良好的哈希函数,应该让不同特征的对象具有不同的哈希码,尽可能的避免哈希冲突。
但是哈希冲突是客观事实,只能尽量避免,无法彻底解决。因此,一旦发生了哈希冲突,如何解决就变得非常重要了。
哈希冲突常见的解决方式有如下四种方法:
1.开放地址法
开放地址法,有三种形式,分别是线性探测,二次探测和随机探测法
线性探测
如下图,假设哈希码为0-5,哈希表中已经插入8、9元素,此时再插入14,下标2已经被8给占用了,出现哈希冲突。
线性探测会环形寻找next节点,先找到下标3,被9占用了,依然冲突,再找到下标4,没有被占用,即没有发生冲突,则将14放入下标4的节点中。 二次探测
二次探测
也称二元探测,如果默认的哈希函数计算出的哈希码发生了哈希冲突,则哈希函数升级为:
(hash(key) + d) % table.length;
d = 1^2, -1^2, 2^2, -2^2, 3^2......(1,-1,2,-2,4,-4,9...)
其中,table.length为哈希表的表长;d 是产生冲突的时候的增量序列。
随机探测
和二次探测类似,只是d会更换为一组伪随机数列。
(hash(key) + d) % table.length;
d = 一组伪随机数列
开放定址法的优点就是:只要哈希表还有位置,通过不断的探测,总能找到合适的位置。
缺点是探测的次数不可控,一旦探测次数骤增,会严重影响哈希表的读写性能。
ThreadLocalMap就是用的「线性探测」技术解决哈希冲突的,当线程的ThreadLocal实例数量较多时,ThreadLocal的读效率会下降,因此Netty、Dubbo才会编写自己的ThreadLocal实现。
2.再散列法
也可以称作再哈希法,提供一组哈希函数,而不是一个。
如果第一个哈希函数计算的哈希码发生冲突了,就采用第二个哈希函数重新计算哈希码,直到不冲突为止。、
查询时也是一样,依次调用不同的哈希函数计算哈希码,直到Key相等。
这种方式会增加哈希计算的开销,影响读写的效率。
int hash = hash1(key)、hash2(key)、hash3(key)......
3.链地址法
也称作拉链法,将哈希码对应一个链表,插入元素时,如果哈希码冲突了,就将元素插入到链表,可选头插或尾插。
查询时,遍历哈希码对应的链表。
HashMap采用的就是这种方式。
这种方式的缺点是:一旦哈希冲突多了,哈希表会退化成链表,查询效率会从O(1)变为O(n)。JDK8的HashMap针对这种情况有做优化,冲突超过8个会将链表转换为红黑树,提高查询效率。
4 建立一个公共溢出区
在创建哈希表的同时,再额外创建一个公共溢出区,专门用来存放发生哈希冲突的元素。查找时,先从哈希表查,查不到再去公共溢出区查。
这种方式的缺点是:哈希冲突多了,公共溢出区会膨胀的非常厉害,查询的效率也有影响。
一致性哈希
普通 hash算法
对于一个经典的分布式缓存的应用场景。假设我们有三台缓存服务器,用于缓存图片,我们为这三台缓存服务器编号为 0号、1号、2号。我们希望将3万张图片被均匀的缓存到这3台服务器上,以便它们能够分摊缓存的压力。
常见的做法是对缓存项的键进行哈希,将hash后的结果对缓存服务器的数量进行取模操作,通过取模后的结果,决定缓存项将会缓存在哪一台服务器上。
hash(图片名称)% N
当我们对同一个图片名称做相同的哈希计算时,得出的结果应该是不变的,如果我们有3台服务器,使用哈希后的结果对3求余,那么余数一定是0、1或者2;如果求余的结果为0, 就把当前图片缓存在0号服务器上,如果余数为1,就缓存在1号服务器上。
以此类推;同理,当我们访问任意图片时,只要再次对图片名称进行上述运算,即可得出图片应该存放在哪一台缓存服务器上,我们只要在这一台服务器上查找图片即可,如果图片在对应的服务器上不存在,则证明对应的图片没有被缓存,也不用再去遍历其他缓存服务器了,通过这样的方法,即可将3万张图片随机的分布到3台缓存服务器上了,而且下次访问某张图片时,直接能够判断出该图片应该存在于哪台缓存服务器上,我们暂时称上述算法为普通 HASH 算法或者取模算法。
普通 hash 算法的缺陷
上述HASH算法时,会出现一些缺陷:如果服务器已经不能满足缓存需求,就需要增加服务器数量,假设我们增加了一台缓存服务器,此时如果仍然使用上述方法对同一张图片进行缓存,那么这张图片所在的服务器编号必定与原来3台服务器时所在的服务器编号不同,因为除数由3变为了4,最终导致所有缓存的位置都要发生改变,也就是说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端服务器请求数据;同理,假设突然有一台缓存服务器出现了故障,那么我们则需要将故障机器移除,那么缓存服务器数量从3台变为2台,同样会导致大量缓存在同一时间失效,造成了缓存的雪崩**,后端服务器将会承受巨大的压力,整个系统很有可能被压垮**。为了解决这种情况,就有了一致性哈希算法。
一致性哈希算法
一致性哈希算法也是使用取模的方法,但是普通取模算法是对服务器的数量进行取模,而一致性哈希算法是对 2^32 取模,具体步骤如下:
- 步骤一:一致性哈希算法将整个哈希值空间( 2^32 )按照顺时针方向组织成一个虚拟的圆环,称为 Hash 环;
- 步骤二:接着将各个服务器使用 Hash 函数对 2^32 取模进行哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,从而确定每台机器在哈希环上的位置
- 步骤三:最后使用算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针寻找,第一台遇到的服务器就是其应该定位到的服务器
下面我们使用具体案例说明一下一致性哈希算法的具体流程:
(1)步骤一:哈希环的组织:
我们将 2^32 想象成一个圆,像钟表一样,钟表的圆可以理解成由60个点组成的圆,而此处我们把这个圆想象成由2^32个点组成的圆,示意图如下: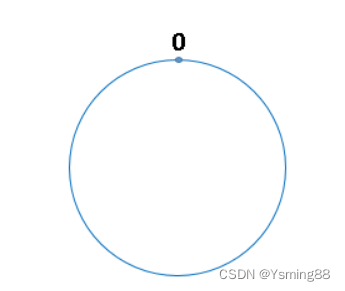
圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1 ,也就是说0点左侧的第一个点代表2^32-1,我们把这个由 2^32 个点组成的圆环称为hash环。
(2)步骤二:确定服务器在哈希环的位置:
哈希算法:hash(服务器的IP) % 2^32
上述公式的计算结果一定是 0 到 2^32-1 之间的整数,那么上图中的 hash 环上必定有一个点与这个整数对应,所以我们可以使用这个整数代表服务器,也就是服务器就可以映射到这个环上,假设我们有 ABC 三台服务器,那么它们在哈希环上的示意图如下: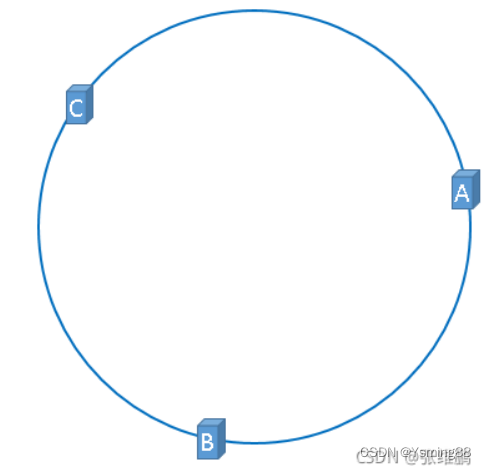
(3)步骤三:将数据映射到哈希环上:
我们还是使用图片的名称作为 key,所以我们使用下面算法将图片映射在哈希环上:hash(图片名称) % 2^32,假设我们有4张图片,映射后的示意图如下,其中橘黄色的点表示图片:
那么,怎么算出上图中的图片应该被缓存到哪一台服务上面呢?我们只要从图片的位置开始,沿顺时针方向遇到的第一个服务器就是图片存放的服务器了。最终,1号、2号图片将会被缓存到服务器A上,3号图片将会被缓存到服务器B上,4号图片将会被缓存到服务器C上。
一致性 hash 算法的优点
前面提到,如果简单对服务器数量进行取模,那么当服务器数量发生变化时,会产生缓存的雪崩,从而很有可能导致系统崩溃,而使用一致性哈希算法就可以很好的解决这个问题,因为一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,只有部分缓存会失效,不至于将所有压力都在同一时间集中到后端服务器上,具有较好的容错性和可扩展性。
假设服务器B出现了故障,需要将服务器B移除,那么移除前后的示意图如下图所示: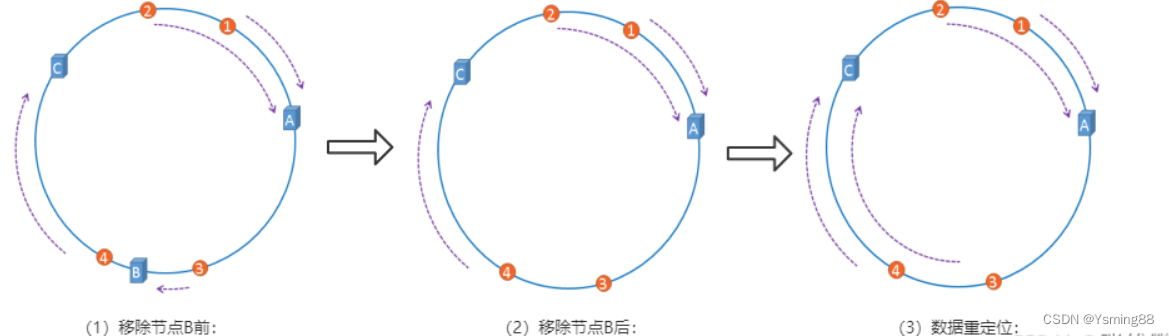
在服务器B未移除时,图片3应该被缓存到服务器B中,可是当服务器B移除以后,按照之前描述的一致性哈希算法的规则,图片3应该被缓存到服务器C中,因为从图片3的位置出发,沿顺时针方向遇到的第一个缓存服务器节点就是服务器C,也就是说,如果服务器B出现故障被移除时,图片3的缓存位置会发生改变,但是,图片4仍然会被缓存到服务器C中,图片1与图片2仍然会被缓存到服务器A中,这与服务器B移除之前并没有任何区别,这就是一致性哈希算法的优点。
hash 环的倾斜与虚拟节点
一致性哈希算法在服务节点太少的情况下,容易因为节点分部不均匀而造成数据倾斜问题,也就是被缓存的对象大部分集中缓存在某一台服务器上,从而出现数据分布不均匀的情况,这种情况就称为 hash 环的倾斜。如下图所示: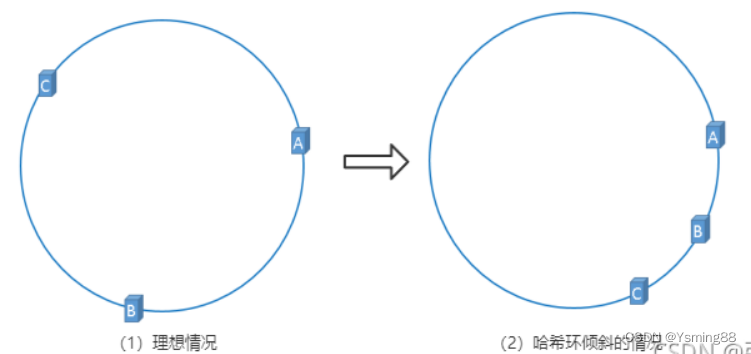
hash 环的倾斜在极端情况下,仍然有可能引起系统的崩溃,为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点,一个实际物理节点可以对应多个虚拟节点,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大,hash环倾斜所带来的影响就越小,同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。具体做法可以在服务器ip或主机名的后面增加编号来实现,加入虚拟节点以后的hash环如下:
参考文章:
哈希冲突的常见解决方式
一致性哈希算法原理详解
边栏推荐
- 乱七八糟的网站
- Some insights from 5 years of automated testing experience: UI automation must overcome these 10 pits
- 电商库存系统的防超卖和高并发扣减方案
- Constructor of typescript35-class
- Day.js 常用方法
- Image fusion based on weighted 】 and pyramid image fusion with matlab code
- typescript30-any类型
- 6-25漏洞利用-irc后门利用
- The characteristics and principle of typescript29 - enumeration type
- Reflex WMS中阶系列6:对一个装货重复run pick会有什么后果?
猜你喜欢

Rust P2P Network Application Combat-1 P2P Network Core Concepts and Ping Program
6-24 exploit-vnc password cracking

第一次写对牛客的编程面试题:输入一个字符串,返回该字符串出现最多的字母
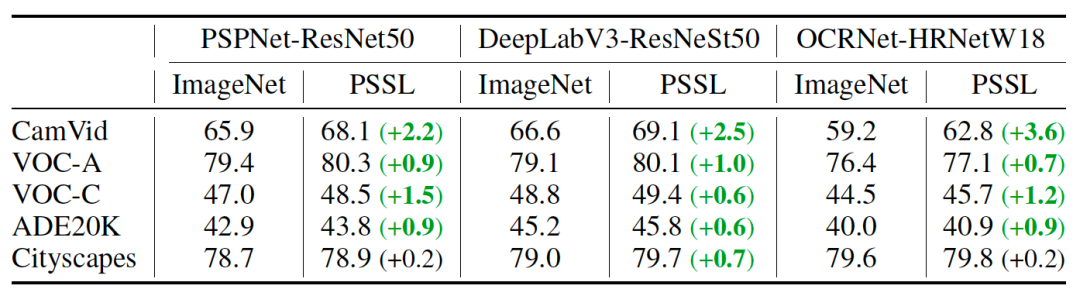
The ultra-large-scale industrial practical semantic segmentation dataset PSSL and pre-training model are open source!

Day115.尚医通:后台用户管理:用户锁定解锁、详情、认证列表审批
Rust P2P网络应用实战-1 P2P网络核心概念及Ping程序

typescript34-class的基本使用

字节给我狠狠上了一课:危机来的时候你连准备时间都没有...
The characteristics and principle of typescript29 - enumeration type
力扣 1161. 最大层内元素和
随机推荐
Go语学习笔记 - gorm使用 - gorm处理错误 Web框架Gin(十)
AntPathMatcher使用
哈希表
【Brush the title】Family robbery
Navicat数据显示不完全的解决方法
Flask gets post request parameters
有效进行自动化测试,这几个软件测试工具一定要收藏好!!!
3. Bean scope and life cycle
Moonbeam与Project Galaxy集成,为社区带来全新的用户体验
JDBC PreparedStatement 的命名参数实现
flask获取post请求参数
ALCCIKERS Shane 20191114
超大规模的产业实用语义分割数据集PSSL与预训练模型开源啦!
手写一个博客平台~第一天
FlinkSQL CDC实现同步oracle数据到mysql
C语言实验七 二维数组程序设计
S/4中究竟有多少个模块,你对这些模块了解多少
Flink_CDC搭建及简单使用
大话西游创建角色失败解决
typescript31-any类型