当前位置:网站首页>哈希表
哈希表
2022-08-02 00:46:00 【m0_60631323】
目录
一、哈希表
1.1 概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(logN),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快
找到该元素。
向该种结构中:
- 插入元素:根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
- 搜索元素:对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式称为哈希方法,哈希方法中使用的转换函数称为哈希函数,构造出来的结构称为哈希表(HashTable)
例如: 数据集合{1,5,3,4,6,7,9};
哈希函数为:hash(key)=key%capacity ;capacity为存储空间的大小
1.2 哈希冲突
对于两个数据元素的关键字 k1和k2,有k1 !=k2 ,但有:Hash(k1) =Hash(k2),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
1.3 冲突避免
首先,我们需要明确一点,由于我们哈希表底层数组的容量往往是小于实际要存储的关键字的数量的,这就导致一个问题,冲突的发生是必然的,但我们能做的应该是尽量的降低冲突率。
1.4 哈希函数的设计
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。 哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见的哈希函数
直接定址法(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况除留余数法(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
除了上面两种常用方法还平方取中法、折叠法、随机数法、数学分析法
【注意】:
哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
1.5 调节负载因子

负载因子和冲突率的关系图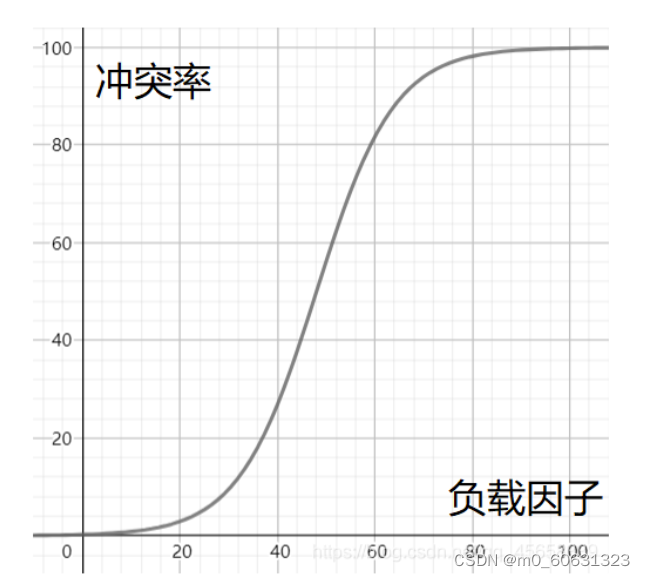
由图可知:
当冲突率过高时,我们需要通过降低负载因子来间接的降低冲突率。而哈希表中已有的关键字个数是不可变的,那么只能扩大数组的大小来降低负载因子
1.6 解决冲突
解决哈希冲突两种常见的方法是:闭散列和开散列
1.6.1 闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
(1)线性探测法
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
插入新元素的步骤:
通过哈希函数获取待插入元素在哈希表中的位置
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
例如:如果下一个要插入的元素是16,计算出hash(16)=6;
但发现6位置有元素,就会将16放在8下标的位置

【注意】:
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索,例如删除元素6,如果直接删除掉,16的查找可能会受影响,这时只能用伪删除的方法来删除一个元素
(2)二次探测法
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨
着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:Hi=(H0+i^2)%m,其中i=1,2,3…
H0 是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。例如插入元素16,
研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不
会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
【缺陷】:
闭散列的最大缺陷就是空间利用率低
1.6.2 开散列
开散列法也叫链地址法,首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子
集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
例如数据集合{1,4,5,6,7,9};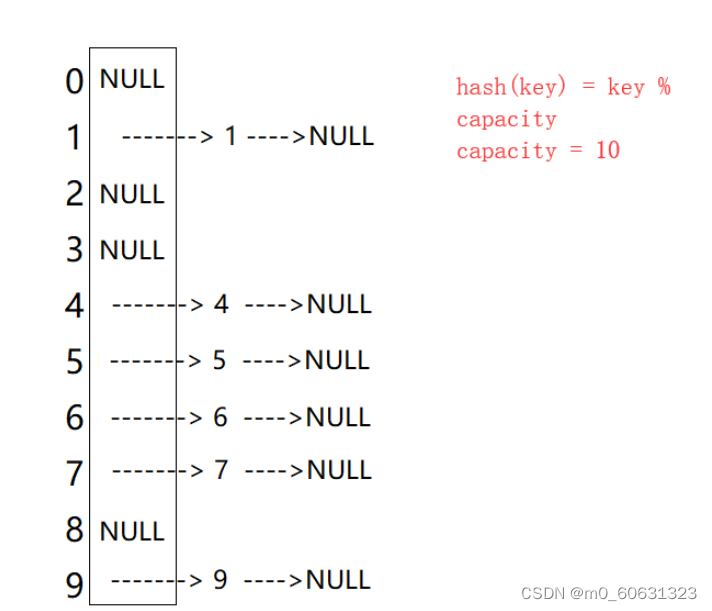
由图可知,开散列中每个桶中放的是发生哈希冲突的元素
开散列,可以认为是把一个在大集合中的搜索问题转化为在小集合中做搜索了
1.7 解决严重冲突
刚才我们提到了,哈希桶其实可以看作将大集合的搜索问题转化为小集合的搜索问题了,那如果冲突严重,就意味着小集合的搜索性能其实也时不佳的,这个时候我们就可以将这个所谓的小集合搜索问题继续进行转化,例如:
- 每个桶的背后是另一个哈希表
- 每个桶的背后是一棵搜索树
1.8模拟实现哈希桶(简单类型)
模拟实现一个key-value模型的哈希桶
节点特征
private static class Node{
int key;
int val;
public Node next;
public Node(int key,int val){
this.key=key;
this.val=val;
}
}
哈希桶特征
public Node[] array;
public int usedSize;//有效节点个数
//默认的负载因子,当超过这个值以后需要扩容
private static final double DEAFULT_LOAD_FACTOR=0.75;
public HashBuck(){
array=new Node[8];
}
(1) put函数,存放元素
主要分以下几步:
- 创建节点
- 根据hash函数计算存储位置index
- 遍历index的链表,看该链表中是否有一样的key,有的话,替换val,没有的话头插法插入
- 检查负载因子
//存放元素
public void put(int key,int val){
//创建节点
Node node=new Node(key, val);
//根据哈希函数计算index
int index=key% array.length;
Node cur=array[index];
//遍历链表
while (cur!=null){
if(cur.key==key){
cur.val=val;
return;
}
cur=cur.next;
}
//代码如果走到这里说明当前
//链表中不包含key
node.next=array[index];
array[index]=node;
usedSize++;
if(loadFactor()>=DEAFULT_LOAD_FACTOR){
//扩容
resize();
}
}
private double loadFactor(){
return usedSize*1.0/ array.length;
}
//扩容并重新哈希
private void resize(){
//注意:不能是能copy方法,copy方法会将原来i下标的元素
//拷贝到新数组中的i位置,但对于哈希表来说,原来储在i位置
//的节点,数组扩容后,重新哈希后不一定还放在i位置
//所以要先保证新数组里元素都为null
//重新哈希后将元素放到新数组中
Node[] tmp=new Node[2* array.length];
for (int i = 0; i < array.length; i++) {
Node cur=array[i];
while (cur!=null){
int index= cur.key%tmp.length;
//在修改cur.next之前一定要先记录下来
//否则找不到后续节点的位置
Node curNext=cur.next;
cur.next=tmp[index];
tmp[index]=cur;
cur=curNext;
}
}
array=tmp;
}
【面试题】: 哈希表的扩容需要注意什么?
需要遍历数组中每个链表的每个节点,将这些节点重写哈希到新的数组中。
因为扩容之后,数组容量变了,例如初始数组长度是8,扩容后数组长度是16,
哈希函数是hash(key)=key%capacity ,此时有key为9,在数组长度为8的哈希表中计算出hash(9)=9%8=1,在数组长度为16的哈希表中,计算出hash(9)=9%16=9。
(2) 获取元素的方法
//通过key,获取val
public int get(int key){
int index=key% array.length;
Node cur=array[index];
while (cur!=null){
if(key== cur.key){
return cur.val;
}
cur=cur.next;
}
return -1;
}
源码:
package hash;
import java.util.Arrays;
public class HashBuck {
private static class Node{
int key;
int val;
public Node next;
public Node(int key,int val){
this.key=key;
this.val=val;
}
}
public Node[] array;
public int usedSize;//有效节点个数
//默认的负载因子,当超过这个值以后需要扩容
private static final double DEAFULT_LOAD_FACTOR=0.75;
public HashBuck(){
array=new Node[8];
}
//存放元素
public void put(int key,int val){
//创建节点
Node node=new Node(key, val);
//根据哈希函数计算index
int index=key% array.length;
Node cur=array[index];
//遍历链表
while (cur!=null){
if(cur.key==key){
cur.val=val;
return;
}
cur=cur.next;
}
//代码如果走到这里说明当前
//链表中不包含key
node.next=array[index];
array[index]=node;
usedSize++;
if(loadFactor()>=DEAFULT_LOAD_FACTOR){
//扩容
resize();
}
}
private double loadFactor(){
return usedSize*1.0/ array.length;
}
//扩容并重新哈希
private void resize(){
//注意:不能是能copy方法,copy方法会将原来i下标的元素
//拷贝到新数组中的i位置,但对于哈希表来说,原来储在i位置
//的节点,数组扩容后,重新哈希后不一定还放在i位置
//所以要先保证新数组里元素都为null
//重新哈希后将元素放到新数组中
Node[] tmp=new Node[2* array.length];
for (int i = 0; i < array.length; i++) {
Node cur=array[i];
while (cur!=null){
int index= cur.key%tmp.length;
//在修改cur.next之前一定要先记录下来
//否则找不到后续节点的位置
Node curNext=cur.next;
cur.next=tmp[index];
tmp[index]=cur;
cur=curNext;
}
}
array=tmp;
}
//通过key,获取val
public int get(int key){
int index=key% array.length;
Node cur=array[index];
while (cur!=null){
if(key== cur.key){
return cur.val;
}
cur=cur.next;
}
return -1;
}
}
测试:
public static void main(String[] args) {
HashBuck hashBuck=new HashBuck();
hashBuck.put(1,99);
hashBuck.put(4,99);
hashBuck.put(20,99);
hashBuck.put(10,99);
hashBuck.put(11,99);
hashBuck.put(9,99);
}
【说明】:
数组长度为8,负载因子0.75,当放完第6个元素后会进行重新哈希
扩容之前:
扩容之后: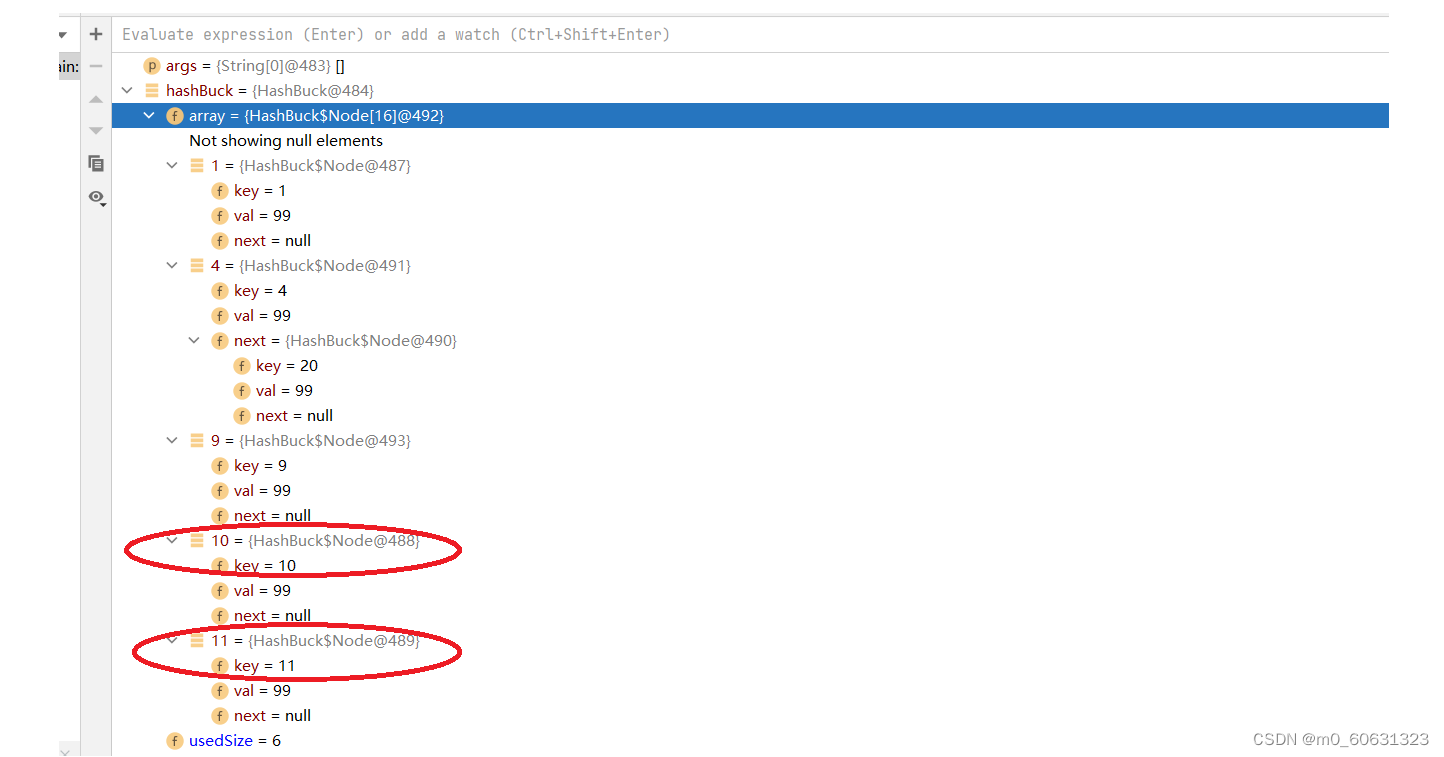
key值为10和11的节点,经数组扩容和重新哈希后存储的位置变了
1.9模拟实现哈希桶(泛型)
我们上面实现的哈希桶存在一些问题:
只能存储key为整数的节点,当我们想要存的key是一个Person类的时候,我们无法根据哈希函数hash(key)=key%capacity,计算出key值应该存放的位置,
那么此时我们就要用到的是Object类中的hashCode方法来计算类类型的key的hash值
1.9.1 hashCode和equals方法介绍
class Person{
public String id;//身份证号
public Person(String id){
this.id=id;
}
@Override
public String toString() {
return "Person{" +
"id='" + id + '\'' +
'}';
}
}
public class Test1 {
public static void main(String[] args) {
Person person1=new Person("1111");
Person person2= new Person("1111");
System.out.println(person1.hashCode());
System.out.println(person2.hashCode());
System.out.println(person1.equals(person2));
}
//执行结果:
460141958
1163157884
false
}
观察上面代码,对于person1和person2两个对象来说,id是相同的,那么按照我们正常理解,这两个对象在哈希桶中的存储位置也应该实现相同的(也就是有hashCode计算出的哈希值相同),但由结果发现两个对象的哈希值不同,同时调用equals方法结果为false,这是因为equals方法默认是:
默认比较的是两个对象的地址是否相同,而不是比较两个对象的内容是否相同
equals也不能用比较两个简单类型的变量值是否相同
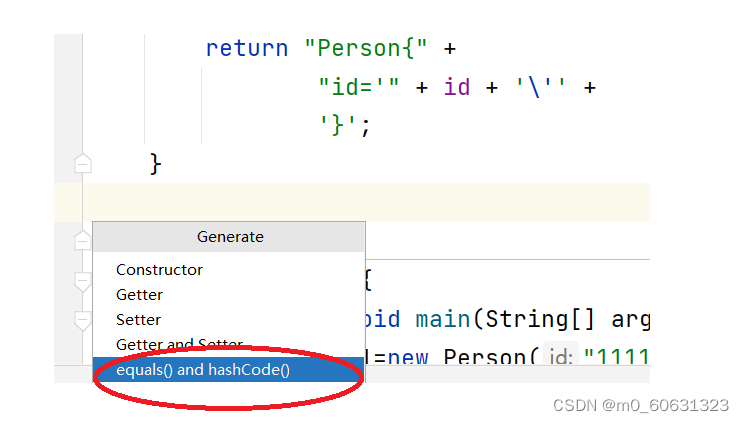
此时我们需要在Person类中重写hashCode方法
alt+ins,之后选中hashCode和equals,这样就重写了equals和hashCode方法
class Person{
public String id;//身份证号
public Person(String id){
this.id=id;
}
@Override
public String toString() {
return "Person{" +
"id='" + id + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(id, person.id);
}
@Override
public int hashCode() {
//根据Person对象的id进行hash计算,只要两个对象的id相同,计算出的哈希值也一定相同
return Objects.hash(id);
}
}
public class Test1 {
public static void main(String[] args) {
Person person1=new Person("1111");
Person person2= new Person("1111");
System.out.println(person1.hashCode());
System.out.println(person2.hashCode());
System.out.println(person1.equals(person2));
}
}
//执行结果
1508447
1508447
true
重写后的equals方法,比较两个对象的内容是否相同
【面试题】:
equals和hashCode在HashMap中的作用
HashMap 的添加、获取时需要通过 key 的 hashCode() 进行 hash(),然后计算下标 ,从而获得要找的桶的位置。
在插入时,利用equals方法去桶中查找是否该桶中已经包含与要插入的key相同的节点
在获取节点的val时,利用equals方法在桶中查找相应的节点
举例:查字典,要查"帅气"这个词语,hashCode的作用相当于我们先找到"帅"这个字,equals的作用相当于在"帅"这个字下面一一对照以"帅"开头的词语看和"帅气"是否相同如果要插入的两个对象的hash值一样,这两个对象通过equals比较一定为true吗?
不一定,hash值一样只能说明这两个对象处在同一个链表中,同一个链表下可能有很多的节点,不能说明这两个对象的内容一定相同如果要插入的两个对象通过equals比较为true,那么这两个对象的hash值一定一样吗?
一定,如果两个对象的equals方法一样,那么这两个对象的hash值一定是一样的
1.9.2泛型哈希桶
节点特征
private static class Node<K,V>{
K key;
V val;
public Node<K,V> next;
public Node(K key,V val){
this.key=key;
this.val=val;
}
}
哈希桶特征:
public Node<K,V>[] array;
public int usedSize;
private static final double DEAFULT_LOAD_FACTOR=0.75;
public HashBuck2(){
array=(Node<K,V>[])new Node[10];
}
(1)put方法
public void put(K key,V val){
Node<K,V> node=new Node<>(key, val);
int hash=key.hashCode();
int index=hash%array.length;
Node<K,V> cur=array[index];
while (cur!=null){
if(cur.key.equals(key)){
cur.val=val;
return ;
}
cur=cur.next;
}
node.next=array[index];
array[index]=node;
usedSize++;
if(loadFactor()>=DEAFULT_LOAD_FACTOR){
resize();
}
}
private double loadFactor(){
return usedSize*1.0/ array.length;
}
//扩容并重新哈希
private void resize(){
Node<K,V>[] tmp=new Node[2* array.length];
for (int i = 0; i < array.length; i++) {
Node<K,V> cur=array[i];
while (cur!=null){
int hash=cur.key.hashCode();
int index=hash% tmp.length;
Node<K,V> curNext=cur.next;
cur.next=tmp[index];
tmp[index]=cur;
cur=curNext;
}
}
array=tmp;
}
【注意】:
找到节点应该存储在的链表的头节点的引用所在的数组下标index的步骤:
- 应用hashCode方法计算key的hash值
- 因为计算通过hashCode计算出的hash值是整数,此时我们就可以将这个hash值带入到哈希函数中计算出index,index=hash%array.length;
找到要插入的链表后,要先遍历链表看是否已经存在key,如果存在key,直接替换val,如果不存在就头插法插入
- 遍历链表的过程中,要通过equals方法比较要插入的key和当前链表中的key中的内容是否相同

(2)get方法
public V get(K key){
int hash=key.hashCode();
int index=hash%array.length;
Node<K,V> cur=array[index];
while (cur!=null){
if(cur.key.equals(key)){
return cur.val;
}
cur=cur.next;
}
return null;
}
源码:
package hashbuck;
public class HashBuck2<K,V> {
private static class Node<K,V>{
K key;
V val;
public Node<K,V> next;
public Node(K key,V val){
this.key=key;
this.val=val;
}
}
public Node<K,V>[] array;
public int usedSize;
private static final double DEAFULT_LOAD_FACTOR=0.75;
public HashBuck2(){
array=(Node<K,V>[])new Node[10];
}
public void put(K key,V val){
Node<K,V> node=new Node<>(key, val);
int hash=key.hashCode();
int index=hash%array.length;
Node<K,V> cur=array[index];
while (cur!=null){
if(cur.key.equals(key)){
cur.val=val;
return ;
}
cur=cur.next;
}
node.next=array[index];
array[index]=node;
usedSize++;
if(loadFactor()>=DEAFULT_LOAD_FACTOR){
resize();
}
}
private double loadFactor(){
return usedSize*1.0/ array.length;
}
//扩容并重新哈希
private void resize(){
Node<K,V>[] tmp=new Node[2* array.length];
for (int i = 0; i < array.length; i++) {
Node<K,V> cur=array[i];
while (cur!=null){
int hash=cur.key.hashCode();
int index=hash% tmp.length;
Node<K,V> curNext=cur.next;
cur.next=tmp[index];
tmp[index]=cur;
cur=curNext;
}
}
array=tmp;
}
public V get(K key){
int hash=key.hashCode();
int index=hash%array.length;
Node<K,V> cur=array[index];
while (cur!=null){
if(cur.key.equals(key)){
return cur.val;
}
cur=cur.next;
}
return null;
}
}
1.10 哈希桶和集合类的关系
- HashMap 和 HashSet 即 java 中利用哈希表实现的 Map 和 Set
- java 中使用的是哈希桶方式解决冲突的
- java 会在冲突链表长度大于一定阈值后,将链表转变为搜索树(红黑树)
- java 中计算哈希值实际上是调用的类的hashCode 方法,进行 key 的相等性比较是调用 key equals 方法。所以如果要用自定义类作为 HashMap key 或者 HashSet的值,必须覆写 hashCode 和 equals 方 法,而且要做到 equals 相等的对象,hashCode 一定是一致的
边栏推荐
猜你喜欢

傅立叶变换相关公式

Docker安装canal、mysql进行简单测试与实现redis和mysql缓存一致性
IDEA如何运行web程序

22.卷积神经网络实战-Lenet5
【CodeTON Round 2 (Div. 1 + Div. 2, Rated, Prizes!)(A~D)】
【目标检测】FCOS: Fully Convolutional One-Stage Object Detection
Kubernetes — 核心资源对象 — 存储

C语言:打印整数二进制的奇数位和偶数位

去经营企业吧

from origin ‘null‘ has been blocked by CORS policy Cross origin requests are only supported for
随机推荐
IDEA版Postman插件Restful Fast Request,细节到位,功能好用
Redis cluster mode
期货开户手续费的秘密成了透明
【目标检测】FCOS: Fully Convolutional One-Stage Object Detection
Reflex WMS中阶系列6:对一个装货重复run pick会有什么后果?
管理基础知识11
第 45 届ICPC亚洲区域赛(上海)G-Fibonacci
R语言使用table1包绘制(生成)三线表、使用单变量分列构建三线表、编写自定义三线表结构(将因子变量细粒度化重新构建三线图)、自定义修改描述性统计参数输出自定义统计量
C语言实验八 字符数组程序设计
信息收集之目录扫描-dirbuster
Can't connect to MySQL server on 'localhost3306' (10061) Simple and clear solution
PowerBI商学院佐罗BI真经连续剧
go笔记之——goroutine
管理基础知识20
期货开户手续费加一分是主流
Day.js 常用方法
TKU记一次单点QPS优化(顺祝ITEYE终于回来了)
About MySQL data insertion (advanced usage)
C language character and string function summary (2)
Two ways to pass feign exceptions: fallbackfactory and global processing Get server-side custom exceptions