当前位置:网站首页>【目标检测】FCOS: Fully Convolutional One-Stage Object Detection
【目标检测】FCOS: Fully Convolutional One-Stage Object Detection
2022-08-02 00:15:00 【呆呆的猫】
论文:FCOS: Fully Convolutional One-Stage Object Detection
代码:https://github.com/aim-uofa/AdelaiDet/tree/master/configs/FCOS-Detection
出处:ICCV2019

FCOS 贡献:
- 证明了目标检测也可以像语义分割那样,使用单阶段来实现
- 检测任务可以实现 proposal-free 和 anchor-free 来实现,可以很大程度降低超参数的设计和调试,使得目标检测任务更优美简单
- FCOS 达到了当前单阶段检测的 SOTA,并且也可以被用作两阶段网络中的 RPN 网络
- 使用 ResNeXt-32x8d-101-FPN,在 COCO 上得到了 42.1% AP
一、背景
当时主流的目标检测算法,如 Faster RCNN、SSD、YOLOv2/v3 等,都是基于 proposal 或 anchor 的方法,使用这些预定义的 anchor 是这些方法成功的主要原因。但这些方法也有一些缺陷:
- 检测效果严重依赖于预定义框的尺寸、宽高比、数量等等,如 RetinaNet 通过调节这些超参数,就在 COCO 上提高了 4 AP,所以 anchor-based 方法需要细致的调节这些超参数
- 由于目标大小和尺度跨度较大,所以尽管使用很丰富的参数,也有不能覆盖的情况
- anchor-based 方法为了提升效果,一般会使用很多的 anchor,但很多 anchor 其实是覆盖到负样本上了,有很严重的正负样本不平衡问题
- 过多的 anchor 会在训练的时候和真值计算 IoU 的时候增加很大的计算量
基于 FCN 的方法在语义分割、关键点检测、深度估计等领域都取得了较好的效果,同样作为密集预测任务,目标检测由于有 anchor 所以一直不能实现端到端的单阶段预测。
所以研究者就提出了问题:目标检测能通过逐点预测来实现吗?
在 FCOS 之前,也有一些 FCN-based 方法用于解决目标检测的问题,如 Dense-Box 和 UnitBox。这些结构在输出的特征图上,直接预测一个 4D 向量 + class 类别,如图 1 左侧所示,4D 向量表示从某个点到 bbox 的 4 个边的距离。
为了解决 bbox 大小不同的问题,DenseNet 将输入图像 resize 到相同大小,所以就需要使用金字塔的特征来进行目标检测。且这些方法难以解决单个点对应多个目标的问题,如图 1 右侧所示。更多的用于文字检测等目标无相交的情况,难以解决目标高度相交的情况。

二、方法
FCOS 方法是第一个使用逐个像素点来预测的目标检测方法,并且提出了 centerness 分支,来抑制 low-quality bbox 并提升检测效果。
2.1 全卷积单阶段目标检测器
1、训练样本构建
假设:
- backbone 的第 i i i 层的特征图为 F i ∈ R H × W × C F_i\in R^{H\times W\times C} Fi∈RH×W×C
- s s s 是在该层前所经历的 stride
- bbox 的真值可以表示为 B i {B_i} Bi, B i = ( x 0 i , y 0 i , x 1 i , y 1 i , c i ) ∈ R 4 × 1 , 2 , . . . , C B_i = (x_0^i, y_0^i, x_1^i, y_1^i, c^i) \in R^4 \times{1, 2,..., C} Bi=(x0i,y0i,x1i,y1i,ci)∈R4×1,2,...,C (分别表示左上和右下角点,和类别)
对于特征图 F i F_i Fi 中的任意位置 ( x , y ) (x, y) (x,y),可以将其推回到该层特征图的输入特征图的位置 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s (\lfloor \frac{s}{2} \rfloor + xs, \lfloor \frac{s}{2} \rfloor + ys (⌊2s⌋+xs,⌊2s⌋+ys。
本文提出的检测器是直接回归每个位置上的目标的bbox,也就是将每个像素位置看做一个训练样本,而非将每个 anchor box 看做训练样本。(anchor-based 检测器是回归每个 anchor 和真实框的偏移)
如何判定正负样本:
- 如果某个像素位置落入真实的 bbox 内,而且类别和真实的类别相同,则定义为正样本
- 否则判定其为负样本,且类别为 0 (background class)
回归的目标:
- t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) t^* = (l^* , t^* , r^* , b^* ) t∗=(l∗,t∗,r∗,b∗) 是每个像素位置(sample)所要回归的目标,分别表示从 sample 的位置到 bbox 的四个边的距离,如图 1 左侧所示。当一个点同时落入多个框的时候,被认为是 “ambiguous sample”,也就是 “模棱两可” 的框,选择最小面积的框作为回归目标。
- 如果一个像素位置 ( x , y ) (x, y) (x,y) 和 bounding box B i B_i Bi 是相关的,则训练时的回归目标可以被格式化为如下形式,从下面的公式中也能看出,FCOS 能够使用尽可能多的 sample 来作为训练样本(作者认为这也是 FCOS 能超越 anchor-based 方法的一个主要原因)

2、网络输出
在 backbone 的后面,连接了 4 层卷积层,来进行分类和回归,并且由于回归的目标总数正的,所以,作者在回归分支的后面使用 e x p ( x ) exp(x) exp(x) 来将任何 ( 0 , ∞ ) (0, \infty) (0,∞) 的实数进行映射。
- 80D 的分类结果(以 COCO 为例)
- 4D 的回归结果 t = ( l , t , r , b ) t = (l, t, r, b) t=(l,t,r,b)
分类器:C 个二分类分类器
优势:输出参数少
- FCOS 比 anchor-based 方法的输出参数少 9x,因为 anchor-based 方法在每个位置都放置了约 9 个不同大小的 anchors
3、Loss 函数
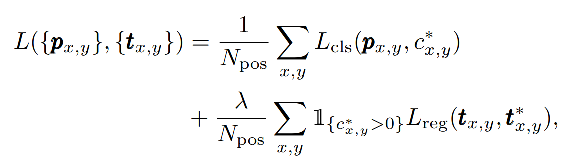
- L c l s L_{cls} Lcls 是 focal loss
- l r e g l_{reg} lreg 是 IoU loss
- N p o s N_{pos} Npos 是正样本的数量
- λ \lambda λ 是 1(为了平衡权重)
- Σ \Sigma Σ 的作用范围是特征图上的所有像素点
- KaTeX parse error: Expected 'EOF', got '}' at position 15: 1_{\{c_i^*\>0}}̲ 是一个调节因子,当 c i ∗ > 0 c_i^*>0 ci∗>0 时为 1,其他情况为 0
4、推理
FCOS 的推理是很直接的:
- 输入图像并经过 backbone 和 head
- 得到每个位置的特征图分类得分 p x , y p_{x,y} px,y 和回归得分 t x , y t_{x,y} tx,y
- 选择 p x , y > 0.05 p_{x,y}>0.05 px,y>0.05 的作为正样本,并得到预测框(公式1)
2.2 Multi-level Prediction with FPN for FCOS
下面介绍 FCOS 可能产生的两个问题,但可以通过多尺度特征 FPN 解决的:
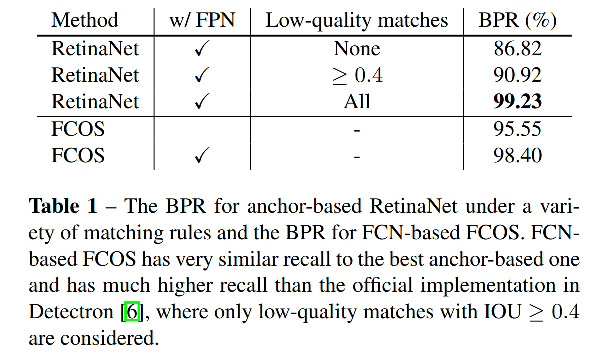
1、特征图分辨率大幅降低(如 16x)可能产生的低 Recall
在 anchor-based 检测器中,由于降低分辨率导致的低 recall 可以通过使用低 IoU 阈值来得到补偿。
但对于 FCOS,可能第一眼会觉得低分辨率会造成其 recall 比 anchor-based 方法低的原因在于其不可能恢复在最终的特征图上没有对应sample的目标。
但在表 1 中,作者也验证了 FCOS 能达到和 RetinaNet 等方法甚至更好的 recall,而且通过使用 FPN,能进一步提高。
2、真值框的重合可能导致训练时候的样本模棱两可
在训练过程中,到底该位置应该回归哪个框呢?
这个模棱两可的问题可能降低 FCN based 检测器。
本文也验证了可以很好的解决该问题:
和 FPN 一样,本文作者也在不同分辨率的特征图上来预测不同尺度的目标,使用了 5 个 level 的特征图 P 3 , P 4 , P 5 , P 6 , P 7 {P_3, P_4, P_5, P_6, P_7} P3,P4,P5,P6,P7,其总 stride 分别为 8、16、32、64、128。
- P 3 , P 4 , P 5 P_3, P_4, P_5 P3,P4,P5 是通过 backbone C 3 , C 4 , C 5 C3, C_4, C_5 C3,C4,C5 经过 1x1 卷积来得到的(如图 2)
- P 6 P_6 P6 是在 P 5 P_5 P5 后使用 stride=2 的卷积得到的, P 7 P_7 P7 是在 P 6 P_6 P6 后使用 stride=2 的卷积得到的
Anchor-based 是怎么给不同分辨率的特征图分配 anchor 的呢?
Anchor-based 方法是给不同 level 的特征图分配不同大小的 anchor box
FCOS 是怎么分配 anchor 的呢?
FCOS 直接限制 bbox 回归的数值的范围
- 首先,在每个特征图的每个位置上计算回归目标值 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) t^* = (l^* , t^* , r^* , b^* ) t∗=(l∗,t∗,r∗,b∗)
- 接着,如果某个位置的结果满足 m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) > m i max(l^* , t^* , r^* , b^*)>m_i max(l∗,t∗,r∗,b∗)>mi 或 m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) < m i − 1 max(l^* , t^* , r^* , b^*)<m_{i-1} max(l∗,t∗,r∗,b∗)<mi−1,则认定该位置为负样本,也不用回归 bbox。 m i m_i mi 是在 level i i i 的特征图需要回归的最远距离。 m 2 , m 3 , m 4 , m 5 , m 6 m_2, m_3, m_4, m_5, m_6 m2,m3,m4,m5,m6 分别设置为 0, 64, 128, 256, 512 和 ∞ \infty ∞。由于不同大小的目标被分配到了不同 level 的特征图上,而且有重叠的目标一般大小都不一样,可以被分配到不同尺度的特征图上去,所以,多尺度金字塔特征,能够很好的解决 FCOS 的前景模棱两可问题。
- 最后,作者对不同尺度特征共享 head,可以提高检测效果,并提升了效率。但是,由于不同 level 的特征图需要回归不同尺度的目标(如 P3 回归的尺度为 [0,64]),所以使用一个共享头是不太合理的。故此,作者没有使用标准的 e x p ( x ) exp(x) exp(x),而是使用了 e x p ( s i x ) exp(s_ix) exp(six), s i s_i si 也是一个可训练的参数,可以根据特征图的 level 自动调节尺度。


2.3 Center-ness for FCOS
虽然使用 FPN 可以弥补不同尺度目标的识别问题,但 FCOS 还是和 anchor-based 方法的效果有一定的差距。
主要原因在于,预测产生了很多距离目标中心点很远的低质量 bbox
如何解决距离中心点很远的低质量 bbox?
作者在原来的两个 branch 的基础上,添加了一个 centerness 分支,来预测每个位置的 “centerness”,即该位置和真实目标中心点的位置,如图 2 所示。
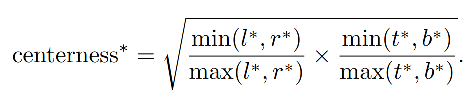
- 为了减缓衰落,使用了根号
- centerness 的范围是 (0,1),使用二值交叉熵损失来训练(添加到公式 2 的 loss 函数)
- 在测试时,final score(用于 NMS 框排序)是 centerness × \times × classification score 得到的,所以可以降低远离中心点的位置(即 low-quality 位置)的权重,可以通过 NMS 过滤掉很大一部分 low-quality 位置,提升检测效果。
极端情况下:
- 如果某一个点在box边界,那么centerness就是0
- 如果刚好在box中心,这个值就是1。centerness的值在0-1之间
- 测试的时候,作者将centerness乘以类别score作为新的score,这样就降低了远离中心点的location的分数;,在NMS阶段将会大概率过滤掉它们。
从 anchor-based 检测器的角度来看,anchor-based 方法使用两个 IoU 阈值( T l o w T_{low} Tlow 和 T h i g h T_{high} Thigh 来将 anchor 分为 negative、ignore、positive,centerness 可以被看做一个 soft threshold。

三、效果
使用 ResNeXt-32x8d-101-FPN,在 COCO 上得到了 42.1% AP
使用 centerness 的效果对比: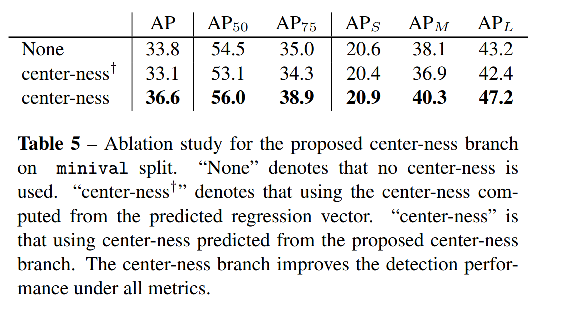
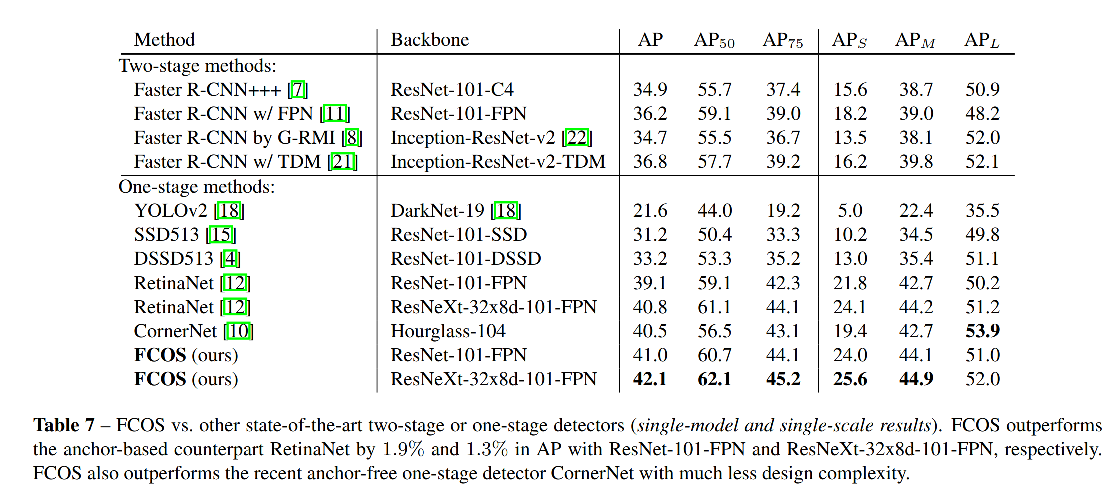
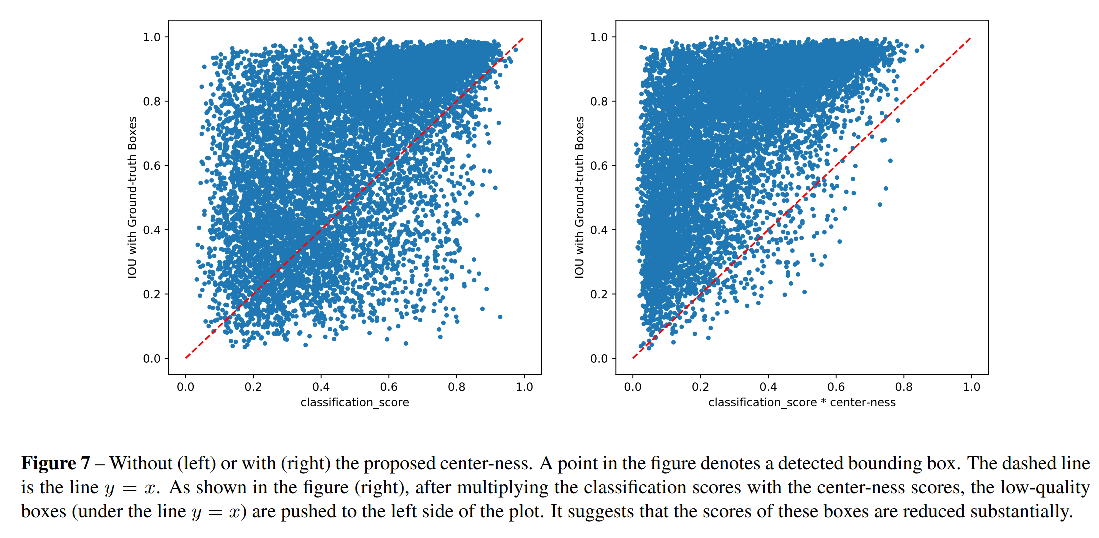
如图 7 所示:
- 使用 centerness 前,有很多 low-quality bbox 的类别得分很高,很难被 NMS 消除
- 使用 centerness 后,这些点都被推到了左上角,即降低类别得分置信度,更容易被消除
如图 8 所示,FCOS 可以很好的检测被遮挡、高重叠的各种不同大小的目标。

边栏推荐
- 基于编码策略的电网假数据注入攻击检测
- Disk and file system management
- 期货开户调整交易所保证金标准
- Async/await principle and execution sequence analysis
- JS中对事件代理的理解及其应用场景
- uni-app项目总结
- Don't know about SynchronousQueue?So ArrayBlockingQueue and LinkedBlockingQueue don't and don't know?
- MLX90640 红外热成像仪测温传感器模块开发笔记(十) 成果展示-红眼睛相机
- poker question
- nodeJs--mime模块
猜你喜欢







随机推荐
好的期货公司开户让人省心省钱
JSP 如何获取request对象中的路径信息呢?
Statement执行update语句
Routing strategy
go笔记——锁
什么是低代码(Low-Code)?低代码适用于哪些场景?
GIF making - very simple one-click animation tool
Unknown CMake command "add_action_files"
How to design a circular queue?Come and learn~
[21-Day Learning Challenge] A small summary of sequential search and binary search
String splitting function strtok exercise
Business test how to avoid missing?
Grid false data injection attacks detection based on coding strategy
这 4 款电脑记事本软件,得试试
What is Low-Code?What scenarios is low code suitable for?
uni-app project summary
swing的Jlist列表滚动条以及增加元素的问题
Multidimensional Correlation Time Series Modeling Method Based on Screening Partial Least Squares Regression of Correlation Variables
[HCIP] BGP Small Experiment (Federation, Optimization)
抖音数据接口API-获取用户主页信息-监控直播开启