当前位置:网站首页>爬虫练习题(二)
爬虫练习题(二)
2022-07-05 19:05:00 【InfoQ】
"""
目标网站:https://www.1ppt.com/moban/
爬取要求:
1、 翻页爬取这个网页上面的源代码
2、 并且保存到本地,注意编码
"""
'''
1.分析网站:
https://www.1ppt.com/moban/ 第一页
https://www.1ppt.com/moban/ppt_moban_2.html 第二页
https://www.1ppt.com/moban/ppt_moban_3.html 第三页
'''
import urllib.request
start = int(input("输入起始页")) # 转int
end = int(input("输入结束页"))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
for n in range(start, end + 1):
url = 'https://www.1ppt.com/moban/ppt_moban_{}.html'.format(n)
print(url)
req = urllib.request.Request(url, headers=headers) # 实例化请求对象
response = urllib.request.urlopen(req) # 发送请求的方法
with open(f'第{n}页.html', 'a', encoding='gb2312') as f:
f.write(response.read().decode('gb2312'))边栏推荐
- 2022 the latest big company Android interview real problem analysis, Android development will be able to technology
- Tupu software digital twin | visual management system based on BIM Technology
- golang通过指针for...range实现切片中元素的值的更改
- Optimization of middle alignment of loading style of device player in easycvr electronic map
- Debezium系列之:修改源码支持drop foreign key if exists fk
- Tianyi cloud understands enterprise level data security in this way
- word如何转换成pdf?word转pdf简单的方法分享!
- The road of enterprise digital transformation starts from here
- 在线协作产品哪家强?微软 Loop 、Notion、FlowUs
- HiEngine:可媲美本地的云原生内存数据库引擎
猜你喜欢
![[AI framework basic technology] automatic derivation mechanism (autograd)](/img/9c/a5713def131dc7643cc19b3839ff0c.png)
[AI framework basic technology] automatic derivation mechanism (autograd)
Windows Oracle open remote connection Windows Server Oracle open remote connection

C# 语言的高级应用
Reflection and imagination on the notation like tool
关于 Notion-Like 工具的反思和畅想

The relationship between temperature measurement and imaging accuracy of ifd-x micro infrared imager (module)
cf:B. Almost Ternary Matrix【對稱 + 找規律 + 構造 + 我是構造垃圾】
word如何转换成pdf?word转pdf简单的方法分享!
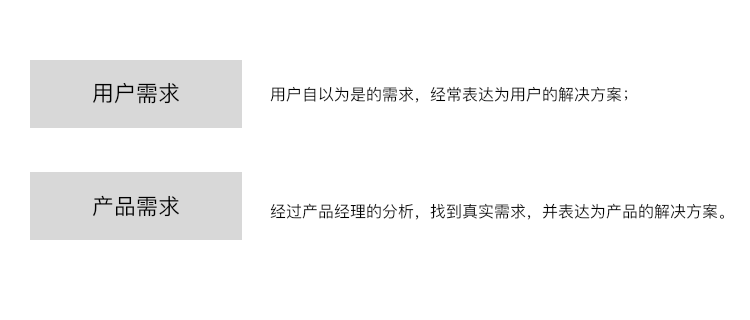
Talking about fake demand from takeout order
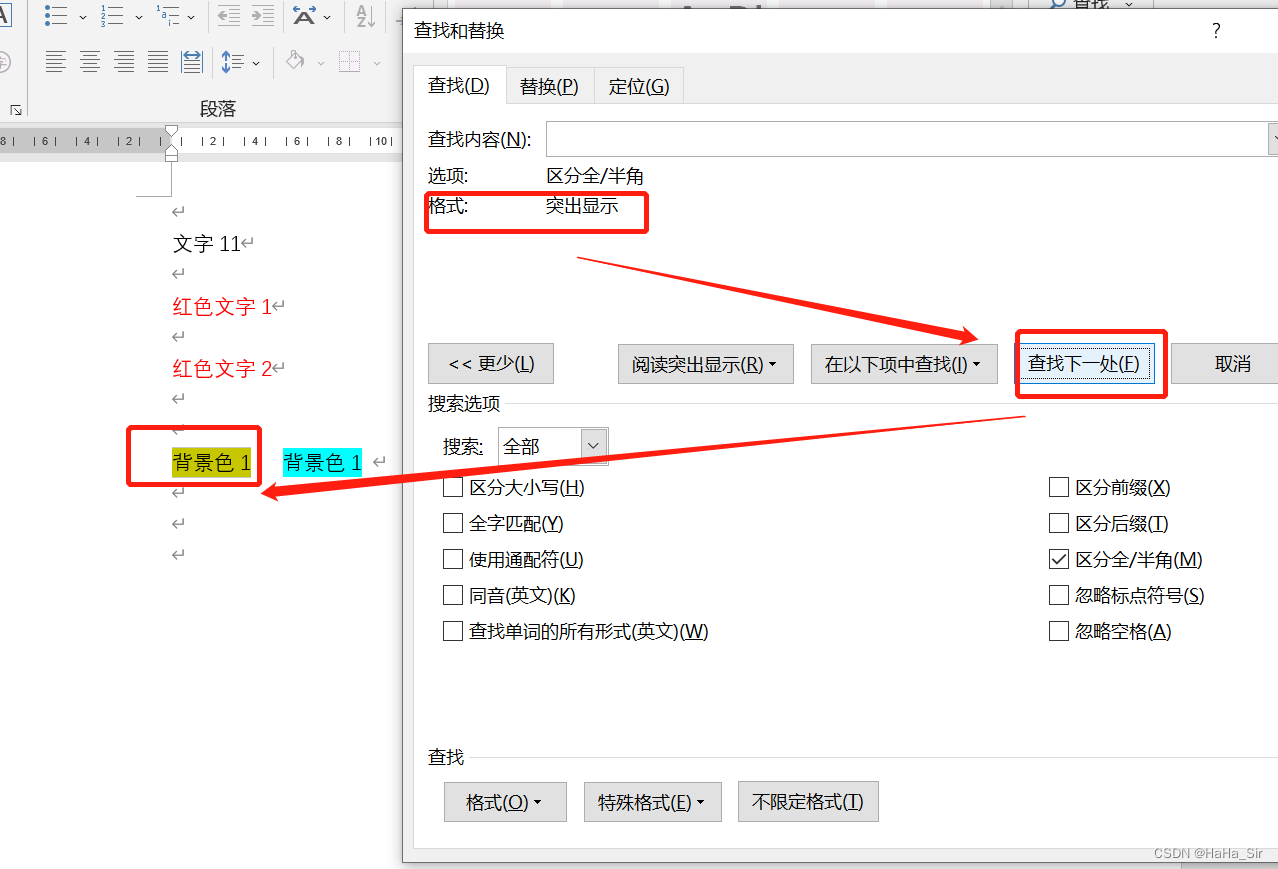
Word finds red text word finds color font word finds highlighted formatted text
随机推荐
shell编程基础(第9篇:循环)
从零实现深度学习框架——LSTM从理论到实战【实战】
Go语言 | 01 WSL+VSCode环境搭建避坑指南
Is the performance evaluation of suppliers in the fastener industry cumbersome? Choose the right tool to easily counter attack!
#夏日挑战赛# HarmonyOS - 实现消息通知功能
2022 the latest big company Android interview real problem analysis, Android development will be able to technology
毫米波雷达人体感应器,智能感知静止存在,人体存在检测应用
Video fusion cloud platform easycvr adds multi-level grouping, which can flexibly manage access devices
You can have both fish and bear's paw! Sky wing cloud elastic bare metal is attractive!
cf:B. Almost Ternary Matrix【對稱 + 找規律 + 構造 + 我是構造垃圾】
golang通过指针for...range实现切片中元素的值的更改
Which securities company is better and which platform is safer for mobile account opening
为什么 BI 软件都搞不定关联分析?带你分析分析
R language uses lubridate package to process date and time data
Blue sky drawing bed Apple quick instructions
uniapp获取微信头像和昵称
Notion 类生产力工具如何选择?Notion 、FlowUs 、Wolai 对比评测
面试官:Redis中集合数据类型的内部实现方式是什么?
Go语言 | 02 for循环及常用函数的使用
cf:B. Almost Ternary Matrix【对称 + 找规律 + 构造 + 我是构造垃圾】