当前位置:网站首页>【图像分类】2022-MPViT CVPR
【图像分类】2022-MPViT CVPR
2022-08-02 23:56:00 【說詤榢】
文章目录
【图像分类】2022-MPViT CVPR
论文链接:https://arxiv.org/abs/2112.11010
论文代码:https://github.com/youngwanLEE/MPViT
PPT简介: https://blog.csdn.net/Qingkaii/article/details/124398735
1. 简介
1.1 简介
在这项工作中,作者以不同于现有Transformer的视角,探索多尺度path embedding与multi-path结构,提出了Multi-path Vision Transformer(MPViT)。
通过使用 overlapping convolutional patch embedding,MPViT同时嵌入相同大小的patch特征。然后,将不同尺度的Token通过多条路径独立地输入Transformer encoders,并对生成的特征进行聚合,从而在同一特征级别上实现精细和粗糙的特征表示。
- 在特征聚合步骤中,引入了一个global-to-local feature interaction(GLI)过程,该过程将卷积局部特征与Transformer的全局特征连接起来,同时利用了卷积的局部连通性和Transformer的全局上下文。
因此本文作者将重点放在了图像的多尺度多路径上,通过对图片不同尺度分块及其构成的多路径结构,提升了图像分割中Transformer的精确程度。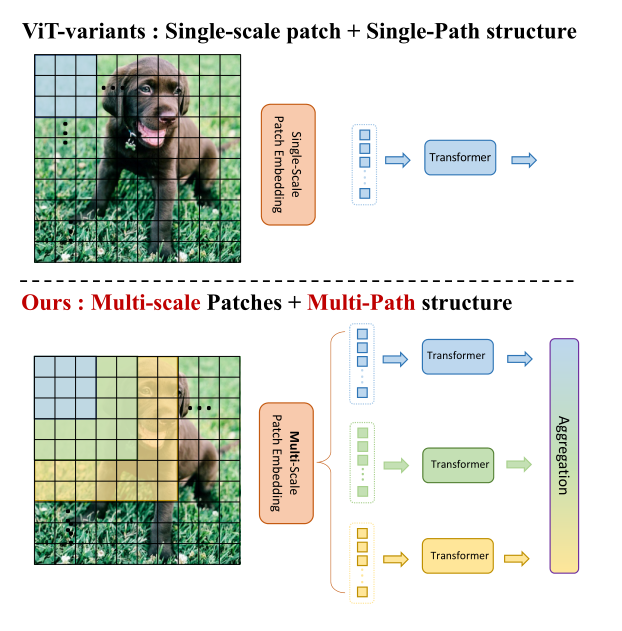
1.2 贡献
- 提出了一个具有多路径结构的多尺度嵌入方法,用于同时表示密集预测任务的精细和粗糙特征。
- 介绍了全局到本地特征交互(GLI),同时利用卷积的局部连通性和Transformer的全局上下文来表示特征。
- 性能优于最先进的vit,同时有更少的参数和运算次数。
2. 网络
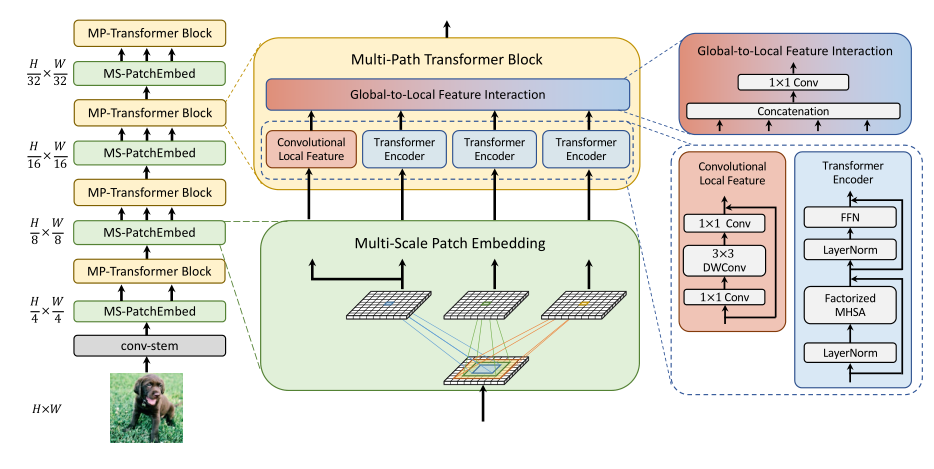
2.1 整体架构
- 首先对输入的图像做卷积提取特征,
- 而后主要分成了四个Transformer阶段,如图左侧一列所示,
- 中间一列是每个阶段中两个小块的展开分析图,
- 右侧一列则是对多路径模块中Transformer(包括局部卷积)以及全局信息模块的图解。
2.2 Conv-stem
本模块由两个3×3卷积组成,可以在不丢失显著信息的情况下对图片进行特征提取以及尺度的减小
输入图像大小为:H×W×3,
两层卷积:采用两个3×3的卷积,通道分别为C2/2,C2,stride为2,
输出图像:生成特征的大小为H/4×W/4×C2,其中C2为stage 2的通道大小。
说明:
1.每个卷积之后都是Batch Normalization 和一个Hardswish激活函数。
2.从stage 2到stage 5,在每个阶段对所提出的Multi-scale Patch Embedding(MS-PatchEmbed)和Multi-path Transformer(MP-Transformer)块进行堆叠。
2.3 Multi-Scale Patch Embedding
多尺度Patch Embedding结构如下,对于输入特征图,使用不同大小的卷积核来得到不同尺度的特征信息(论文这么写的,但是源码看到卷积核都是3),
为了减少参数,使用3x3的卷积核叠加来增加感受野达到5x5、7x7卷积核的感受野,同时使用深度可分离卷积来减少参数。
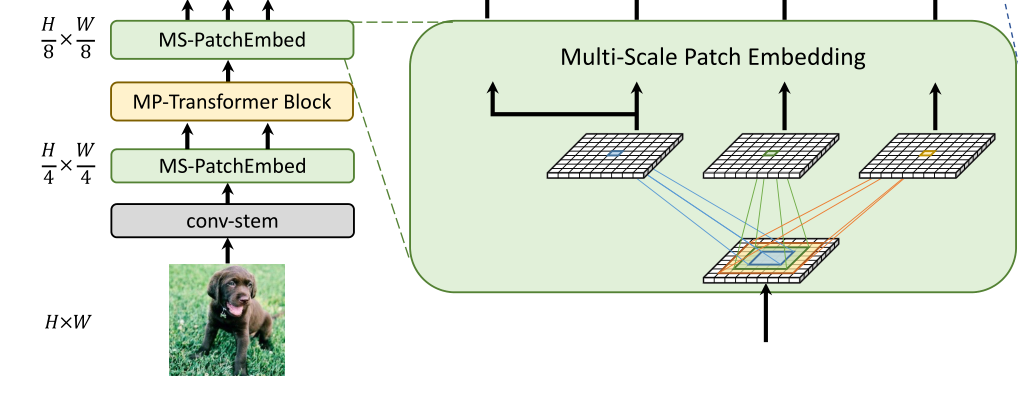
输入图像:
stage i 的输入X,通过一个k×k的2D卷积,s为stride,p为 padding。
输出的token map F的高度和宽度如下:
H i = ⌊ H i − 1 − k + 2 p s ⌋ , W i = ⌊ W i − 1 − k + 2 p s ⌋ H_i=\lfloor \frac{H_{i-1}-k+2p}{s}\rfloor,W_{i=}\lfloor \frac{W_{i-1}-k+2p}{s}\rfloor Hi=⌊sHi−1−k+2p⌋,Wi=⌊sWi−1−k+2p⌋
通过改变stride和padding来调整token的序列长度,即不同块尺寸可以具有相同尺寸的输出。
因此,我们构建了不同核尺寸的并行卷积块嵌入层,如序列长度相同但块尺寸可以为3×3,5×5,7×7
例如,如图1所示,可以生成相同序列长度,不同大小的vision token,patch大小分别为3×3,5×5,7×7
实践
- 由于堆叠同尺寸卷积可以提升感受野且具有更少的参数量,
选择两个连续的3×3卷积层构建5×5感受野,采用三个3×3卷积构建7×7感受野 - 对于triple-path结构,使用三个连续的3×3卷积,通道大小为C’,padding为1,步幅为s,其中s在降低空间分辨率时为2,否则为1。
因此,给定conv-stem的输出X,通过MS-PatchEmbed可以得到相同大小为 H i s × W i s × C ′ \frac{H_i}{s}\times\frac{W_i}{s}\times C^\prime sHi×sWi×C′的特征 F 3 × 3 ( X i ) , F 5 × 5 ( X i ) , F 7 × 7 ( X i ) F_{3\times 3}(X_i),F_{5\times 5}(X_i),F_{7\times 7}(X_i) F3×3(Xi),F5×5(Xi),F7×7(Xi) - 为了减少模型参数和计算开销,采用3×3深度可分离卷积,包括3×3深度卷积和1×1点卷积。
- 每个卷积之后都是Batch Normalization 和一个Hardswish激活函数。
接着,不同大小的token embedding features 分别输入到transformer encoder中。
2.4 Multi-path Transformer
原因:
Transformer中的self-attention可以捕获长期依赖关系(即全局上下文),但它很可能会忽略每个patch中的结构性信息和局部关系。
相反,cnn可以利用平移不变性中的局部连通性,使得CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状。
因此,MPViT以一种互补的方式将CNN与Transformer结合起来。
组成:下面的多路径Transformer和局部特征卷积,上面的Global-to-Local Feature Interaction。
在多路径的特征进行自注意力(局部卷积)计算以及全局上下文信息交互后,所有特征会做一个Concat经过激活函数后进入下一阶段。
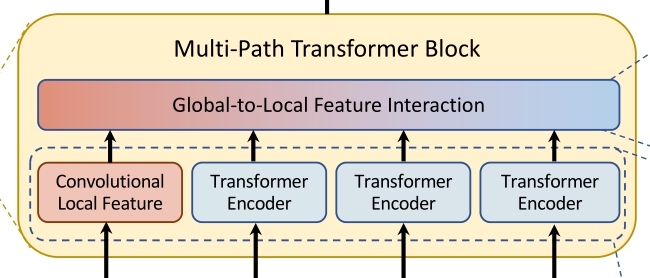
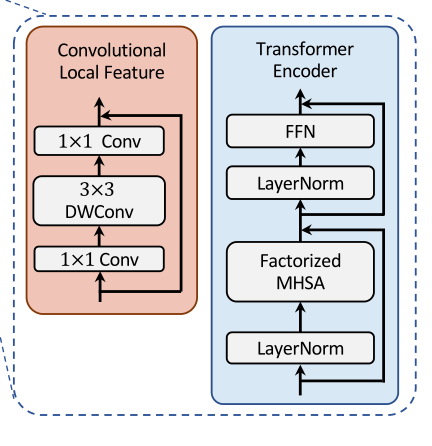
2.4.1 多路径Transformer和局部特征卷积
ansformer可以关注到较远距离的相关性,但是卷积网络却能更好地对图像的局部上下文特征进行提取,因此作者同时加入了这两个互补的操作,实现了本部分。
Transformer
由于每个图像块内作者都使用了自注意力,并且存在多个路径,因此为了减小计算压力,作者使用了CoaT中提出的有效的因素分解自注意(将复杂度降低为线性)
FactorAtt ( Q , K , V ) = Q C ( softmax ( K ) ⊤ V ) \operatorname{FactorAtt}(Q, K, V)=\frac{Q}{\sqrt{C}}\left(\operatorname{softmax}(K)^{\top} V\right) FactorAtt(Q,K,V)=CQ(softmax(K)⊤V)
CNN
为了表示局部特征 L,采用了一个 depthwise residual bottleneck block,包括1×1卷积、3×3深度卷积和1×1卷积和残差连接。在三个Transformer模块的左侧存在一个卷积操作,其实就是通过卷积的局部性,将图像的局部上下文引入模型中,多了这些上下文信息可以弥补Transformer对于局部语义理解的不足。
在原始的计算attention的过程中,空间复杂度是O( N ∗ N N*N N∗N), 时间复杂度是O( N ∗ N ∗ C N*N*C N∗N∗C),
Attn ( X ) = softmax ( Q K T C ) V \operatorname{Attn}(X)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{C}}\right) V Attn(X)=softmax(CQKT)V
- 一个 query 给 n 个 key - value pair ,这个 query 会跟每个 key - value pair 做内积,会产生 n 个相似度值。传入 softmax 得到 n 个非负、求和为 1 的权重值。
output 中 value 的权重 = 查询 query 和对应的 key 的相似度
通常用内积实现,用来衡量每个key对每个query的影响大小把 softmax 得到的权重值 与 value 矩阵 V 相乘 得到 attention 输出。
N、C分别表示 tokens数量和 embedding维度。
Factorized Attention Mechanism: 空间复杂度 O ( N C ) O(NC) O(NC),时间复杂度 O ( N C 2 ) O(NC^2) O(NC2)。复杂度变成原来的 C N \frac{C}{N} NC倍
FactorAtt ( Q , K , V ) = Q C ( softmax ( K ) ⊤ V ) \operatorname { FactorAtt }(Q, K, V)=\frac{Q}{\sqrt{C}}\left(\operatorname{softmax}(K)^{\top} V\right) FactorAtt(Q,K,V)=CQ(softmax(K)⊤V)
为了降低复杂度,类似于LambdaNet中的做法(以恒等函数和softmax的注意力分解机制:),将attention的方法改为如下形式
- 通过使用2个函数对其进行分解,并一起计算第2个矩阵乘法(key和value)来近似softmax attention map:
为了归一化效果将比例因子 根号下c分之一添加回去,带来了更好的性能
FactorAtt ( X ) = ϕ ( Q ) ( ψ ( K ) ⊤ V ) \operatorname{FactorAtt}(X)=\phi(Q)\left(\psi(K)^{\top} V\right) FactorAtt(X)=ϕ(Q)(ψ(K)⊤V)
另一方面在计算原始的attention时可以明确解释attention是当前位置与其他位置的相似度,
但在factor attn的计算过程中并不是很好解释,而且丢失了内积过程。
虽然FactorAttn不是对attn的直接近似,但是也是一种泛化的注意力机制有query,key和value
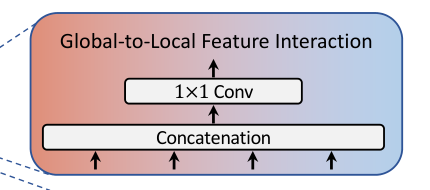
2.4.2 Global-to-Local Feature Interaction
作用
将局部特征和全局特征聚合起来:通过串联来执行
对输入特征做了一个Concat并进行了1×1卷积(H(·)是一个学习与特征交互的函数),该模块同时输入了存在远距离关注的Transformer以及提取局部上下文关系的卷积操作,因此可以认为就是对本阶段提取到的图像全局以及局部语义的特征融合,充分利用了图像的信息。
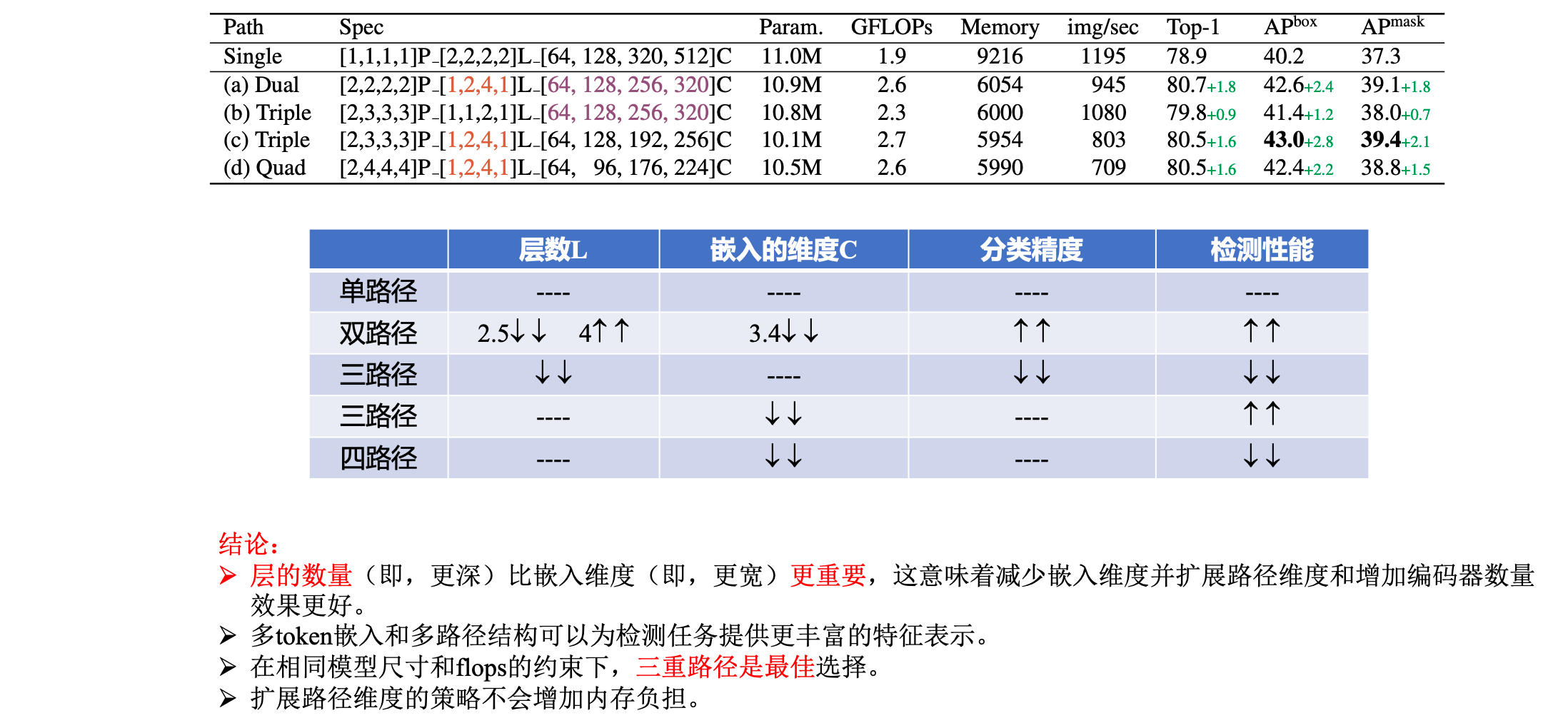
2.5 消融实验
3. 代码
# --------------------------------------------------------------------------------
# MPViT: Multi-Path Vision Transformer for Dense Prediction
# Copyright (c) 2022 Electronics and Telecommunications Research Institute (ETRI).
# All Rights Reserved.
# Written by Youngwan Lee
# This source code is licensed(Dual License(GPL3.0 & Commercial)) under the license found in the
# LICENSE file in the root directory of this source tree.
# --------------------------------------------------------------------------------
# References:
# timm: https://github.com/rwightman/pytorch-image-models/tree/master/timm
# CoaT: https://github.com/mlpc-ucsd/CoaT
# --------------------------------------------------------------------------------
import math
from functools import partial
import numpy as np
import torch
from einops import rearrange
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from torch import einsum, nn
__all__ = [
"mpvit_tiny",
"mpvit_xsmall",
"mpvit_small",
"mpvit_base",
]
def _cfg_mpvit(url="", **kwargs):
"""configuration of mpvit."""
return {
"url": url,
"num_classes": 1000,
"input_size": (3, 224, 224),
"pool_size": None,
"crop_pct": 0.9,
"interpolation": "bicubic",
"mean": IMAGENET_DEFAULT_MEAN,
"std": IMAGENET_DEFAULT_STD,
"first_conv": "patch_embed.proj",
"classifier": "head",
**kwargs,
}
class Mlp(nn.Module):
"""Feed-forward network (FFN, a.k.a. MLP) class. """
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
"""foward function"""
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Conv2d_BN(nn.Module):
"""Convolution with BN module."""
def __init__(
self,
in_ch,
out_ch,
kernel_size=1,
stride=1,
pad=0,
dilation=1,
groups=1,
bn_weight_init=1,
norm_layer=nn.BatchNorm2d,
act_layer=None,
):
super().__init__()
self.conv = torch.nn.Conv2d(in_ch,
out_ch,
kernel_size,
stride,
pad,
dilation,
groups,
bias=False)
self.bn = norm_layer(out_ch)
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
for m in self.modules():
if isinstance(m, nn.Conv2d):
# Note that there is no bias due to BN
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(mean=0.0, std=np.sqrt(2.0 / fan_out))
self.act_layer = act_layer() if act_layer is not None else nn.Identity(
)
def forward(self, x):
"""foward function"""
x = self.conv(x)
x = self.bn(x)
x = self.act_layer(x)
return x
class DWConv2d_BN(nn.Module):
"""Depthwise Separable Convolution with BN module."""
def __init__(
self,
in_ch,
out_ch,
kernel_size=1,
stride=1,
norm_layer=nn.BatchNorm2d,
act_layer=nn.Hardswish,
bn_weight_init=1,
):
super().__init__()
# dw
self.dwconv = nn.Conv2d(
in_ch,
out_ch,
kernel_size,
stride,
(kernel_size - 1) // 2,
groups=out_ch,
bias=False,
)
# pw-linear
self.pwconv = nn.Conv2d(out_ch, out_ch, 1, 1, 0, bias=False)
self.bn = norm_layer(out_ch)
self.act = act_layer() if act_layer is not None else nn.Identity()
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2.0 / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(bn_weight_init)
m.bias.data.zero_()
def forward(self, x):
""" foward function """
x = self.dwconv(x)
x = self.pwconv(x)
x = self.bn(x)
x = self.act(x)
return x
class DWCPatchEmbed(nn.Module):
"""Depthwise Convolutional Patch Embedding layer Image to Patch Embedding."""
def __init__(self,
in_chans=3,
embed_dim=768,
patch_size=16,
stride=1,
act_layer=nn.Hardswish):
super().__init__()
self.patch_conv = DWConv2d_BN(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
act_layer=act_layer,
)
def forward(self, x):
"""foward function"""
x = self.patch_conv(x)
return x
class Patch_Embed_stage(nn.Module):
"""Depthwise Convolutional Patch Embedding stage comprised of `DWCPatchEmbed` layers."""
def __init__(self, embed_dim, num_path=4, isPool=False):
super(Patch_Embed_stage, self).__init__()
self.patch_embeds = nn.ModuleList([
DWCPatchEmbed(
in_chans=embed_dim,
embed_dim=embed_dim,
patch_size=3,
stride=2 if isPool and idx == 0 else 1,
) for idx in range(num_path)
])
def forward(self, x):
"""foward function"""
att_inputs = []
for pe in self.patch_embeds:
x = pe(x)
att_inputs.append(x)
return att_inputs
class ConvPosEnc(nn.Module):
"""Convolutional Position Encoding. Note: This module is similar to the conditional position encoding in CPVT. """
def __init__(self, dim, k=3):
"""init function"""
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2d(dim, dim, k, 1, k // 2, groups=dim)
def forward(self, x, size):
"""foward function"""
B, N, C = x.shape
H, W = size
feat = x.transpose(1, 2).view(B, C, H, W)
x = self.proj(feat) + feat
x = x.flatten(2).transpose(1, 2)
return x
class ConvRelPosEnc(nn.Module):
"""Convolutional relative position encoding."""
def __init__(self, Ch, h, window):
"""Initialization. Ch: Channels per head. h: Number of heads. window: Window size(s) in convolutional relative positional encoding. It can have two forms: 1. An integer of window size, which assigns all attention heads with the same window size in ConvRelPosEnc. 2. A dict mapping window size to #attention head splits (e.g. {window size 1: #attention head split 1, window size 2: #attention head split 2}) It will apply different window size to the attention head splits. """
super().__init__()
if isinstance(window, int):
# Set the same window size for all attention heads.
window = {
window: h}
self.window = window
elif isinstance(window, dict):
self.window = window
else:
raise ValueError()
self.conv_list = nn.ModuleList()
self.head_splits = []
for cur_window, cur_head_split in window.items():
dilation = 1 # Use dilation=1 at default.
padding_size = (cur_window + (cur_window - 1) *
(dilation - 1)) // 2
cur_conv = nn.Conv2d(
cur_head_split * Ch,
cur_head_split * Ch,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split * Ch,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x * Ch for x in self.head_splits]
def forward(self, q, v, size):
"""foward function"""
B, h, N, Ch = q.shape
H, W = size
# We don't use CLS_TOKEN
q_img = q
v_img = v
# Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img = rearrange(v_img, "B h (H W) Ch -> B (h Ch) H W", H=H, W=W)
# Split according to channels.
v_img_list = torch.split(v_img, self.channel_splits, dim=1)
conv_v_img_list = [
conv(x) for conv, x in zip(self.conv_list, v_img_list)
]
conv_v_img = torch.cat(conv_v_img_list, dim=1)
# Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
conv_v_img = rearrange(conv_v_img, "B (h Ch) H W -> B h (H W) Ch", h=h)
EV_hat_img = q_img * conv_v_img
EV_hat = EV_hat_img
return EV_hat
class FactorAtt_ConvRelPosEnc(nn.Module):
"""Factorized attention with convolutional relative position encoding class."""
def __init__(
self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
shared_crpe=None,
):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Shared convolutional relative position encoding.
self.crpe = shared_crpe
def forward(self, x, size):
"""foward function"""
B, N, C = x.shape
# Generate Q, K, V.
qkv = (self.qkv(x).reshape(B, N, 3, self.num_heads,
C // self.num_heads).permute(2, 0, 3, 1, 4))
q, k, v = qkv[0], qkv[1], qkv[2]
# Factorized attention.
k_softmax = k.softmax(dim=2)
k_softmax_T_dot_v = einsum("b h n k, b h n v -> b h k v", k_softmax, v)
factor_att = einsum("b h n k, b h k v -> b h n v", q,
k_softmax_T_dot_v)
# Convolutional relative position encoding.
crpe = self.crpe(q, v, size=size)
# Merge and reshape.
x = self.scale * factor_att + crpe
x = x.transpose(1, 2).reshape(B, N, C)
# Output projection.
x = self.proj(x)
x = self.proj_drop(x)
return x
class MHCABlock(nn.Module):
"""Multi-Head Convolutional self-Attention block."""
def __init__(
self,
dim,
num_heads,
mlp_ratio=3,
drop_path=0.0,
qkv_bias=True,
qk_scale=None,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
shared_cpe=None,
shared_crpe=None,
):
super().__init__()
self.cpe = shared_cpe
self.crpe = shared_crpe
self.factoratt_crpe = FactorAtt_ConvRelPosEnc(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
shared_crpe=shared_crpe,
)
self.mlp = Mlp(in_features=dim, hidden_features=dim * mlp_ratio)
self.drop_path = DropPath(
drop_path) if drop_path > 0.0 else nn.Identity()
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
def forward(self, x, size):
"""foward function"""
if self.cpe is not None:
x = self.cpe(x, size)
cur = self.norm1(x)
x = x + self.drop_path(self.factoratt_crpe(cur, size))
cur = self.norm2(x)
x = x + self.drop_path(self.mlp(cur))
return x
class MHCAEncoder(nn.Module):
"""Multi-Head Convolutional self-Attention Encoder comprised of `MHCA` blocks."""
def __init__(
self,
dim,
num_layers=1,
num_heads=8,
mlp_ratio=3,
drop_path_list=[],
qk_scale=None,
crpe_window={
3: 2,
5: 3,
7: 3
},
):
super().__init__()
self.num_layers = num_layers
self.cpe = ConvPosEnc(dim, k=3)
self.crpe = ConvRelPosEnc(Ch=dim // num_heads,
h=num_heads,
window=crpe_window)
self.MHCA_layers = nn.ModuleList([
MHCABlock(
dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
drop_path=drop_path_list[idx],
qk_scale=qk_scale,
shared_cpe=self.cpe,
shared_crpe=self.crpe,
) for idx in range(self.num_layers)
])
def forward(self, x, size):
"""foward function"""
H, W = size
B = x.shape[0]
for layer in self.MHCA_layers:
x = layer(x, (H, W))
# return x's shape : [B, N, C] -> [B, C, H, W]
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
return x
class ResBlock(nn.Module):
"""Residual block for convolutional local feature."""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.Hardswish,
norm_layer=nn.BatchNorm2d,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.conv1 = Conv2d_BN(in_features,
hidden_features,
act_layer=act_layer)
self.dwconv = nn.Conv2d(
hidden_features,
hidden_features,
3,
1,
1,
bias=False,
groups=hidden_features,
)
self.norm = norm_layer(hidden_features)
self.act = act_layer()
self.conv2 = Conv2d_BN(hidden_features, out_features)
self.apply(self._init_weights)
def _init_weights(self, m):
""" initialization """
if isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
"""foward function"""
identity = x
feat = self.conv1(x)
feat = self.dwconv(feat)
feat = self.norm(feat)
feat = self.act(feat)
feat = self.conv2(feat)
return identity + feat
class MHCA_stage(nn.Module):
"""Multi-Head Convolutional self-Attention stage comprised of `MHCAEncoder` layers."""
def __init__(
self,
embed_dim,
out_embed_dim,
num_layers=1,
num_heads=8,
mlp_ratio=3,
num_path=4,
drop_path_list=[],
):
super().__init__()
self.mhca_blks = nn.ModuleList([
MHCAEncoder(
embed_dim,
num_layers,
num_heads,
mlp_ratio,
drop_path_list=drop_path_list,
) for _ in range(num_path)
])
self.InvRes = ResBlock(in_features=embed_dim, out_features=embed_dim)
self.aggregate = Conv2d_BN(embed_dim * (num_path + 1),
out_embed_dim,
act_layer=nn.Hardswish)
def forward(self, inputs):
"""foward function"""
att_outputs = [self.InvRes(inputs[0])]
for x, encoder in zip(inputs, self.mhca_blks):
# [B, C, H, W] -> [B, N, C]
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
att_outputs.append(encoder(x, size=(H, W)))
out_concat = torch.cat(att_outputs, dim=1)
out = self.aggregate(out_concat)
return out
class Cls_head(nn.Module):
"""a linear layer for classification."""
def __init__(self, embed_dim, num_classes):
"""initialization"""
super().__init__()
self.cls = nn.Linear(embed_dim, num_classes)
def forward(self, x):
"""foward function"""
# (B, C, H, W) -> (B, C, 1)
x = nn.functional.adaptive_avg_pool2d(x, 1).flatten(1)
# Shape : [B, C]
out = self.cls(x)
return out
def dpr_generator(drop_path_rate, num_layers, num_stages):
"""Generate drop path rate list following linear decay rule."""
dpr_list = [
x.item() for x in torch.linspace(0, drop_path_rate, sum(num_layers))
]
dpr = []
cur = 0
for i in range(num_stages):
dpr_per_stage = dpr_list[cur:cur + num_layers[i]]
dpr.append(dpr_per_stage)
cur += num_layers[i]
return dpr
class MPViT(nn.Module):
"""Multi-Path ViT class."""
def __init__(
self,
img_size=224,
num_stages=4,
num_path=[4, 4, 4, 4],
num_layers=[1, 1, 1, 1],
embed_dims=[64, 128, 256, 512],
mlp_ratios=[8, 8, 4, 4],
num_heads=[8, 8, 8, 8],
drop_path_rate=0.0,
in_chans=3,
num_classes=1000,
**kwargs,
):
super().__init__()
self.num_classes = num_classes
self.num_stages = num_stages
dpr = dpr_generator(drop_path_rate, num_layers, num_stages)
self.stem = nn.Sequential(
Conv2d_BN(
in_chans,
embed_dims[0] // 2,
kernel_size=3,
stride=2,
pad=1,
act_layer=nn.Hardswish,
),
Conv2d_BN(
embed_dims[0] // 2,
embed_dims[0],
kernel_size=3,
stride=2,
pad=1,
act_layer=nn.Hardswish,
),
)
# Patch embeddings.
self.patch_embed_stages = nn.ModuleList([
Patch_Embed_stage(
embed_dims[idx],
num_path=num_path[idx],
isPool=False if idx == 0 else True,
) for idx in range(self.num_stages)
])
# Multi-Head Convolutional Self-Attention (MHCA)
self.mhca_stages = nn.ModuleList([
MHCA_stage(
embed_dims[idx],
embed_dims[idx + 1]
if not (idx + 1) == self.num_stages else embed_dims[idx],
num_layers[idx],
num_heads[idx],
mlp_ratios[idx],
num_path[idx],
drop_path_list=dpr[idx],
) for idx in range(self.num_stages)
])
# Classification head.
self.cls_head = Cls_head(embed_dims[-1], num_classes)
self.apply(self._init_weights)
def _init_weights(self, m):
"""initialization"""
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_classifier(self):
"""get classifier function"""
return self.head
def forward_features(self, x):
"""forward feature function"""
# x's shape : [B, C, H, W]
x = self.stem(x) # Shape : [B, C, H/4, W/4]
for idx in range(self.num_stages):
att_inputs = self.patch_embed_stages[idx](x)
x = self.mhca_stages[idx](att_inputs)
return x
def forward(self, x):
"""foward function"""
x = self.forward_features(x)
# cls head
out = self.cls_head(x)
return out
@register_model
def mpvit_tiny(**kwargs):
"""mpvit_tiny : - #paths : [2, 3, 3, 3] - #layers : [1, 2, 4, 1] - #channels : [64, 96, 176, 216] - MLP_ratio : 2 Number of params: 5843736 FLOPs : 1654163812 Activations : 16641952 """
model = MPViT(
img_size=224,
num_stages=4,
num_path=[2, 3, 3, 3],
num_layers=[1, 2, 4, 1],
embed_dims=[64, 96, 176, 216],
mlp_ratios=[2, 2, 2, 2],
num_heads=[8, 8, 8, 8],
**kwargs,
)
model.default_cfg = _cfg_mpvit()
return model
@register_model
def mpvit_xsmall(**kwargs):
"""mpvit_xsmall : - #paths : [2, 3, 3, 3] - #layers : [1, 2, 4, 1] - #channels : [64, 128, 192, 256] - MLP_ratio : 4 Number of params : 10573448 FLOPs : 2971396560 Activations : 21983464 """
model = MPViT(
img_size=224,
num_stages=4,
num_path=[2, 3, 3, 3],
num_layers=[1, 2, 4, 1],
embed_dims=[64, 128, 192, 256],
mlp_ratios=[4, 4, 4, 4],
num_heads=[8, 8, 8, 8],
**kwargs,
)
model.default_cfg = _cfg_mpvit()
return model
@register_model
def mpvit_small(**kwargs):
"""mpvit_small : - #paths : [2, 3, 3, 3] - #layers : [1, 3, 6, 3] - #channels : [64, 128, 216, 288] - MLP_ratio : 4 Number of params : 22892400 FLOPs : 4799650824 Activations : 30601880 """
model = MPViT(
img_size=224,
num_stages=4,
num_path=[2, 3, 3, 3],
num_layers=[1, 3, 6, 3],
embed_dims=[64, 128, 216, 288],
mlp_ratios=[4, 4, 4, 4],
num_heads=[8, 8, 8, 8],
**kwargs,
)
model.default_cfg = _cfg_mpvit()
return model
@register_model
def mpvit_base(**kwargs):
"""mpvit_base : - #paths : [2, 3, 3, 3] - #layers : [1, 3, 8, 3] - #channels : [128, 224, 368, 480] MLP_ratio : 4 Number of params: 74845976 FLOPs : 16445326240 Activations : 60204392 """
model = MPViT(
img_size=224,
num_stages=4,
num_path=[2, 3, 3, 3],
num_layers=[1, 3, 8, 3],
embed_dims=[128, 224, 368, 480],
mlp_ratios=[4, 4, 4, 4],
num_heads=[8, 8, 8, 8],
**kwargs,
)
model.default_cfg = _cfg_mpvit()
return model
if __name__ == "__main__":
model = mpvit_xsmall()
from thop import profile
# model = convnext_tiny(num_classes=5)
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input,))
print("flops:{:.3f}G".format(flops /1e9))
print("params:{:.3f}M".format(params /1e6))
参考链接
【CVPR2022】MPViT : Multi-Path Vision Transformer for Dense Prediction - 知乎 (zhihu.com)
论文阅读:MPViT : Multi-Path Vision Transformer for Dense Prediction_甜橙不加冰的博客-CSDN博客
【深度学习】语义分割:论文阅读:(CVPR 2022) MPViT(CNN+Transformer):用于密集预测的多路径视觉Transformer_sky_柘的博客-CSDN博客
边栏推荐
- esp32和ros2基础篇草稿-micro-ros-
- 【Autosar RTM】
- UE5 官方案例Lyra 全特性详解 8.如何用配置表初始化角色数据
- 别再到处乱放配置文件了!我司使用 7 年的这套解决方案,稳的一秕
- Auto.js special positioning control method cannot perform blocking operations on the ui thread, please use setTimeout instead
- 数据库审计 - 网络安全的重要组成部分
- 典型相关分析CCA计算过程
- 基于rt-thread studio的STM32裸机开发——LED
- Heartwarming AI Review (1)
- D with json
猜你喜欢
Wireshark数据抓包分析之传输层协议(TCP协议)

程序员常说的“左手锟斤拷,右手烫烫烫”是怎么回事?

js显示隐藏手机号
NLP commonly used Backbone model cheat sheet (1)
高数---二重积分

用了TCP协议,就一定不会丢包吗?

用了这么多年的LinkedList,作者说自己从来不用它?为什么?

VMware workstation program starts slowly
嵌入式分享合集26
Teach you to locate online MySQL slow query problem hand by hand, package teaching package meeting

随机推荐
6、Powershell命令配置Citrix PVS云桌面桌面注销不关机
浅谈I2C知识
别再到处乱放配置文件了!我司使用 7 年的这套解决方案,稳的一秕
停止使用 Storyboards 和 Interface Builder
LVM与磁盘配额原理及配置
3、Xendesktop更改发布桌面的显示名称(MCS静态桌面)
DB2数据库-获取表结构异常:[jcc][t4][1065][12306][4.26.14]CharConvertionException ERRORCODE=-4220,SQLSTATE=null
CKAN教程之将 Snowflake 连接到 CKAN 以发布到开放数据门户
优秀论文以及思路分析01
Auto.js 特殊定位控件方法 不能在ui线程执行阻塞操作,请使用setTimeout代替
北路智控上市首日破发:公司市值59亿 募资15.6亿
2022中国眼博会,山东眼健康展,视力矫正仪器展,护眼产品展
js基础知识整理之 —— 字符串
如何正确地配置入口文件?
Nacos配置中心之事件订阅
牛客网剑指offer刷题练习之链表中环的入口结点
js基础知识整理之 —— 全局作用域
令人心动的AI综述(1)
RollBack Rx Professional RMC 安装教程
Connect the Snowflake of CKAN tutorial CKAN to release to open data portal