当前位置:网站首页>Crawl national laws and Regulations Database
Crawl national laws and Regulations Database
2022-06-27 19:40:00 【Mozi】
Part1 The experiment purpose
Now the era of big data has come , Web crawler technology has become an indispensable part of this era . The target objects of the crawler are also very rich , No matter the words 、 picture 、 video , Any structured or unstructured data crawler can crawl . Enterprises need data to analyze user behavior , To analyze the shortcomings of our products , To analyze competitors' information, etc . Personal adoption Spyder Crawler software , Crawl the information we need , We can get some information in advance through the crawler , Such as : We can rob tickets by crawling , Scramble for classes , Get information about the transfer of postgraduate entrance examination, etc . This paper takes crawling the database data of national laws and regulations as an example .
The author of this article : Jiangxi Agricultural University School of economics and management Finance 1903 Fuyan
Part2 The experimental steps
1 Watch the web page
By looking at the web page, we find , Enter the provisions of laws and regulations , The website has not changed , Say that the web page is a dynamic web page .


2 Request web page
Right click on the browser “ Check ”, Click on “ The Internet ”, Select... In the interface that appears “Fetch/XHR” Button , And refresh the page . adopt Ctrl+F Find out about , Click the link that appears , We click “ preview ”, Found the title we need 、 Enacting authority 、 Legal nature 、 timeliness 、 The release date and other information are here , Click on “ header ” You can see the real address of the web page address . 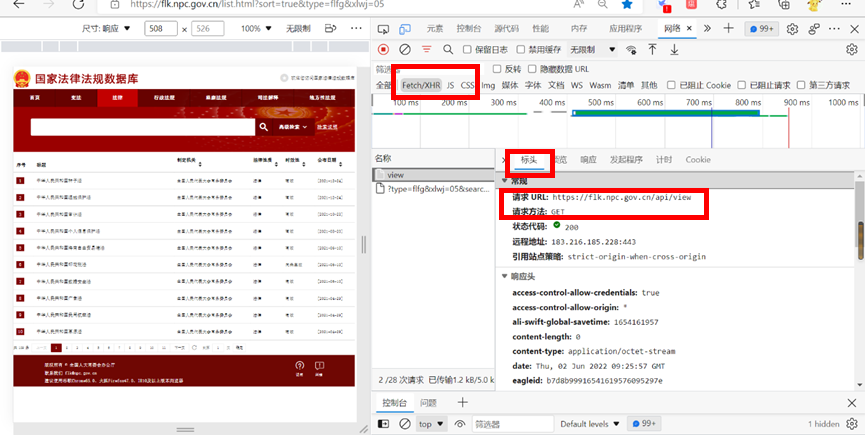

3 Try to get the information on the first page
Use requests Request database , The request method is get,

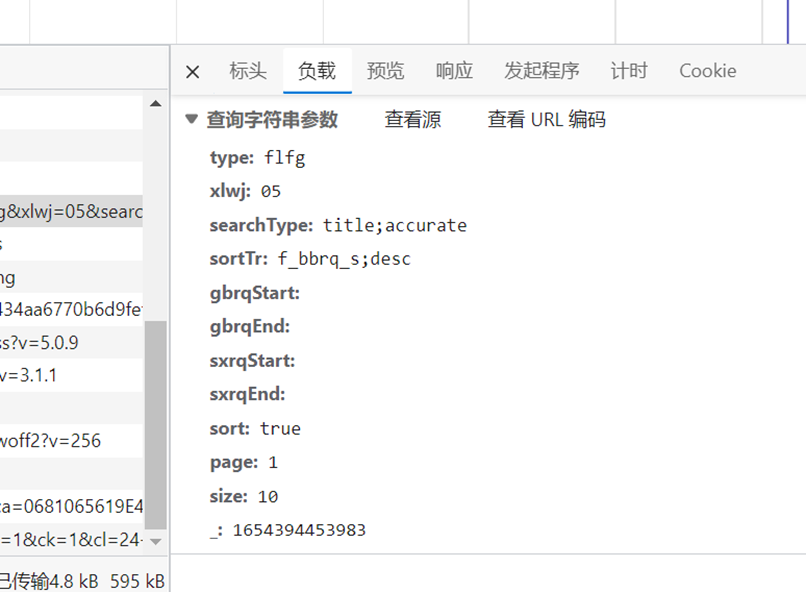
We see the “ header ” The discovery request method is get request , see “ load ” And click the , That is to say get Requested parameters .Request The request code is as follows :
import requests
items=[]
url='https://flk.npc.gov.cn/api/?type=flfg&xlwj=05&searchType=title%3Baccurate&sortTr=f_bbrq_s%3Bdesc&gbrqStart=&gbrqEnd=&sxrqStart=&sxrqEnd=&sort=true&page=1&size=10&_=1654157294070'
r=requests.get(url)
4 Parsing data , Store the data
Because the web page returns json Format data , Get the title we need 、 Enacting authority 、 Legal nature 、 timeliness 、 Release date , We can access it through the dictionary . How to get the web link of each regulation ? We click on the first rule , Found its URL suffix stored in url in , You can get a complete link to the detailed interface of regulations .
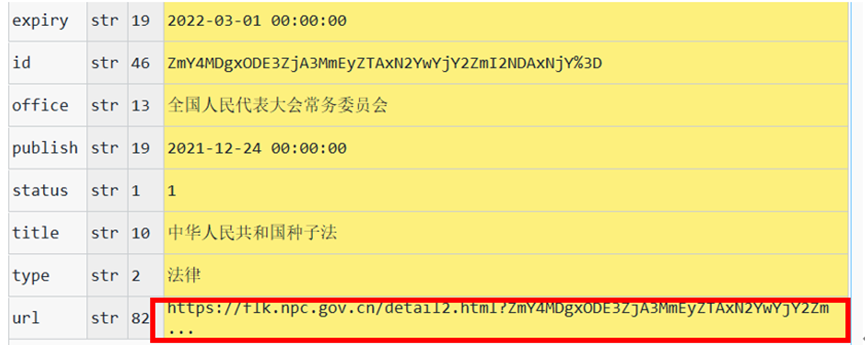

First embed the dictionary parsing library , By accessing the dictionary , Extract the data layer by layer to get all the information of a page , Edit code :
json=r.json()
pagelist=json['result']['data']
office=page['office']
title=page['title']
type=page['type']
date=page['publish']
page=[url]
5 Through the loop , Crawl all pages of regulatory data
The key to page crawling is to find the real address “ Page turning ” law . Let's click on... Respectively 1 page 、 The first 2 page 、 The first 3 page , Find different page numbers except page Inconsistent parameters , The rest are the same . The first 1 page “page” yes 1, The first 2 page “page” yes 2, The first 2 page “page” yes 2, And so on . 
 We nested one For loop , And pass pandas as pd Store the data . Run the code to make it crawl automatically 1-11 Regulatory information for , And store it 666661.csv In the file of , All the codes are as follows :
We nested one For loop , And pass pandas as pd Store the data . Run the code to make it crawl automatically 1-11 Regulatory information for , And store it 666661.csv In the file of , All the codes are as follows :
items=[]
url='https://flk.npc.gov.cn/api/?type=flfg&xlwj=05&searchType=title%3Baccurate&sortTr=f_bbrq_s%3Bdesc&gbrqStart=&gbrqEnd=&sxrqStart=&sxrqEnd=&sort=true&page=1&size=10&_=1654157294070'
for i in range(1,11):
form_data={'page': 1,
'size': 10}
r=requests.get(url)
json=r.json()
pagelist=json['result']['data']
for page in pagelist:
office=page['office']
title=page['title']
type=page['type']
date=page['publish']
page=[url]
item=[title,office,type,date,page]
items.append(item)
import pandas as pd
df=pd.DataFrame(items)
df.to_csv('666661.csv',encoding='utf-8-sig')
Last , The crawling data results are as follows :

边栏推荐
- 华大单片机KEIL报错_WEAK的解决方案
- im即时通讯开发之双进程守护保活实践
- 基于STM32F103ZET6库函数跑马灯实验
- Common errors and solutions of MySQL reading binlog logs
- 金源高端IPO被终止:曾拟募资7.5亿 儒杉资产与溧阳产投是股东
- CDGA|交通行业做好数字化转型的核心是什么?
- Keras deep learning practice (12) -- facial feature point detection
- Teach you how to install Oracle 19C on Windows 10 (detailed picture and text with step on pit Guide)
- [elt.zip] openharmony paper Club - memory compression for data intensive applications
- Solution to Maxwell error (MySQL 8.x connection)
猜你喜欢

Don't worry. This is the truth about wages in all industries in China

Summary of domestic database certification test guide (updated on June 16, 2022)

【ELT.ZIP】OpenHarmony啃论文俱乐部—数据密集型应用内存压缩

Minmei new energy rushes to Shenzhen Stock Exchange: the annual accounts receivable exceeds 600million and the proposed fund-raising is 450million

从感知机到前馈神经网络的数学推导

What is ICMP? What is the relationship between Ping and ICMP?

如何利用 RPA 实现自动化获客?

PCB线路板蛇形布线要注意哪些问题?

International School of Digital Economics, South China Institute of technology 𞓜 unified Bert for few shot natural language understanding

binder hwbinder vndbinder
随机推荐
金源高端IPO被终止:曾拟募资7.5亿 儒杉资产与溧阳产投是股东
Character interception triplets of data warehouse: substrb, substr, substring
NVIDIA Clara-AGX-Developer-Kit installation
利用OpenCV执行相机校准
Memoirs of actual combat: breaking the border from webshell
数据分析师太火?月入3W?用数据告诉你这个行业的真实情况
IDEA 官网插件地址
明美新能源冲刺深交所:年应收账款超6亿 拟募资4.5亿
工作流自动化 低代码是关键
数仓的字符截取三胞胎:substrb、substr、substring
基于STM32F103ZET6库函数蜂鸣器实验
The Fifth Discipline: the art and practice of learning organization
Where to look at high-yield bank financial products?
信息学奥赛一本通 1335:【例2-4】连通块
Bit. Store: long bear market, stable stacking products may become the main theme
binder hwbinder vndbinder
NVIDIA Clara-AGX-Developer-Kit installation
PCB线路板蛇形布线要注意哪些问题?
网络传输是怎么工作的 -- 详解 OSI 模型
What is ICMP? What is the relationship between Ping and ICMP?