当前位置:网站首页>I/O性能与可靠性
I/O性能与可靠性
2022-08-05 05:19:00 【生病的毛毛虫】
I/O调优
磁盘I/O优化
- 性能检测:
- 压力测试应用程序,观察系统I/O wait指标是否正常,例如有n个CPU,利息情况下I/O wait参数不超过25%,如果超过,就是这个程序的瓶颈就是在IO操作上了可以用iostat命令查看
- 另外一个指标:IOPS(input/output Per Second)即每秒的输入输出量,是衡量磁盘性能主要指标
- 每个磁盘的IOPS通常在一个范围内,这和存储的磁盘数据块大小和磁盘范围方式有关系,主要由磁盘的转速决定的,转速越高,IOPS越高。
- 性能提升:现阶段一般采用RAID技术,将不同磁盘组合来提高I/O性能
RAID
- 名词解释:RAID(独立磁盘冗余阵列)技术是将多块普通磁盘组成一个大的磁盘阵列,共同对外提供服务。
- 目的:主要为改善磁盘存储容量,读写速度(IOPS)增强磁盘可用性和容错能力。
- 解决数据存储容量问题
- 数据读写速度问题
- 数据可靠性问题
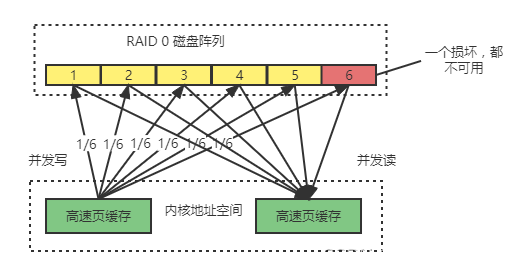
RAID 0
- RAID 0 模式写:假设服务器有N快磁盘,当前模式是数据从内存缓冲区写入磁盘时,根据磁盘数量将数据等分成N份,这些数据同时并发写入N块磁盘,使数据写入速度是一块磁盘的N倍。
- RAID 0 模式读:读取的时候也一样,可以多块磁盘并发的读,因此RAID 0 有很快的数据读取能力。
- RAID 0 缺点:数据没有做备份,N块磁盘存储一块内存缓冲区的数据,一块磁盘损坏,所有数据都无法使用
RAID 1
- RAID 1 写:将一份数据同时写入两份磁盘,这样任何一块磁盘损坏都不会导致数据丢失,插入一块磁盘可以通过复制数据的方式修复,具有极高的可靠性
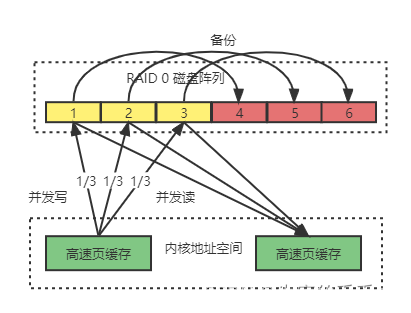
RAID 1 0
- 结合RAID 0 和RAID 1 ,将所有磁盘N平均分2份,数据同时写入2份磁盘,,相当于RAID1;然后在平均分成2份,在每一份磁盘(也就是其中的N/2快磁盘)里面,利用RAID 0 技术并发读写
- 优点:既可以提供高性能的读写能力,也同时具备高可靠性
- 缺点:磁盘利用率直接降低到50%,一半用来做数据备份了
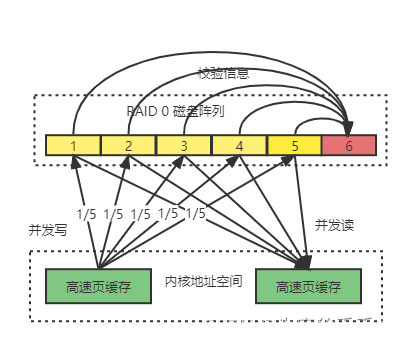
RAID 3
- RAID 3 的思路是提高磁盘利用率,将数据分成N-1份,并发写入N-1个磁盘中,并且在第N块磁盘记录校验数据,这样任何一块磁盘损坏(包括校验数据磁盘),都可以利用其它N - 1 块磁盘的数据进行修复
- 缺点:物理你修改那一块磁盘的数据,第N快校验的数据都需要修改,那边第N快磁盘的读写评率是其他N-1块之和,那么这块磁盘更容易损坏,因此实际很少用这种情况
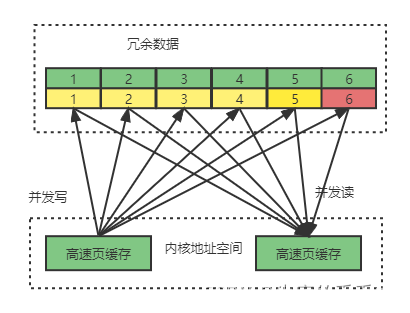
RAID 5
- 与RAID 3 类似,但是校验数据不写入第N快磁盘,而是通过一定的方式将校验数据写入到所有磁盘中,这样校验数据的修改也被平均到所有磁盘,避免RAID 3 这种一块磁盘损坏的情况。
RAID 6
- 当数据可靠性要求很高,再出现同时损坏2块磁盘的时候(概率很低)任然会出现无法通过校验信息修复的情况,只能通过运维数据恢复,这样我们可以使用RAID 6
- RAID 6 与RAID 5类似,但是数据值写入了N - 2块磁盘,并且螺旋式地在两块磁盘中写入校验信息(分别用不同算法),这样校验信息也有备份了,有更高的可靠性
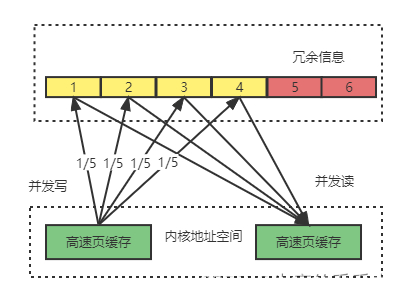
校验数据设计
- 一下冗余磁盘阵列RAID,使用奇偶校验的方式实现冗余,如果一个阵列中一块磁盘出现故障,工作磁盘中的数据块与奇偶校验块一起来重建丢失的数据,如下案例,A1,A2, A3是数据块 Ap表示校验数据块(An与Ap可能在同一个磁盘)
- 例 A1 = 0000 0111 ,A2 = 0000 0101 , A3 = 0000 0000,
- A1 , A2, A3 做异或操作,得到Ap = 0000 0010
- 此时 A2 出现问题,我们可以通过A1, A3 与Ap 的异或进行重建: A1 XOR A3 XOR Ap = 0000 0101
RAID总结
| RAID类型 | 访问速度 | 数据可靠性 | 磁盘利用率 |
|---|---|---|---|
| ARID0 | 很快 | 很低 | 100% |
| ARID1 | 很慢 | 很高 | 50% |
| ARID10 | 中的 | 很高 | 50% |
| ARID5 | 较快 | 很高 | (N-1)/N |
| ARID6 | 较快 | 很高 | (N-2)/N |
解决问题:
数据存储容量问题:RAID用多块磁盘组成存储阵列,例如RAID 5 可以扩大N-1倍
数据读写速度:将数据并发写入 N份磁盘,写入速度明显提升,同时读取也是一样,但是并不能提升N倍,因为机械硬盘延迟主要是用来寻址的时间,数据真正读写时间只占一小部分。
数据可靠性使用RAID 10,RAID 5, RAID 6,由于数据冗余存储,或者存储校验信息,某一块磁盘损坏,可以通过其他磁盘数据,或者校验数据,将丢失数据还原。
RAID可以看成是垂直伸缩,一台计算机集成更多磁盘,实现数据更大规模,更安全可靠存储以及更快的范问速度。
将RAID思想原理应用到分布式服务器上,吧每一台服务器看成是磁盘中的一个,那么就形成了分布式存储,Hadoop分布式文件系统和HDFS的架构思想。
边栏推荐
- Lua,ILRuntime, HybridCLR(wolong)/huatuo热更对比分析
- 游戏引擎除了开发游戏还能做什么?
- 静态路由
- 2020,Laya最新中高级面试灵魂32问,你都知道吗?
- 每日一题-三数之和-0716(2)
- 【Day8】Knowledge about disk and disk partition
- [Day6] File system permission management, file special permissions, hidden attributes
- Getting Started Document 01 series in order
- Getting Started 03 Distinguish between development and production environments ("hot update" is performed only in the production environment)
- 【Day1】VMware软件安装
猜你喜欢

随机推荐
spark算子-map vs mapPartitions算子
游戏引擎除了开发游戏还能做什么?
虚幻引擎5都有哪些重要新功能?
账号与权限管理
每日一题-DFS
Autoware--北科天绘rfans激光雷达使用相机&激光雷达联合标定文件验证点云图像融合效果
【Day8】使用LVM扩容所涉及的命令
通过单总线调用ds18b20的问题
每日一题-正则表达式匹配-0715
CIPU,对云计算产业有什么影响
如何用UE5渲染一个可爱的茶壶屋?
每日一题-二分法
【Day1】VMware软件安装
OpenCV3.0 兼容VS2010与VS2013的问题
Wireshark抓包及常用过滤方法
Remembering my first CCF-A conference paper | After six rejections, my paper is finally accepted, yay!
图片压缩失效问题
腾讯内部技术:《轩辕传奇》服务器架构演变
网络布线与数制转换
入门文档05 使用cb()指示当前任务已完成