当前位置:网站首页>DUF:Deep Video Super-Resolution Network Using Dynamic Upsampling Filters ... Reading notes
DUF:Deep Video Super-Resolution Network Using Dynamic Upsampling Filters ... Reading notes
2022-06-12 08:05:00 【Xiao Lian who wrote a bug】
DUF:Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without Explicit Motion Compensation
DUF: Deep video super-resolution network with dynamic up sampling filter without explicit motion compensation
Code :https://github.com/yhjo09/VSR-DUF
Personal recurrence (pytorch):GitHub - gedulding/VSR_DUF_pytorch: According to the author's paper and code, it is converted to pytorch implementation. This code can be used as the basis for reproducing this paper. And the code content can be used as a template
This note mainly reads and analyzes the whole paper from beginning to end , This article is a little bit more , It mainly summarizes the different parts and explains the legend , If you are only interested in the principle part of the model , You can watch the fourth part directly .
In order to explain each figure in detail 、 The situation of the formula in each component , So the original picture 、 The formula is cut and spliced , Ensure that the content is effective in the component .
Catalog
(4) This paper introduces the method of
(4.1) Dynamic upsampling filter
(4.3) Design of network structure
(5.1) Learning the visualization of movement :
(5.1.3) Dynamic up sampling filter
(1) Abstract
At present, based on deep learning VSR Most methods rely on the accuracy of display motion compensation , That is, the accuracy of motion estimation and motion compensation . This paper proposes an end-to-end network , The network contains dynamic upsampling filter And residual image processing , Dynamic upsampling using implicit information filter Generation ( Implicit motion compensation does not require complex motion estimation , The complementary information between frames is used for frame compensation ), The details of space-time domain are supplemented by residual network , And then through up sampling filter The reconstruction HR Images , Assist in the generation of a data enhanced technology HR video .
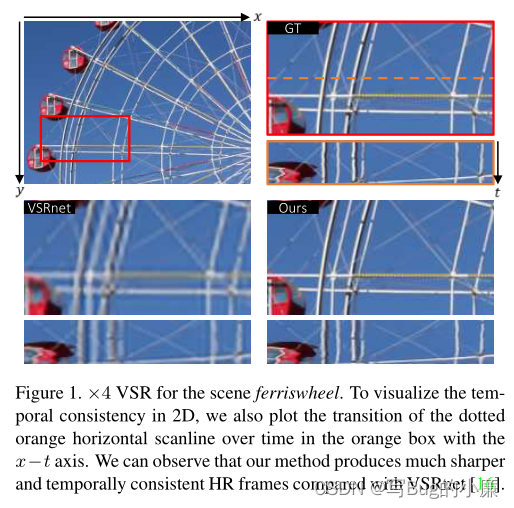
( Let me use my BasicVSR Compare with the comparison chart in , It can be downloaded from DUF Parameters of , Exercise time and PSNR See the basic effect of this algorithm , Let us have a general sense of this algorithm )

(2) introduction
Existing hardware equipment 4K and 8K Your screen often doesn't have the right content for that resolution , Image hypersegmentation is to perform irrelevant hypersegmentation on each frame of the video , However, this kind of super branch leads to the problem of artifact and flicker between images without considering the space-time relationship . Conventional VSR The algorithm is to calculate the sub-pixel motion , Calculate two LR Between images Displacement between subpixels ( Here's the picture ), The follow-up method based on deep learning is based on the above ideas , Display motion compensation , Through motion estimation and motion compensation, the details between frames are aligned and supplemented , And then by up sampling HR video , But there are two problems with this approach :1, It depends heavily on the accuracy of motion estimation and compensation .2, Mix from multiple LR The target frame of the frame will blur the restored image .

(LR The relationship between subpixels between graphs , Subpixel displacement is actually performed by calculating two LR Displacement alignment is carried out according to the position relationship between sub pixels between images , Then add the details that the target frame does not have )
The method designed in this paper , As shown in the figure below , By performing implicit motion compensation calculation on multiple input video frames , Generate corresponding dynamic upsampling filter, Then a pixel of the input target frame is directly locally filtered , Generate high resolution images . Generate filter The size of the is related to the resolution at which you want to perform the super division , Over score 4 times , Generate a filter by 5*5*4*4( In the figure 3,3,3,3, The first two 3,3 Represents the magnification coordinates , The latter two 3,3, from 0 The beginning represents the magnified pixel The location of ),filter The number of channels 16, It can be done for one pixel block 16 Time calculation , That is, the height and width of the tile are 4 Times the image .

A simple comparison between the method in this paper and the latest method .(18 Articles from )
(3) Related work
The picture and video hyperscores are explained , For the current algorithm and solution for video hyperdivision .
(4) This paper introduces the method of
GT What is a frame ?GT Frame actually means high resolution 、 An unprocessed image . Processing means : Down sampling , Fuzzy 、 noise 、 Compression and other image processing means .
First of all, from the GT Low resolution is extracted by down sampling in the frame LR Frame group , As input to the network . Then use dynamic upsampling filter Generate an enlarged image , Use the residual network for input LR High frequency feature extraction of the frame is added to the enlarged picture , Generate the last HR Images . The network structure is shown in the figure below . Overall logic formula such as formula (1) Shown :N It's input LR The time radius of the frame ,G It's the Internet ,θ It's network parameters . Online The input tensor is T*H*W*C,T=2*N+1 Enter the number of reference frames and support frames for ,H and W It's input LR The height and width of the frame ,C Is the number of color channels . The output tensor is :1*rH*rW*C,r Is the amplification factor .
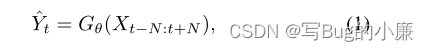

(4.1) Dynamic upsampling filter
Traditional upsampling filter It's fixed filter Content , With the movement of pixels, the local features are dynamically filtered , Use n*n(n It's usually 3、5) Fixed kernel , The internal contents are the same for up sampling . There is no more suitable method based on the information of different positions and different times of the image filter, So this paper dynamically generates upsampling filter, Generated according to the motion of pixels filter, You can avoid displaying motion compensation , No additional motion estimation operation is required .
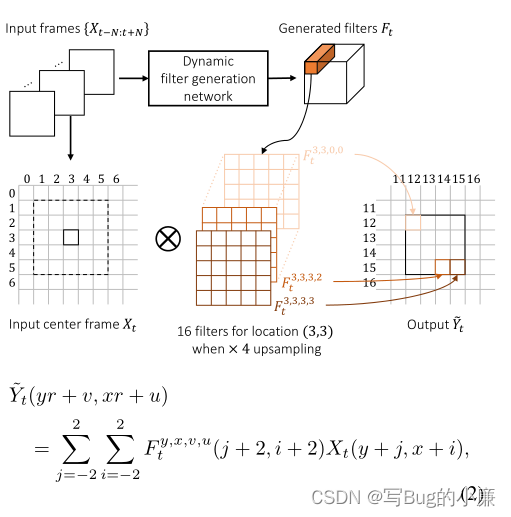
Here's the picture , According to the figure below and the formula below (2), The first input frame is ![]() For input LR Frame group , For input reference 2*N+1 A frame ,( If no statement , The image magnification in this paper is 4 times ), Different... Are generated for pixels at different positions filter, be-all filter form
For input LR Frame group , For input reference 2*N+1 A frame ,( If no statement , The image magnification in this paper is 4 times ), Different... Are generated for pixels at different positions filter, be-all filter form ![]() , The size of the orange part is 5*5*4*4, A dynamic up sampling filter is generated . Then the input target image , Use up sampling filter , The pixels in an area are magnified by four times , Generate output image
, The size of the orange part is 5*5*4*4, A dynamic up sampling filter is generated . Then the input target image , Use up sampling filter , The pixels in an area are magnified by four times , Generate output image ![]() .
.
The formula (2) It means , The original image size is y*x, Use the grid to represent the position of each pixel in the grid .v,u, For use filter Filter generated 4*4 Location of pixel blocks , for example (0,0),(0,1) wait , Generated HR The pixel is ![]() , among
, among ![]() It's a filter in different areas .
It's a filter in different areas .
(4.2) Residual learning
The application of residual module in , The baseline is generated by a dynamic up sampling filter HR The image is not clear , Lack of high frequency and detailed information , Therefore, the residual network is used to extract high-frequency information from the input frame information , And it is fused with the up sampled information , Generate high frequency information HR Images .
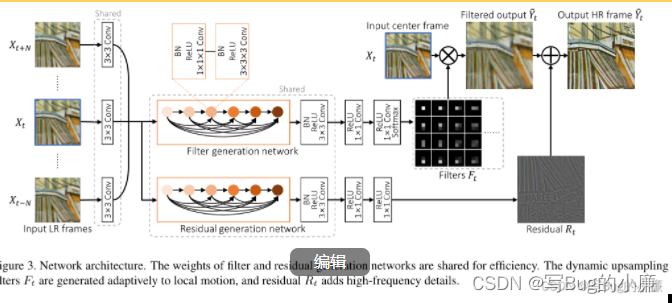
(4.3) Design of network structure
The design of the network structure is mainly as shown in the figure above , The network is not complicated , Convolution in the concrete structure is also marked .
(4.4) Time increases
This part , It is data acquisition before data processing , In order to train the network to adapt to the real world , Generate data sets of appropriate quality , Using variables TA To determine the time interval for time enhancement , Then the video frames are sampled ,TA A negative value generates a reverse video sample . As shown in the figure below .

(5) experiment
Training data set :Val4( Collect the processed data for the algorithm )
Test data set :Vid4
Iterative optimizer :Adam optimizer
Learning rate : feature extraction 10^-3, Every time 10 individual epoch,rate*0.1
Input LR Size :32*32
BatchSize:16
Loss function :huber loss( Here's the picture )

(5.1) Learning the visualization of movement :
(5.1.1) Synthetic motion test
According to my understanding, this test , First, this part of the experiment is to prove that the corresponding information can be normally obtained according to the implicit motion compensation between frames without displaying the motion estimation . As shown in the figure below : The author in GT A vertical bar is synthesized in the frame to verify , First, whether it's moving left or right , If we input the same target frame , Then you should get the same HR frame , If HR Same frame , Then the filter used for up sampling , It should be the same ! Then you can understand it normally , The following figure Filters The pattern of is the same , But for left and right movements , It's movement in different directions , According to the motion estimation of a set of input frames , The calculated compensation values are different , therefore activation map It should be different , Because the motion estimation information is different , So the author compares the left and right movements of the same block by making a composite graph , Get different activation diagrams , But the filter of the same target frame can still be obtained , So this experiment proves that this algorithm can be used without displaying motion compensation .

(5.1.2) Filter validity test
List the 3*3*3 filter , The convolution results are visually displayed , We can see Filters for different layers of learning , The information extracted at different times is different , And it can collect data evenly without large-scale shadow , The information extracted from different layers is different , It is proved that the filter is effective .

(5.1.3) Dynamic up sampling filter
As shown in the figure below , For different locations on the same calendar , We use different upsampling filters generated , You can see Filters The weights of the blocks in the graph are different , Generated Filters Is different , To divide different parts and sections , Can achieve accurate output . It is proved that our dynamic up sampling filter is useful .

(5.2) experimental result :
The algorithm of this paper with different magnification ratio is compared with the previous algorithm , Have better PSNR and SSIM value , The implementation details are also fine .



summary :
The whole idea of this article is not very difficult , Use the upsampling filter input directly HR Images , Use residuals to supplement details , There is no need to perform complex calculations such as additional display motion estimation , The algorithm has few parameters , Compared with the current algorithm , There are few parameters , But the running time is too slow , stay 1s about , And what I am repeating , Generate HR The speed of 2s about , There is no way to meet the real-time requirements , It may be used to preprocess some videos . There is no way to carry out industrial landing , Further optimization and acceleration are needed . But the algorithm is used as 18 Years of in-depth learning VSR for , It is also a paper worth reading and understanding .
边栏推荐
- 2021.10.27-28 scientific research log
- Numerical calculation method chapter5 Direct method for solving linear equations
- The latest hbuilderx editing uni app project runs in the night God simulator
- Dynamic simulation method of security class using Matlab based Matpower toolbox
- R language uses rstudio to save visualization results as PDF files (export--save as PDF)
- Vins technical route and code explanation
- The R language uses the sample The split function divides the machine learning data set into training set and test set
- [RedisTemplate方法详解]
- KAtex problem of vscade: parseerror: KAtex parse error: can't use function '$' in math mode at position
- 20220526 yolov1-v5
猜你喜欢
![[redistemplate method details]](/img/ef/66d8e3fe998d9a788170016495cb10.png)
[redistemplate method details]

Derivation of Poisson distribution

Talk about the four basic concepts of database system

Literature reading: raise a child in large language model: rewards effective and generalizable fine tuning

HDLC protocol

Transformation from AC5 to AC6 (1) - remedy and preparation
计组第一章
Windows10 configuration database

Vins technical route and code explanation

Topic 1 Single_Cell_analysis(4)
随机推荐
2.2 linked list - Design linked list (leetcode 707)
Group planning chapter I
Search and rescue strategy of underwater robot (FISH)
Leetcode notes: biweekly contest 79
N-order nonzero matrix AB, matrix ab=0, then the rank of a and B is less than n
Pytorch practice: predicting article reading based on pytorch
Process terminated
Symfony 2: multiple and dynamic database connections
20220524 backbone deep learning network framework
qt. qpa. plugin: Could not load the Qt platform plugin “xcb“ in “***“
20220607. face recognition
二、八、十、十六进制相互转换
从AC5到AC6转型之路(1)——补救和准备
2021.10.26 scientific research log
MinGW offline installation package (free, fool)
Literature reading: raise a child in large language model: rewards effective and generalizable fine tuning
802.11 protocol: wireless LAN protocol
Introduction to coco dataset
DUF:Deep Video Super-Resolution Network Using Dynamic Upsampling Filters ...阅读笔记
PPP agreement