当前位置:网站首页>Some important knowledge of MySQL
Some important knowledge of MySQL
2022-07-07 20:00:00 【Whiteye too white】
Engine difference
- InnoDB: Default storage engine , Support row lock and table lock 、 Business 、 Foreign keys 、 Crash recovery , Support mvcc Multi version control Read write concurrency . High update efficiency . The bottom is B+ Trees .
- MyISAM: Only table level locks are supported , Using nonclustered indexes . Table structure 、 data 、 Index three table separation . High query efficiency .
- Mrg_Myisam:MyIsam Table aggregation for , It has no data inside , The real data is still Mylsam In the engine list .
- Memory: Create tables in memory , Only data with constant data length can be stored , Data loss when the process crashes .
B+ Trees 、 Red and black trees
- InnoDB- Bottom B+ Trees :B+ A tree is a multi-channel balanced tree , The trees are smaller , Fast query speed , Query efficiency is stable , It is used to store fixed data such as indexes .
- Hashmap- The underlying array + Linked list / Array + Red and black trees : Red black trees are not completely balanced binary trees , Using color insertion to delete nodes can quickly achieve balance , Used to store data with many insert and delete operations .
What is a clustered index ( primary key ) And non clustered indexes ( Secondary indexes )?
- Clustered index means that indexes and data are stored together . for example :InnoDB The storage engine of must contain a primary key , If we don't specify the primary key , The default primary key will be generated , Primary keys and data are stored in B+ In the tree , This kind of index is called clustered index . If we use the primary key as the query condition , Will be directly in B+ Find specific data in the tree .
- Non clustered index means that the index and data are stored separately . for example :InnoDB The non primary key indexes of are stored separately in a B+ In the tree , But the leaf node stores the primary key value of the specific primary key index , So for non clustered indexes , You also need to query the primary key value to the cluster index to find a complete record , Therefore, according to the non clustered index retrieval, the secondary query is actually carried out , The efficiency is definitely not as high as that of searching by cluster index .
Cluster index 、 primary key :
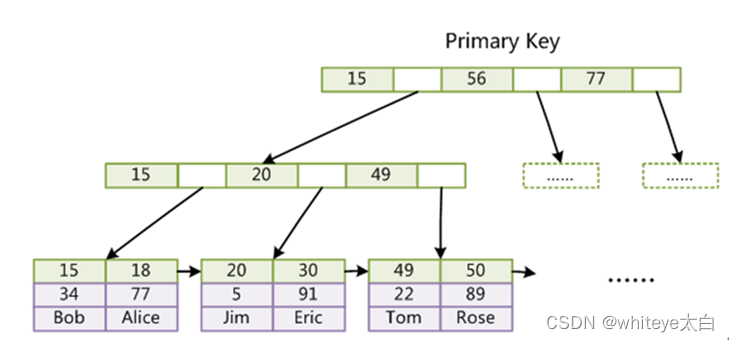
Cluster index 、 Secondary index 、 Secondary indexes :

join Internal connection
- left join …on… Connect to the left , Add the right table to the left table , Delete more , Fill in the missing NULL
- inner join …on… Internal connection , intersection
Index structure
B+ Trees : Non leaf node storage index , Leaf nodes store data , A two-way linked list is formed between leaf nodes .
Index usage scenarios
- Frequently queried Columns .where id=?
- Always sort , Grouped Columns . Because the index is in order
- Highly unique columns . For example, the primary key 、 user name
Overlay index
The index field covers the fields involved in the query statement , Directly through the index file, you can return the data required by the query , You don't have to go back to the table .
Back to the table
Find the primary key through the non primary key index id, According to the primary key id Go to the leaf node linked list query of the primary key index .
Index push down
During the non clustered index traversal , Judge the fields included in the index first , Filter out unqualified records , Reduce the number of times to return to the table .
Index failure ( Perform a full table scan when the index fails , Upgrade row lock to table lock )
- select *
、<、!=、between
- In front of % Of like Inquire about
- or Connect different fields
- where There is a type conversion between the field value and the database field
- Function or operation causes index invalidation
- IS NULL Don't walk index ,IS NOT NULL Go to the index ( Table design : When not necessary , The field should not be NULL, Set the default empty string or 0)
- IN Can walk the index , But when IN When the value range of is large, the index will be invalid
ep_range_index_dive_limit This parameter affects in Use index or not ,MySQL 5.6 Default 10,
MySQL 5.7 Default 200. But our code tends to be controlled in 50 Inside .
A Table data is greater than B Table data , choice in Than exists High execution efficiency .
contrary ,A Table data is less than B Table data , choice exists More efficient .
in Execute subquery first ,exists First perform the appearance . - not in Will invalidate the index , In either case not exists All ratio not in Efficient .
Use left join or not exists To optimize not in operation - Less table data will invalidate the index
The slow query
exceed long_query_time threshold ( Default 10s), It is considered as slow query . Manually start the slow query log , Slow queries will be recorded in the slow query log .
Settable items : threshold , Unused index sql, Where the logs are kept .
Log contents :
first line : Recorded time
The second line : user name 、 User IP Information 、 Threads ID Number
The third line : Execution time 、 Time to acquire the lock 、 Number of rows of results obtained 、 Number of data lines scanned
In the fourth row :SQL Timestamp of execution The fifth row : Concrete SQL sentence
Transaction isolation level
- Read uncommitted
- Read submitted
- Repeatable
- Serialization
MySQL The isolation level is based on locks and MVCC Mechanism together . InnoDB The default isolation level is repeatable .
The difference between nonrepeatable reading and unreal reading :
The key point of non repeatable reading is to modify. For example, read a record many times and find that the values of some columns have been modified , The focus of unreal reading is to add or delete, such as querying the same query statement multiple times (DQL) when , Records found that records increased or decreased .
- Shared lock : Also called read lock .
- Exclusive lock : Also known as write lock .
- Intent locks : Add sharing for data rows / Before he locks ,InooDB First, the corresponding intention lock of the data row in the data table will be obtained . To quickly determine whether a table lock can be used on a table .
InnoDB Three row locking methods
- Record locks : One way lock .
- Clearance lock : Range lock , The lock scope class prevents insertion 、 Delete .
- Temporary key lock : What locks is the index itself and the gap before the index , It's a left open right closed interval , Prevent insertion .
InnoDB Row lock implementation --(mysql How to turn row lock into table lock )
InnoDB Row locking is achieved by locking the index items on the index , Therefore, only the index query data ,( The index is not invalidated )innoDB To use row locks , otherwise InnoDB Table locks will be used .
because MySQL Of ⾏ A lock is a lock added to an index , It's not a lock on records , So although the visit is different ⾏ The record of , But if it is to make ⽤ Same index key , There will be lock conflicts .
undo log Crash recovery has two main functions :
- When the transaction is rolled back, it is used to restore the data to its original state .
- Another function is MVCC , When reading records , If the record is occupied by another transaction or the current version is not visible to the transaction , You can use the undo log Read previous version data , So as to realize non locking read .
MVCC
- Multi version concurrency control , Through the recorded version number , Realize read-write concurrency .
- InnoDB Save two additional hidden columns in each row of data , Save the created and expired system version numbers .
- Every time you start a new business , The system version number will be incremented automatically , The system version number at the beginning of the transaction is used as the version number of the transaction .
- InnoDB Transactions only query data rows with version number less than or equal to it , Ensure that the data row exists before the transaction starts , Or the transaction itself inserts or modifies .
边栏推荐
- UCloud是基础云计算服务提供商
- Kirin Xin'an won the bid for the new generation dispatching project of State Grid!
- R language ggplot2 visualization: use the ggdensity function of ggpubr package to visualize the packet density graph, and use stat_ overlay_ normal_ The density function superimposes the positive dist
- 爬虫实战(七):爬王者英雄图片
- mysql 的一些重要知识
- 注解。。。
- Download from MySQL official website: mysql8 for Linux X Version (Graphic explanation)
- Ucloud is a basic cloud computing service provider
- MSE API学习
- R language ggplot2 visualization: use the ggecdf function of ggpubr package to visualize the grouping experience cumulative density distribution function curve, and the linetype parameter to specify t
猜你喜欢
Introduction to bit operation

小试牛刀之NunJucks模板引擎
Navicat连接2002 - Can‘t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock‘解决
关于cv2.dnn.readNetFromONNX(path)就报ERROR during processing node with 3 inputs and 1 outputs的解决过程【独家发布】
PMP對工作有益嗎?怎麼選擇靠譜平臺讓備考更省心省力!!!
转置卷积理论解释(输入输出大小分析)
Automatic classification of defective photovoltaic module cells in electroluminescence images-論文閱讀筆記

openEuler 有奖捉虫活动,来参与一下?

Kirin Xin'an won the bid for the new generation dispatching project of State Grid!

Kirin Xin'an cloud platform is newly upgraded!
随机推荐
pom.xml 配置文件标签作用简述
what‘s the meaning of inference
Automatic classification of defective photovoltaic module cells in electroluminescence images-論文閱讀筆記
Notes...
CSDN语法说明
ASP.NET体育馆综合会员管理系统源码,免费分享
一张图深入的理解FP/FN/Precision/Recall
Semantic slam source code analysis
[RT thread env tool installation]
Kirin Xin'an won the bid for the new generation dispatching project of State Grid!
LeetCode_7_5
R language ggplot2 visualization: use the ggqqplot function of ggpubr package to visualize the QQ graph (Quantitative quantitative plot)
9 atomic operation class 18 Rohan enhancement
Nunjuks template engine
Ucloud is a basic cloud computing service provider
位运算介绍
841. 字符串哈希
Simulate the implementation of string class
LeetCode_ 7_ five
R language ggplot2 visualization: use the ggstripchart function of ggpubr package to visualize the dot strip plot, set the position parameter, and configure the separation degree of different grouped