当前位置:网站首页>Multi table associated query -- 07 -- hash join
Multi table associated query -- 07 -- hash join
2022-06-27 07:24:00 【High high for loop】
Tips : When the article is finished , Directories can be generated automatically , How to generate it, please refer to the help document on the right
List of articles
Hash join
1. brief introduction
website :Hash join in MySQL 8
mysql8.0 Start introducing Hash join

2. What is? hash join
- So-called hash join Definition : Use hash Table to match row data in multiple tables join Realization .
- Usually ,hash join Efficient than nested loop join fast ( When join There is a small amount of data in one of the tables , When it can be fully cached in memory ,hash join Efficiency is the best ).
3.Hash Join Treatment process
Let's use an example to illustrate .
SELECT
given_name, country_name
FROM
persons JOIN countries ON persons.country_id = countries.country_id;
- country Country table , As a basic element table , The amount of data is relatively small
- persons Personnel information sheet , The amount of data is relatively large
4.Hash join The process
HashJoin Generally, there are two processes ,hash Table building process and be based on hash Probe comparison section of the table .
- establish hash Tabular build The process
- Probe hash Tabular probe The process
5. How do you use it? hash join
- By default ,hash join Is open .
- Can be in explain Add “FORMAT = tree” View a sql
mysql> EXPLAIN FORMAT=tree
-> SELECT
-> given_name, country_name
-> FROM
-> persons JOIN countries ON persons.country_id = countries.country_id;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (countries.country_id = persons.country_id) (cost=0.70 rows=1)
-> Table scan on countries (cost=0.35 rows=1)
-> Hash
-> Table scan on persons (cost=0.35 rows=1)
|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
Usually , If join Used Equivalent conditions ( One or more )、 also , No, Index available , Will use hash join .( in other words , If there is an index , be mysql Will still give priority to All queries )
We can also use the command to close hash join :
mysql> SET optimizer_switch="hash_join=off";
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN FORMAT=tree
-> SELECT
-> given_name, country_name
-> FROM
-> persons JOIN countries ON persons.country_id = countries.country_id;
+----------------------------------------+
| EXPLAIN |
+----------------------------------------+
|
|
+----------------------------------------+
1 row in set (0.00 sec)
Hash join Principle analysis
1.hash Table building (build) The process
Select a table with a small amount of data To build hash surface
- In the build hash Table time ,mysql take join Data of a data table in The cache to this hash In the table . Usually , Select a table with a small amount of data To build hash surface ( The amount of data to be cached is relatively small ).
- hash Table use join The use of join This table in the uses the condition as hash key.
- For example, in the example above , country Table as a Basic element table , The amount of data is relatively small , Then select cache country Table data . in addition ,join Condition is persons.country_id = countries.country_id , Then use countries Tabular country_id Field value as hash key.
- When country All relevant data rows in the table are cached , The build process is over .

2.hash Table probe (probe) The process
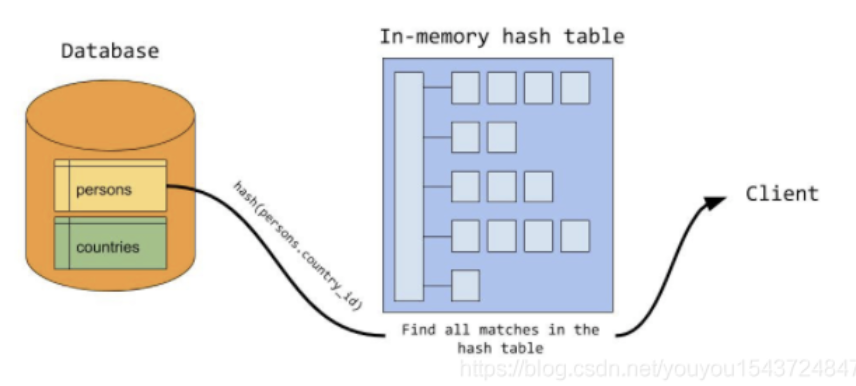
- In the detection phase , database Read the data row from the data table to be probed ( In this case is person surface ).
- For each row of data read , mysql Will use In a row country_id value Inquire about hash surface , Each row of data is matched , Find one reasonable join Results data .
- On the whole ,mysql Just for each table , Just one scan . For probe table scanning , Every time a piece of data is scanned , Then use a constant time based on hash Watch coming in Data results match .
3. Data table splitting
- When A data sheet ( As hash Table of source data ) When it can be cached in memory ,hash join Our efficiency is very fast .
- that hash join Available hash How big is the cache ?
- This is a adopt System Variable join_buffer_size The control of the . This variable can be modified at any time , Immediate effect .
- So if as join Amount of data in the data sheet It's big , Unable to complete caching , How to deal with that ?
- If you are building hash In the process of watch , If it reaches join_buffer_size value , be mysql Write the remaining data to a file block on disk .
- When writing file blocks ,mysql Will try to Control the size of each block , So that the subsequent block can be just loaded into join_buffer_size The size of hash In cache .( however mysql There is also a biggest limitation , For each join , Maximum 128 individual Disk data block ).
If you do join Amount of data in the data sheet It's big , Unable to complete caching , Data splitting is also required for small tables
- When the data is written to the disk file block , How do I know which line of data is written to that file block ? Here is a new hash function , Used to locate data blocks .
- Then why use a new hash Function? ? This reason will be followed by .

4. Split ----- Data detection phase
- In the data detection phase ,mysql The process of data matching and no writing The process of disk block file is the same ( It's like all the data is written to memory hash The table is the same ): In the probe table , Each row of data scanned , Just arrive In memory hash In the table matching , Find eligible data .
- But here's the difference , If the disk block is written , It's in Probe every row of data scanned in the table A , stay hash After the table is matched , You also need to write to the disk file block ( Because for data rows A , It is also possible to match Data previously written to the disk block ).
- Need to pay attention to when , Write the probe table to Disk file block , Locate the data row to Of a particular block of data hash function and take hash The algorithm for writing table source table data to data block is consistent . therefore Matching data Will be written to The same couple Data block .
for example ,country The table has a large amount of data , Can only be With A - D The first country is written in Memory hash In the table . in addition , take The rest of the country data Write to disk file block .
If the country HXX Write to hash Table block HA in . Scanning Person Table time , If a person's country is also HXX , The same is true , Will The calling data is written to Probe table HXX In the block number .

ad locum , There are two things that need to be explained :
- In the beginning, I wrote Disk file block , We need to pay attention to The size of each file block should not exceed join buffer size, all , One of them hash Disk file blocks can be loaded exactly into hash join In the table ;
- Why use different hash Algorithm to allocate different data rows to different Disk data block ? If the algorithm is the same , The data of a block is loaded into join hash In the table , Then a large amount of data will be in hash The same row of the table , A lot of conflicting data .
边栏推荐
- 小米面试官:听你说精通注册中心,我们来聊 3 天 3 夜
- R 中的 RNA-Seq 数据分析 - 调查数据中的差异表达基因!
- 通过uview让tabbar根据权限显示相应数量的tabbar
- 【LeetCode】Day90-二叉搜索树中第K小的元素
- 内存屏障今生之Store Buffer, Invalid Queue
- Interviewer: please introduce cache penetration, cache null value, cache avalanche and cache breakdown, which are easy to understand
- Apifox learning
- 面试官:你天天用 Lombok,说说它什么原理?我竟然答不上来…
- Installation and functions of uview
- 将通讯录功能设置为数据库维护,增加用户名和密码
猜你喜欢

Goodbye, agile Scrum
![[openairinterface5g] rrcsetupcomplete for RRC NR resolution](/img/61/2136dc37b98260e09f3be9979492b1.jpg)
[openairinterface5g] rrcsetupcomplete for RRC NR resolution

Oppo interview sorting, real eight part essay, abusing the interviewer

Xiaomi Interviewer: let's talk about the proficient Registration Center for three days and three nights
How to write controller layer code gracefully?

云服务器配置ftp、企业官网、数据库等方法

YOLOv6又快又准的目标检测框架 已开源

Centos7.9 install MySQL 5.7 and set startup
面试官:你天天用 Lombok,说说它什么原理?我竟然答不上来…

MySQL
随机推荐
解决 Win10 Wsl2 IP 变化问题
The song of cactus -- throwing stones to ask the way (1)
Xiaomi Interviewer: let's talk about the proficient Registration Center for three days and three nights
YOLOv6又快又准的目标检测框架 已开源
Vs how to configure opencv? 2022vs configuration opencv details (multiple pictures)
VNC Viewer方式的远程连接树莓派
OPPO面试整理,真正的八股文,狂虐面试官
从5秒优化到1秒,系统飞起来了...
Interviewer: please introduce cache penetration, cache null value, cache avalanche and cache breakdown, which are easy to understand
语音信号特征提取流程:输入语音信号-分帧、预加重、加窗、FFT->STFT谱(包括幅度、相位)-对复数取平方值->幅度谱-Mel滤波->梅尔谱-取对数->对数梅尔谱-DCT->FBank->MFCC
One person manages 1000 servers? This automatic operation and maintenance tool must be mastered
pytorch Default process group is not initialized
Self test in the second week of major 4
webscoket 数据库监听
guava 定时任务
Overview of database schema in tidb
请问网页按钮怎么绑定sql语句呀
Yolov6's fast and accurate target detection framework is open source
Classical cryptosystem -- substitution and replacement
postgreSQL在windows系统遇到权限否认(permission denied)