当前位置:网站首页>Nebula importer data import practice
Nebula importer data import practice
2022-07-05 01:14:00 【NebulaGraph】
This article was first published in Nebula Graph Community official account

Preface
Nebula At present, as a relatively mature product , There is already a rich ecosystem . In terms of the dimension of data import, there are many choices . It's big and complete Nebula Exchange, Small and streamlined Nebula Importer, And for Spark / Flink The engine provides Nebula Spark Connector and Nebula Flink Connector.
Among many import methods , Which is more convenient ?
Introduction to the use scenario :
- Nebula Exchange
- Need to bring from Kafka、Pulsar Streaming data of the platform , Import Nebula Graph database
- From relational database ( Such as MySQL) Or distributed file systems ( Such as HDFS) Read batch data in
- Large quantities of data need to be generated Nebula Graph Recognable SST file
- Nebula Importer
- Importer Applicable to local CSV Import the contents of the file into Nebula Graph in
- Nebula Spark Connector:
- In different Nebula Graph Migrate data between clusters
- In the same Nebula Graph Migrate data between different graph spaces in the cluster
- Nebula Graph Migrate data with other data sources
- combination Nebula Algorithm Do graph calculation
- Nebula Flink Connector
- In different Nebula Graph Migrate data between clusters
- In the same Nebula Graph Migrate data between different graph spaces in the cluster
- Nebula Graph Migrate data with other data sources
Above excerpts from Nebula Official documents :https://docs.nebula-graph.com.cn/2.6.2/1.introduction/1.what-is-nebula-graph/
On the whole ,Exchange Instead of , It can be combined with most storage engines , Import to Nebula in , But it needs to be deployed Spark Environmental Science .
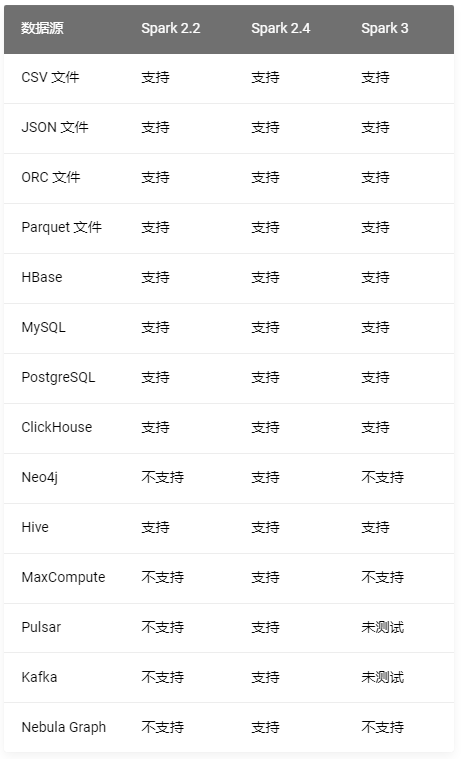
Importer Easy to use , Less dependency required , But you need to generate data files in advance , Good configuration schema Once and for all , But it does not support breakpoint continuation , Suitable for medium amount of data .
Spark / Flink Connector It needs to be combined with stream data .
Choose different tools for different scenarios , If used as a newcomer Nebula When importing data , It is recommended to use Nebula Importer Tools , It's easy and quick .
Nebula Importer Use
Before we touch Nebula Graph initial stage , At that time, the ecology was not perfect , In addition, only some businesses are migrated to Nebula Graph On , We are right. Nebula Graph Data import, whether full or incremental, adopts Hive Push table to Kafka, consumption Kafka Batch write Nebula Graph The way . Later, with more and more data and business switching to Nebula Graph, The efficiency of imported data is becoming more and more serious , Increase of import duration , So that the full amount of data is still imported at the peak of business , This is unacceptable .
For the above problems , Trying to Nebula Spark Connector and Nebula Importer after , Considering the convenience of maintenance and migration , use Hive table -> CSV -> Nebula Server -> Nebula Importer The way to import the full amount , The overall time consumption has also been greatly improved .
Nebula Importor Related configuration of
System environment
[[email protected] importer]# lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 16On-line CPU(s) list: 0-15Thread(s) per core: 2Core(s) per socket: 8Socket(s): 1NUMA node(s): 1Vendor ID: GenuineIntelCPU family: 6Model: 85Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHzStepping: 7CPU MHz: 2499.998BogoMIPS: 4999.99Hypervisor vendor: KVMVirtualization type: fullL1d cache: 32KL1i cache: 32KL2 cache: 1024KL3 cache: 36608KNUMA node0 CPU(s): 0-15Disk:SSDMemory: 128GCluster environment
- Nebula Version:v2.6.1
- Deployment way :RPM
- The cluster size : Three copies , Six nodes
Data scale
+---------+--------------------------+-----------+| "Space" | "vertices" | 559191827 |+---------+--------------------------+-----------+| "Space" | "edges" | 722490436 |+---------+--------------------------+-----------+Importer To configure
# Graph edition , Connect 2.x Is set to v2.version: v2description: Relation Space import data# Whether to delete the temporarily generated logs and error data files .removeTempFiles: falseclientSettings: # nGQL Number of retries for statement execution failure . retry: 3 # Nebula Graph Number of concurrent clients . concurrency: 5 # Every Nebula Graph The cache queue size of the client . channelBufferSize: 1024 # Specify the data to import Nebula Graph Graph space . space: Relation # Connection information . connection: user: root password: ****** address: 10.0.XXX.XXX:9669,10.0.XXX.XXX:9669 postStart: # configure connections Nebula Graph After the server , Some operations performed before inserting data . commands: | # The interval between the execution of the above command and the execution of the insert data command . afterPeriod: 1s preStop: # Configure disconnect Nebula Graph Some operations performed before connecting to the server . commands: |# Error and other log information output file path . logPath: /mnt/csv_file/prod_relation/err/test.log....Due to space Only show some globally relevant configurations , There are many configurations related to points and edges , Don't expand , For details, please refer to GitHub.
Set up Crontab,Hive After the table is generated, it is transferred to Nebula Server, Run when the traffic is low at night Nebula Importer Mission :
50 03 15 * * /mnt/csv_file/importer/nebula-importer -config /mnt/csv_file/importer/rel.yaml >> /root/rel.logThe total time is 2h, Complete the import of full data around 6 o'clock .
part log as follows , The maximum import speed is maintained at 200,000/s about :
2022/05/15 03:50:11 [INFO] statsmgr.go:62: Tick: Time(10.00s), Finished(1952500), Failed(0), Read Failed(0), Latency AVG(4232us), Batches Req AVG(4582us), Rows AVG(195248.59/s)2022/05/15 03:50:16 [INFO] statsmgr.go:62: Tick: Time(15.00s), Finished(2925600), Failed(0), Read Failed(0), Latency AVG(4421us), Batches Req AVG(4761us), Rows AVG(195039.12/s)2022/05/15 03:50:21 [INFO] statsmgr.go:62: Tick: Time(20.00s), Finished(3927400), Failed(0), Read Failed(0), Latency AVG(4486us), Batches Req AVG(4818us), Rows AVG(196367.10/s)2022/05/15 03:50:26 [INFO] statsmgr.go:62: Tick: Time(25.00s), Finished(5140500), Failed(0), Read Failed(0), Latency AVG(4327us), Batches Req AVG(4653us), Rows AVG(205619.44/s)2022/05/15 03:50:31 [INFO] statsmgr.go:62: Tick: Time(30.00s), Finished(6080800), Failed(0), Read Failed(0), Latency AVG(4431us), Batches Req AVG(4755us), Rows AVG(202693.39/s)2022/05/15 03:50:36 [INFO] statsmgr.go:62: Tick: Time(35.00s), Finished(7087200), Failed(0), Read Failed(0), Latency AVG(4461us), Batches Req AVG(4784us), Rows AVG(202489.00/s)Then at seven , According to time stamp , Consume again Kafka Import incremental data from the morning to seven o'clock of the day , prevent T+1 The full amount of data covers the incremental data of the day .
50 07 15 * * python3 /mnt/code/consumer_by_time/relation_consumer_by_timestamp.pyIncremental consumption may take time 10-15min.
The real time
according to MD5 The incremental data obtained after comparison , Import Kafka in , Real time consumption Kafka The data of , Ensure that the data delay does not exceed 1 minute .
In addition, unexpected data problems may occur and not be found in real-time for a long time , So every 30 Full data will be imported once a day , It's described above Importer Import . And then to Space Point and edge add TTL=35 Ensure that the data that is not updated in time will be Filter And subsequent recycling .
Some notes
Forum post https://discuss.nebula-graph.com.cn/t/topic/361 Here is a reference to CSV Common problems in importing , You can refer to it . In addition, based on experience, here are some suggestions :
- About concurrency , It is mentioned in the question that , This concurrency Designated as your cpu cores Can , Indicates how many client Connect Nebula Server. In practice , Want to go trade off The impact of import speed and server pressure . Test on our side , If concurrency is too high , Will cause disk IO Too high , Trigger some set alarms , It is not recommended to increase concurrency , You can make a trade-off according to the actual business test .
- Importer It can't be continued at breakpoints , If something goes wrong , Need to be handled manually . In practice , We will analyze the program Importer Of log, Handle according to the situation , If any part of the data has unexpected errors , Alarm notification , Artificial intervention , Prevent accidents .
- Hive After the table is generated, it is transferred to Nebula Server, This part of the task The actual time consumption is and Hadoop Resources are closely related , There may be insufficient resources leading to Hive and CSV Table generation time is slow , and Importer Normal running , This part needs to be predicted in advance . Our side is based on hive Task end time and Importer Compare the task start time , To determine whether or not Importer The process of is running normally .
Communication graph database technology ? Join in Nebula Communication group please first Fill in your Nebula Business card ,Nebula The little assistant will pull you into the group ~~
边栏推荐
- Pandora IOT development board learning (RT thread) - Experiment 4 buzzer + motor experiment [key external interrupt] (learning notes)
- 【大型电商项目开发】性能压测-优化-中间件对性能的影响-40
- Basic operation of database and table ----- the concept of index
- There is a new Post-00 exam king in the testing department. I really can't do it in my old age. I have
- [wave modeling 2] three dimensional wave modeling and wave generator modeling matlab simulation
- Global and Chinese market of nutrient analyzer 2022-2028: Research Report on technology, participants, trends, market size and share
- “薪资倒挂”、“毕业生平替” 这些现象说明测试行业已经...
- node工程中package.json文件作用是什么?里面的^尖括号和~波浪号是什么意思?
- Take you ten days to easily complete the go micro service series (IX. link tracking)
- 各大主流编程语言性能PK,结果出乎意料
猜你喜欢

小程序直播 + 电商,想做新零售电商就用它吧!
7. Scala process control

Basic operations of database and table ----- delete index
Applet live + e-commerce, if you want to be a new retail e-commerce, use it!
![[wave modeling 2] three dimensional wave modeling and wave generator modeling matlab simulation](/img/50/b6cecc95e46fe1e445eb00ca415669.png)
[wave modeling 2] three dimensional wave modeling and wave generator modeling matlab simulation
How to use words to describe breaking change in Spartacus UI of SAP e-commerce cloud
![Grabbing and sorting out external articles -- status bar [4]](/img/88/8267ab92177788ac17ab665a90b781.png)
Grabbing and sorting out external articles -- status bar [4]
Take you ten days to easily complete the go micro service series (IX. link tracking)
【海浪建模3】三维随机真实海浪建模以及海浪发电机建模matlab仿真
![[untitled]](/img/d1/85550f58ce47e3609abe838b58c79e.jpg)
[untitled]
随机推荐
BGP comprehensive experiment
Redis master-slave replication cluster and recovery ideas for abnormal data loss # yyds dry goods inventory #
The most complete regular practical guide of the whole network. You're welcome to take it away
RB technology stack
107. Some details of SAP ui5 overflow toolbar container control and resize event processing
Global and Chinese markets for stratospheric UAV payloads 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese market of portable CNC cutting machines 2022-2028: Research Report on technology, participants, trends, market size and share
[pure tone hearing test] pure tone hearing test system based on MATLAB
[development of large e-commerce projects] performance pressure test - Performance Monitoring - heap memory and garbage collection -39
创新引领方向 华为智慧生活全场景新品齐发
When the industrial Internet era is truly developed and improved, it will witness the birth of giants in every scene
Query for Boolean field as "not true" (e.g. either false or non-existent)
各大主流编程语言性能PK,结果出乎意料
User login function: simple but difficult
Senior Test / development programmers write no bugs? Qualifications (shackles) don't be afraid of mistakes
微信小程序:全新独立后台月老办事处一元交友盲盒
Expose testing outsourcing companies. You may have heard such a voice about outsourcing
【海浪建模1】海浪建模的理论分析和matlab仿真
To sort out messy header files, I use include what you use
The server time zone value ‘� й ��� ʱ 'is unrecognized or representatives more than one time zone【