当前位置:网站首页>Simple dialogue system -- text classification using transformer
Simple dialogue system -- text classification using transformer
2022-07-04 03:37:00 【Angry coke】
introduction
We will show how to use Transformer Model in the library to solve the task of text classification , Task from GLUE Benchmark.
| Mission | sketch | type | single / Double sentence input | label | Evaluation indicators |
|---|---|---|---|---|---|
| CoLA | Whether the input sentence is grammatically acceptable | classification | Single sentence | {0:no,1:yes} | Matthews The correlation coefficient |
| SST-2 | Two categories of film comment emotion | classification | Single sentence | {0:negative,1:positive} | Accuracy rate |
| MRPC | Whether the input sentence pairs are semantically equivalent | classification | Double sentence | {0:no,1:yes} | Accuracy rate /F1 |
| STS-B | Judge the similarity of input sentence pairs 1 to 5 files | Return to | Double sentence | [1.0,5.0] | Pearson/Spearman The correlation coefficient |
| QQP | Whether two Quora The question of whether semantic equivalence | classification | Double sentence | {0:not similary,1:similar} | Accuracy rate /F1 |
| MNLI | Judge whether the latter sentence contains the former sentence , Three kinds of labels contain 、 Neutral or opposite | classification | Double sentence | {0:entailend,1:neutral,2:contradiction} | Accuracy rate |
| QNLI | from SQuAD The question and answer sentences extracted from reading comprehension are right , Judge whether the latter sentence can answer the question of the former sentence | classification | Double sentence | {0:entailend,1:not entailend} | Accuracy rate |
| RTE | Judge whether the input sentence contains the previous sentence | classification | Double sentence | {0:entailend,1:not entailend} | Accuracy rate |
| WNLI | Input the sentence pair to judge whether the anaphora resolution of the pronoun in the following sentence is correct | classification | Double sentence | {0:no,1:yes} | Accuracy rate |
For the above tasks , We will show how to use simple Dataset Library load dataset , Use at the same time transformer Medium Trainer Interface to fine tune the pre training model .
Data loading
from datasets import load_dataset, load_metric
task = 'cola'
model_checkpoint = 'distilbert-base-uncased'
batch_size = 16
except mnli-mm outside , Other tasks can be loaded by task name .
actual_task = 'mnli' if task == 'mnli-mm' else task
dataset = load_dataset('glue', actual_task) # Load data set
metric = load_metric('glue', actual_task) # Load the evaluation indicators related to the dataset
dataset
DatasetDict({
train: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 8551
})
validation: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 1043
})
test: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 1063
})
})
dataset['train'][0]
{
'idx': 0,
'label': 1,
'sentence': "Our friends won't buy this analysis, let alone the next one we propose."}
Data preprocessing
We need to preprocess the data , The preprocessing tool is called Tokenizer. First, the input is tokenize obtain tokens, Then it is transformed into the corresponding token ID, Then convert it to the input format required by the model .
In order to achieve the purpose of data preprocessing , We use AutoTokenizer.from_pretrained Way to instantiate our tokenizer, This ensures that :
- We get a one-to-one correspondence with the pre training model tokenizer.
- Use the specified model checkpoint Corresponding tokenizer When , We also downloaded the thesaurus required by the model vocabulary, Exactly tokens vocabulary.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True) # use_fast Use multithreading fast tokenizer, Some models may not
tokenizer You can preprocess a single text , You can also preprocess a pair of text .
tokenizer('Hello,this one sentence!', 'And this sentence goes with it.')
{
'input_ids': [101, 7592, 1010, 2023, 2028, 6251, 999, 102, 1998, 2023, 6251, 3632, 2007, 2009, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
To preprocess our data , We need to know different data and corresponding data formats , So we define the following dict:
task_to_keys = {
'cola':('sentence', None),
'mnli':('premise', 'hypothesis'),
'mnli-mm':('premise', 'hypothesis'),
'mrpc':('sentence1', 'sentence2'),
'qnli':('question', 'sentence'),
'qqp':('question1', 'question2'),
'rte':('sentence1', 'sentence2'),
'sst2':('sentence', None),
'stsb':('sentence1', 'sentence2'),
'wnli':('sentence1', 'sentence2')
}
Put the pre trained code into a function :
sentence1_key,sentence2_key = task_to_keys[task]
def preprocess(examples):
# If the input is two sentences , All of them tokenize, Otherwise, only the first sentence .
if sentence2_key is None:
return tokenizer(examples[sentence1_key], truncation=True)
return tokenizer(examples[sentence1_key], examples[sentence2_key], truncation=True)
We can test it :
preprocess(dataset['train'][:5])
{
'input_ids': [[101, 2256, 2814, 2180, 1005, 1056, 4965, 2023, 4106, 1010, 2292, 2894, 1996, 2279, 2028, 2057, 16599, 1012, 102], [101, 2028, 2062, 18404, 2236, 3989, 1998, 1045, 1005, 1049, 3228, 2039, 1012, 102], [101, 2028, 2062, 18404, 2236, 3989, 2030, 1045, 1005, 1049, 3228, 2039, 1012, 102], [101, 1996, 2062, 2057, 2817, 16025, 1010, 1996, 13675, 16103, 2121, 2027, 2131, 1012, 102], [101, 2154, 2011, 2154, 1996, 8866, 2024, 2893, 14163, 8024, 3771, 1012, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
Next, preprocess all samples in the data set , The way to deal with it is to use map function , The preprocessing function prepare_train_features Apply to all samples .
encoded_dataset = dataset.map(preprocess, batched=True)
The returned results are cached , There is no need to recalculate next time . If you don't need to load the cache , Use load_from_cache_file=False Parameters .
Fine tune the pre training model
Since we are doing seq2seq Mission , Then you need a model class that can solve the task . We use AutoModelForSequenceClassification This class , and tokenizer be similar ,from_pretrained Methods can also help us download and load models :
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
# STS-B It's a regression problem ,MNLI It's a 3 Classification problem
num_labels = 3 if task.startswith('mnli') else 1 if task =='stsb' else 2
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
In order to get one Trainer Training tools , We also need 3 Elements , One of the most important is the setting of training / Parameters TrainingArguments. This training setting contains all the attributes that can define the training process .
metric_name ='pearson' if task=='stsb' else 'matthews_correlation' if task =='cola' else 'accuracy'
args = TrainingArguments(
'test-glue',
evaluation_strategy='epoch',
save_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=5,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model=metric_name,
)
evaluation_strategy='epoch' Every one epoch Will do a verification evaluation .
Because different tasks require different evaluation indicators , We define a function to get the evaluation method according to the task name :
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
if task != 'stsb':
predictions = np.argmax(predictions, axis=1)
else:
predictions = predictions[:,0]
return metric.compute(predictions=predictions, references=labels)
Then pass it all to Trainer:
validation_key = 'validation_mismatched' if task =='mnli-mm' else 'validation_matched' if task == 'mnli' else 'validation'
trainer = Trainer(
model,
args,
train_dataset=encoded_dataset['train'],
eval_dataset=encoded_dataset[validation_key],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
Start training :
trainer.train()
The following columns in the training set don't have a corresponding argument in `DistilBertForSequenceClassification.forward` and have been ignored: idx, sentence. If idx, sentence are not expected by `DistilBertForSequenceClassification.forward`, you can safely ignore this message.
/usr/local/lib/python3.7/dist-packages/transformers/optimization.py:310: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
FutureWarning,
***** Running training *****
Num examples = 8551
Num Epochs = 5
Instantaneous batch size per device = 16
Total train batch size (w. parallel, distributed & accumulation) = 16
Gradient Accumulation steps = 1
Total optimization steps = 2675
[2675/2675 03:05, Epoch 5/5]
Epoch Training Loss Validation Loss Matthews Correlation
1 0.524700 0.531839 0.397460
2 0.347900 0.517831 0.488779
3 0.235900 0.568724 0.520212
4 0.183700 0.776045 0.500206
5 0.138100 0.811927 0.521112
After the training, you can evaluate :
trainer.evaluate()
{
'epoch': 5.0,
'eval_loss': 0.8119268417358398,
'eval_matthews_correlation': 0.5211120728046958,
'eval_runtime': 0.8952,
'eval_samples_per_second': 1165.111,
'eval_steps_per_second': 73.727}
Super parameter search
If you don't know how to set parameters , We can search by super parameters .Trainer Support super parameter search , But you need to use optuna or Ray Tune The code base .
!pip install optuna ray[tune]
When searching for super parameters ,Trainer Multiple trained models will be returned , So you need to pass in a defined model to make Trainer You can constantly reinitialize the incoming model :
def model_init():
return AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
And the previous call Trainer similar :
trainer = Trainer(
model_init=model_init,
args=args,
train_dataset=encoded_dataset['train'],
eval_dataset=encoded_dataset[validation_key],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
Calling method hyperparameter_seach, But this process will take a long time . We can use part of the data to search for super parameters , Then do full training .
For example, use 1/10 Search for data :
best_run=trainer.hyperparameter_search(n_trials=10,direction='maximize')
It will return the best model related parameters :
best_run
BestRun(run_id='2', objective=0.5408374954915984, hyperparameters={
'learning_rate': 1.8520571467952223e-05, 'num_train_epochs': 4, 'seed': 37, 'per_device_train_batch_size': 8})
If you want to Trainer Set as the best parameter obtained by search , Training , It can be like this :
for n,v in best_run.hyperparameters.items():
setattr(trainer.args,n,v)
trainer.train()
Reference resources
- Greedy college courses
边栏推荐
- How to use websocket to realize simple chat function in C #
- [PaddleSeg 源码阅读] PaddleSeg 自定义数据类
- 基於.NetCore開發博客項目 StarBlog - (14) 實現主題切換功能
- How to use STR function of C language
- JSON string conversion in unity
- 渗透实战-SQLServer提权
- Aperçu du code source futur - série juc
- Rhcsa day 3
- What kind of experience is it when the Institute earns 20000 yuan a month!
- Formulaire day05
猜你喜欢
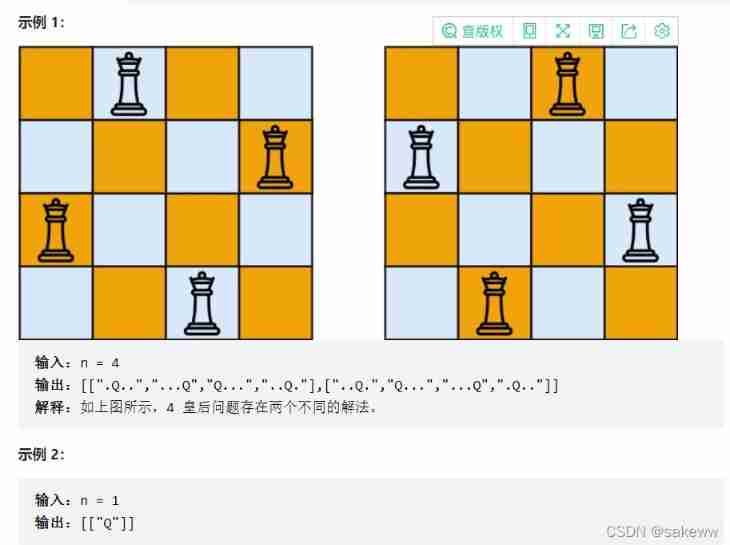
Leetcode51.n queen

(column 23) typical C language problem: find the minimum common multiple and maximum common divisor of two numbers. (two solutions)

What kind of experience is it when the Institute earns 20000 yuan a month!
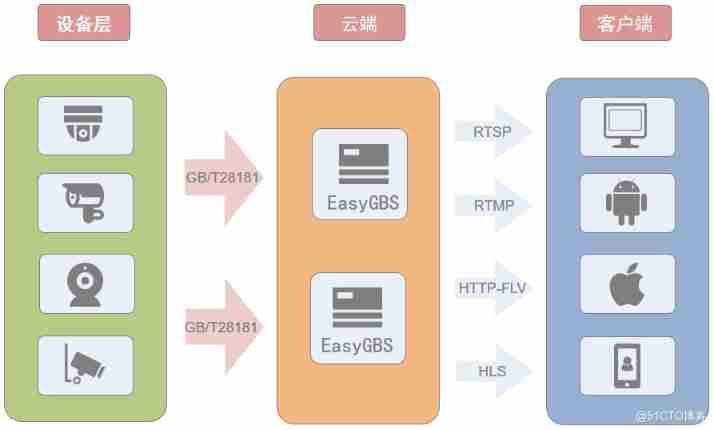
National standard gb28181 protocol platform easygbs fails to start after replacing MySQL database. How to deal with it?
Objective-C description method and type method

MySQL data query optimization -- data structure of index

Development of digital collection trading platform development of digital collection platform

SQL injection (1) -- determine whether there are SQL injection vulnerabilities

Don't disagree, this is the most powerful "language" of the Internet
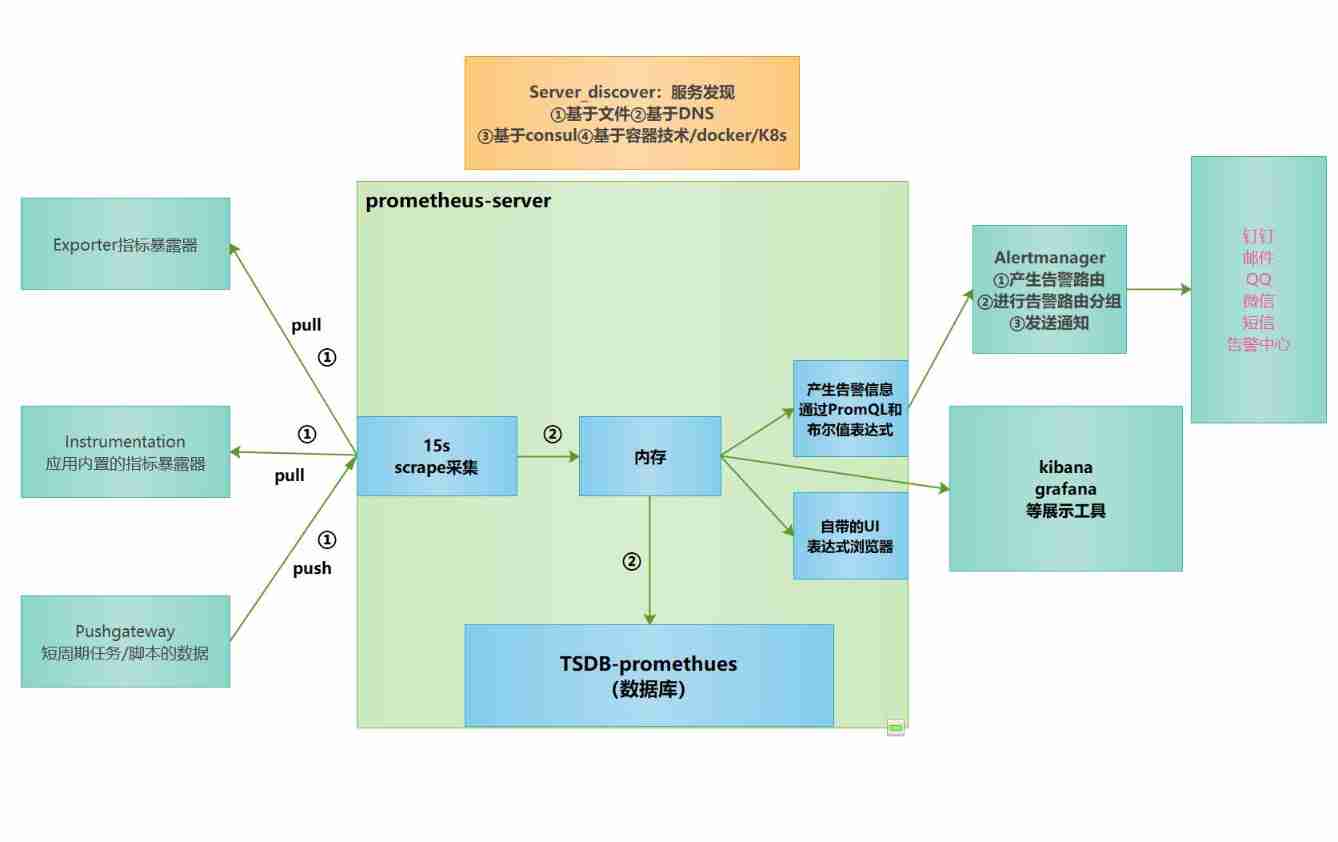
Monitoring - Prometheus introduction
随机推荐
In my spare time, I like to write some technical blogs and read some useless books. If you want to read more of my original articles, you can follow my personal wechat official account up technology c
(practice C language every day) pointer sorting problem
Easy to win insert sort
JVM family -- heap analysis
[UE4] parse JSON string
Setting methods, usage methods and common usage scenarios of environment variables in postman
Experience summary of the 12th Blue Bridge Cup (written for the first time)
Examination question bank of constructor decoration direction post skills (constructor) and examination data of constructor decoration direction post skills (constructor) in 2022
微信公众号网页授权
Objective-C member variable permissions
static hostname; transient hostname; pretty hostname
Tsinghua University product: penalty gradient norm improves generalization of deep learning model
Explain AI accelerator in detail: why is this the golden age of AI accelerator?
深入浅出对话系统——使用Transformer进行文本分类
SQL statement strengthening exercise (MySQL 8.0 as an example)
Package and download 10 sets of Apple CMS templates / download the source code of Apple CMS video and film website
Leetcode51.n queen
@Scheduled scheduled tasks
Audio and video technology development weekly | 232
[.NET + mqtt]. Mise en œuvre de la communication mqtt dans l'environnement net 6 et démonstration de code pour l'abonnement et la publication de messages bilatéraux du serveur et du client