当前位置:网站首页>【快手面试】Word2vect生成的向量,为什么可以计算相似度,相似度有什么意义?
【快手面试】Word2vect生成的向量,为什么可以计算相似度,相似度有什么意义?
2022-08-03 08:51:00 【凝眸伏笔】
背景:
我是推荐算法方向的面试,在面试的时候,使用word2vector的方法生成item的向量,来计算行为序列中的item跟待预估的item的相似度,来作为一维特征。
二面面试官问题:
Word2vect生成的向量,为什么可以计算相似度,相似度有什么意义?
答案分析:
term在相同的前后文中,认为两个term是等价的,它们学到的向量也更接近,所以item的向量计算相似度,表示两个向量的相似程度,也即是是否等价。
原理分析:
什么词算相似,一般可以认为,如果两个词的上下文越相似,这两个词也就越相似。比如牛在吃草,马在吃草,牛和马后面的词都一样。又或者是我家在北京,我家在上海,北京和上海的功能差不多,这两个词也就越相似,个人认为这也就是word2vec的出发点。
word2vec得出的词向量其实就是训练后的一个神经网络的隐层的权重矩阵,在经过CBOW或者Skip-Gram模型的训练之后,词义相近的词语就会获得更为接近的权重,因此可以用向量的距离来衡量词的相似度。
向量相似性,一般地,我们以向量的夹角来评价两个向量的相似性
这样我们就可以发现,如果有两向量u,v,
当u加上s*v时(s是正标量),u和v的夹角变小,因此更相似,
当u减去s*v时(s是正标量),u跟v的夹角变大,因此相似性减弱
边栏推荐
猜你喜欢
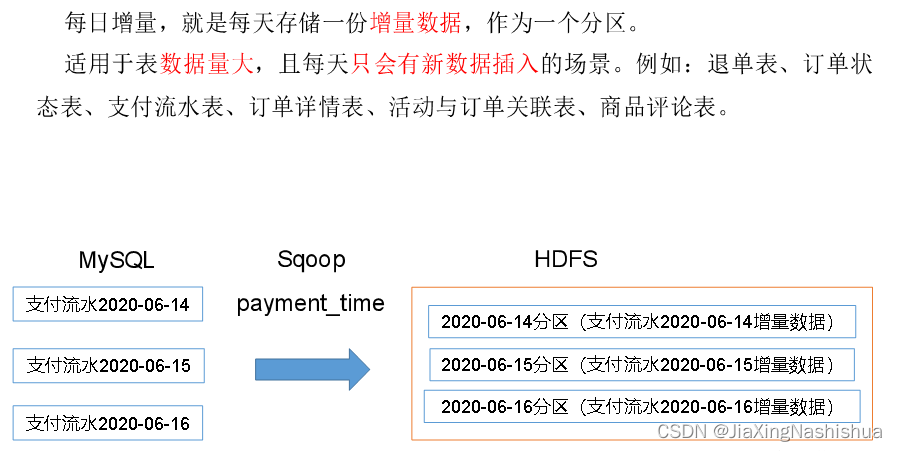
数仓4.0(二)------ 业务数据采集平台
AI mid-stage sequence labeling task: three data set construction process records
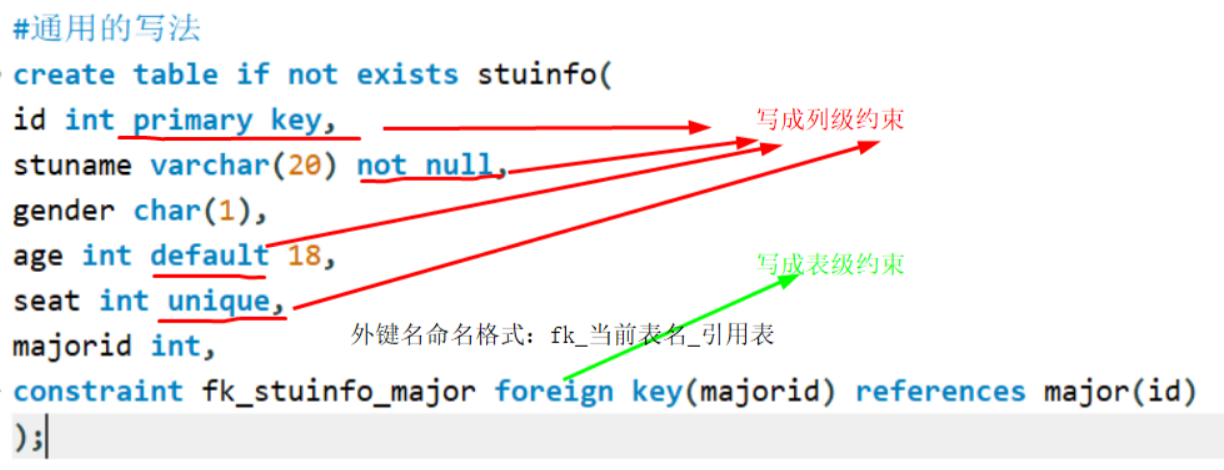
MySQL-DDL数据定义语言-约束
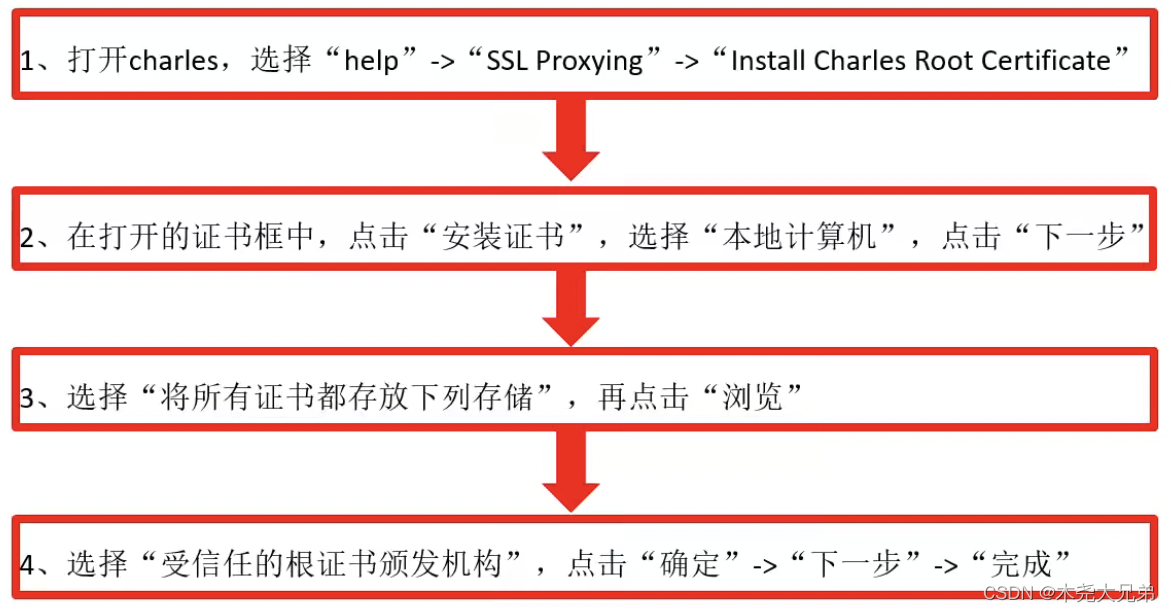
Charles packet capture tool learning record

flutter 应用 抓包
Network LSTM both short-term and long-term memory
手把手教你如何自制目标检测框架(从理论到实现)
【网络安全】Kail操作系统
HCIP练习02(OSPF)
Industry SaaS Microservice Stability Guarantee Actual Combat
随机推荐
Evaluate: A detailed introduction to the introduction of huggingface evaluation indicator module
【微信小程序】底部有安全距离,适配iphone X等机型的解决方案
ArcEngine (5) use the ICommand interface to achieve zoom in and zoom out
What are pseudo-classes and pseudo-elements?The difference between pseudo-classes and pseudo-elements
swiper分类菜单双层效果demo(整理)
WPS EXCEL 筛选指定长度的文本 内容 字符串
计算机网络之网络安全
响应式布局经典范例——巨幅背景大标题
Laya中关于摄像机跟随人物移动或者点击人物碰撞器触发事件的Demo
PowerShell:执行 Install-Module 时,不能从 URI 下载
pytorch one-hot 小技巧
进程信息
ArcEngine (2) loading the map document
window的供选数据流
AD环境搭建
110道 MySQL面试题及答案 (持续更新)
NFT到底有哪些实际用途?
frp: open source intranet penetration tool
Redis集群概念与搭建
手把手教你如何自制目标检测框架(从理论到实现)