当前位置:网站首页>2022cuda summer training camp Day5 practice
2022cuda summer training camp Day5 practice
2022-07-29 10:27:00 【Hua Weiyun】

2022CUDA Summer training camp Day1 practice https://bbs.huaweicloud.com/blogs/364478
2022CUDA Summer training camp Day2 practice https://bbs.huaweicloud.com/blogs/364479
2022CUDA Summer training camp Day3 practice https://bbs.huaweicloud.com/blogs/364480
2022CUDA Summer training camp Day4 Unified memory of practice https://bbs.huaweicloud.com/blogs/364481
2022CUDA Summer training camp Day4 Atomic operation of practice https://bbs.huaweicloud.com/blogs/364482
Day4 The homework after class is as follows :

The first question is , Above Day4 In the link , Zhang Xiaobai has done .
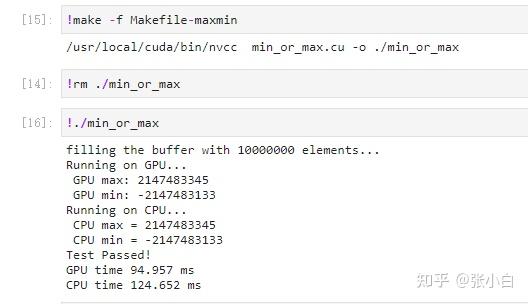
So how to do the second question ?
The teacher provided a function for top k Sort fields :
__device__ __host__ void insert_value(int* array, int k, int data){ for (int i = 0; i < k; i++) { if (array[i] == data) { return; } } if (data < array[k - 1]) return; for (int i = k - 2; i >= 0; i--) { if (data > array[i]) array[i + 1] = array[i]; else { array[i + 1] = data; return; } } array[0] = data;}We solve it top10 What's the idea of ?
Of course, it is still the continuation of this universal framework .
Let's look at the framework for finding the maximum and minimum values , Only the maximum part is left :
2_1.cu
#include<stdio.h>#include<stdint.h>#include<time.h> //for time()#include<stdlib.h> //for srand()/rand()#include<sys/time.h> //for gettimeofday()/struct timeval#include"error.cuh"#define N 10000000#define BLOCK_SIZE 256#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) __managed__ int source[N]; //input data__managed__ int final_result[2] = {INT_MIN,INT_MAX}; //scalar output__global__ void _sum_min_or_max(int *input, int count,int *output){ __shared__ int max_per_block[BLOCK_SIZE]; int max_temp = INT_MIN; for (int idx = threadIdx.x + blockDim.x * blockIdx.x; idx < count; idx += gridDim.x * blockDim.x ) { max_temp = (input[idx] > max_temp) ? input[idx] :max_temp; } max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp! __syncthreads(); //**********shared memory summation stage*********** for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2) { int max_double_kill = -1; if (threadIdx.x < length) { max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length]; } __syncthreads(); //why we need two __syncthreads() here, and, if (threadIdx.x < length) { max_per_block[threadIdx.x] = max_double_kill; } __syncthreads(); //....here ? } //the per-block partial sum is sum_per_block[0] if (blockDim.x * blockIdx.x < count) //in case that our users are naughty { //the final reduction performed by atomicAdd() if (threadIdx.x == 0) atomicMax(&output[0], max_per_block[0]); }}int _max_min_cpu(int *ptr, int count, int *max1, int *min1){ int max = INT_MIN; for (int i = 0; i < count; i++) { max = (ptr[i] > max)? ptr[i]:max; } //printf(" CPU max = %d\n", max); *max1 = max; return 0;}void _init(int *ptr, int count){ uint32_t seed = (uint32_t)time(NULL); //make huan happy srand(seed); //reseeding the random generator //filling the buffer with random data for (int i = 0; i < count; i++) { //ptr[i] = rand() % 100000000; ptr[i] = rand() ; if (i % 2 == 0) ptr[i] = 0 - ptr[i] ; } }double get_time(){ struct timeval tv; gettimeofday(&tv, NULL); return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);}int main(){ //********************************** fprintf(stderr, "filling the buffer with %d elements...\n", N); _init(source, N); //********************************** //Now we are going to kick start your kernel. cudaDeviceSynchronize(); //steady! ready! go! fprintf(stderr, "Running on GPU...\n"); double t0 = get_time(); _sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N,final_result); CHECK(cudaGetLastError()); //checking for launch failures CHECK(cudaDeviceSynchronize()); //checking for run-time failures double t1 = get_time(); fprintf(stderr, " GPU max: %d\n", final_result[0]); //********************************** //Now we are going to exercise your CPU... fprintf(stderr, "Running on CPU...\n");double t2 = get_time(); int cpu_max=0; int cpu_min=0; int B = _max_min_cpu(source, N, &cpu_max, &cpu_min); printf(" CPU max = %d\n", cpu_max); printf(" CPU min = %d\n", cpu_min); double t3 = get_time(); //fprintf(stderr, "CPU sum: %u\n", B); //******The last judgement********** //if ( final_result_max == cpu_max && final_result_min == cpu_min ) if ( final_result[0] == cpu_max ) { fprintf(stderr, "Test Passed!\n"); } else { fprintf(stderr, "Test failed!\n"); exit(-1); } //****and some timing details******* fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0); fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0); return 0;} Compile operation :
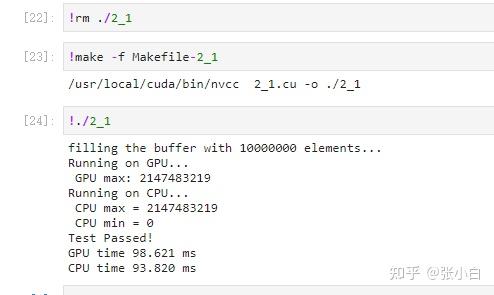
that , We continue to build on this framework , Calculate top 10 Add the part of .
How to add it ?
apparent , You need to calculate the above max Replace all the parts of with calculations top10 Part of :
We see the above two definitions :
__shared__ int max_per_block[BLOCK_SIZE];int max_temp =0;
max_per_block It is the storage maximum , Now store topk(k=10) A maximum of , So obviously we need to max_per_block[BLOCK_SIZE] Expand to max_per_block[BLOCK_SIZE* topk],
For comparison , take max_per_block Change it to topk_per_block:
Empathy , take max_temp Expand to topk_temp[topk];
The first 2 A place to : according to inut[idx] To calculate the topk_temp:
max_temp = (input[idx] > max_temp) ? input[idx] :max_temp;Directly change to
insert_value(topk_temp, TOPK, input[idx]);The first 3 A place to : according to topk_temp To calculate the topk_per_block[ threadIdx.x * TOPK ] To topk_per_block[ threadIdx.x * TOPK+TOPK-1 ] :
max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp!Change it to :
for(int i = 0; i< TOPK ; i++){ topk_per_block[ threadIdx.x * TOPK + i] = topk_temp[i];}The first 4 A place to :
max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length];It used to be taking max_per_block[threadIdx.x] and max_per_block[threadIdx.x + length]) Maximum value between , Same for insert_value function :
for(int i=0;i<TOPK ;i++){ insert_value(topk_temp, TOPK , topk_per_block[ (threadIdx.x + length) * TOPK + i]);}The first 5 A place to :
max_per_block[threadIdx.x] = max_double_kill;Change it to :
for(int i=0;i<TOPK ;i++){ topk_per_block[threadIdx.x *TOPK + i]= topk_temp[i];}The first 6 A place to :
if (threadIdx.x == 0) atomicMax(&output[0], max_per_block[0]);Change it to :
for(int i=0;i<TOPK ;i++) { output[TOPK * blockIdx.x +i ] = topk_per_block[i]; }notes : Here it can be more simply changed to :
if (threadIdx.x < TOPK) output[TOPK * blockIdx.x + threadIdx.x ] = topk_per_block[threadIdx.x];In this way, you can write directly in parallel , And it was merged .
After the kernel function is changed , The following changes are also made where kernel functions are called :
_sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N,final_result);Change it to
_sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N, _1pass_results);_sum_min_or_max<<<1, BLOCK_SIZE>>>(_1pass_results, TOPK * BLOCKS, final_result);There's a little bit of explanation here , Why is it OK to call the kernel function once when the maximum value is taken , But take TOPK You need to call 2 And then ?
Because none of them are processed at the same time TOPK Atomic operation of element replacement ( But there are many replacements 1 Atomic operation of elements )
Of course , Compare CPU and GPU The corresponding changes have also been made ( Just look at the following code )
The revised code is as follows :
2_1.cu
#include<stdio.h>#include<stdint.h>#include<time.h> //for time()#include<stdlib.h> //for srand()/rand()#include<sys/time.h> //for gettimeofday()/struct timeval#include"error.cuh"#define N 10000000#define BLOCK_SIZE 256#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) #define TOPK 10__managed__ int source[N]; //input data__managed__ int final_result[TOPK] = {INT_MIN}; //scalar output__managed__ int _1pass_results[TOPK * BLOCKS];__device__ __host__ void insert_value(int* array, int k, int data){ for (int i = 0; i < k; i++) { if (array[i] == data) { return; } } if (data < array[k - 1]) return; for (int i = k - 2; i >= 0; i--) { if (data > array[i]) array[i + 1] = array[i]; else { array[i + 1] = data; return; } } array[0] = data;}__global__ void _sum_min_or_max(int *input, int count,int *output){ //__shared__ int max_per_block[BLOCK_SIZE]; __shared__ int topk_per_block[BLOCK_SIZE * TOPK]; //int max_temp = INT_MIN; int topk_temp [TOPK]; for(int i=0;i<TOPK;i++) topk_temp[i] = INT_MIN; for (int idx = threadIdx.x + blockDim.x * blockIdx.x; idx < count; idx += gridDim.x * blockDim.x ) { //max_temp = (input[idx] > max_temp) ? input[idx] :max_temp; insert_value(topk_temp, TOPK, input[idx]); } //max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp! for(int i = 0; i< TOPK ; i++) { topk_per_block[ threadIdx.x * TOPK + i] = topk_temp[i]; } __syncthreads(); //**********shared memory summation stage*********** for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2) { //int max_double_kill = -1; if (threadIdx.x < length) { //max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length]; for(int i=0;i<TOPK ;i++) { insert_value(topk_temp, TOPK , topk_per_block[ (threadIdx.x + length) * TOPK + i]); } } __syncthreads(); //why we need two __syncthreads() here, and, if (threadIdx.x < length) { //max_per_block[threadIdx.x] = max_double_kill; for(int i=0;i<TOPK ;i++) { topk_per_block[threadIdx.x * TOPK + i]= topk_temp[i]; } } __syncthreads(); //....here ? } //the per-block partial sum is sum_per_block[0] if (blockDim.x * blockIdx.x < count) //in case that our users are naughty { //the final reduction performed by atomicAdd() // if (threadIdx.x == 0) atomicMax(&output[0], max_per_block[0]); if (threadIdx.x < TOPK) output[TOPK * blockIdx.x + threadIdx.x ] = topk_per_block[threadIdx.x]; /* for(int i=0;i<TOPK ;i++) { output[TOPK * blockIdx.x +i ] = topk_per_block[i]; } */ }}int _max_min_cpu(int *ptr, int count, int *max1, int *min1){ int max = INT_MIN; for (int i = 0; i < count; i++) { max = (ptr[i] > max)? ptr[i]:max; } //printf(" CPU max = %d\n", max); *max1 = max; return 0;}void cpu_result_topk(int* input, int count, int* output){ /*for (int i = 0; i < TOPK; i++) { output[i] = INT_MIN; }*/ for (int i = 0; i < count; i++) { insert_value(output, TOPK, input[i]); }}void _init(int *ptr, int count){ uint32_t seed = (uint32_t)time(NULL); //make huan happy srand(seed); //reseeding the random generator //filling the buffer with random data for (int i = 0; i < count; i++) { //ptr[i] = rand() % 100000000; ptr[i] = rand() ; if (i % 2 == 0) ptr[i] = 0 - ptr[i] ; } }double get_time(){ struct timeval tv; gettimeofday(&tv, NULL); return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);}int main(){ cudaEvent_t start, stop; CHECK(cudaEventCreate(&start)); CHECK(cudaEventCreate(&stop)); //********************************** fprintf(stderr, "filling the buffer with %d elements...\n", N); _init(source, N); //********************************** //Now we are going to kick start your kernel. CHECK(cudaEventRecord(start)); cudaDeviceSynchronize(); //steady! ready! go! fprintf(stderr, "Running on GPU...\n"); double t0 = get_time(); // _sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N,final_result); _sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N, _1pass_results); CHECK(cudaGetLastError()); //checking for launch failures _sum_min_or_max<<<1, BLOCK_SIZE>>>(_1pass_results, TOPK * BLOCKS, final_result); CHECK(cudaGetLastError()); //checking for launch failures CHECK(cudaDeviceSynchronize()); //checking for run-time failures CHECK(cudaEventRecord(stop)); CHECK(cudaEventSynchronize(stop)); double t1 = get_time(); for(int i=0;i<TOPK;i++) fprintf(stderr, " GPU max[%d]: %d\n", i,final_result[i]); //********************************** //Now we are going to exercise your CPU... fprintf(stderr, "Running on CPU...\n");double t2 = get_time(); int cpu_result[TOPK] = { 0 }; //int cpu_max=0; //int cpu_min=0; //int B = _max_min_cpu(source, N, &cpu_max, &cpu_min); cpu_result_topk(source, N, cpu_result); //printf(" CPU max = %d\n", cpu_max); double t3 = get_time(); //fprintf(stderr, "CPU sum: %u\n", B); int ok = 1; for (int i = 0; i < TOPK; ++i) { printf("cpu top%d: %d; gpu top%d: %d \n", i + 1, cpu_result[i], i + 1, final_result[i]); if (fabs(cpu_result[i] - final_result[i]) > (1.0e-10)) { ok = 0; } } if (ok) { printf("Pass!!!\n"); } else { printf("Error!!!\n"); } //******The last judgement********** /* //if ( final_result_max == cpu_max && final_result_min == cpu_min ) if ( final_result[0] == cpu_max ) { fprintf(stderr, "Test Passed!\n"); } else { fprintf(stderr, "Test failed!\n"); exit(-1); } */ //****and some timing details******* fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0); fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0); return 0;} So let's run this :
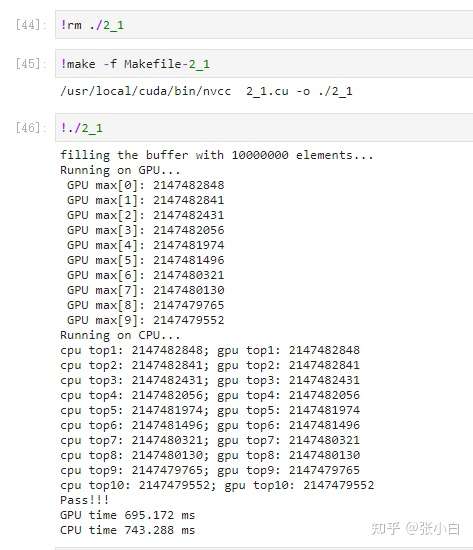
Like this, , count top5,top20,top50 It should be possible ?
top5:
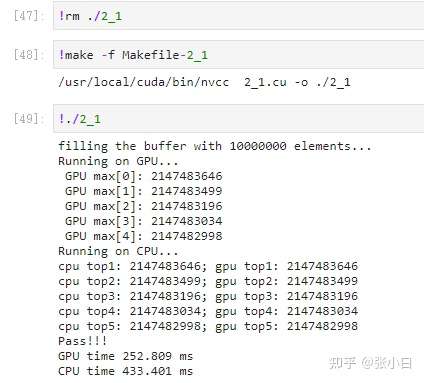
top20:
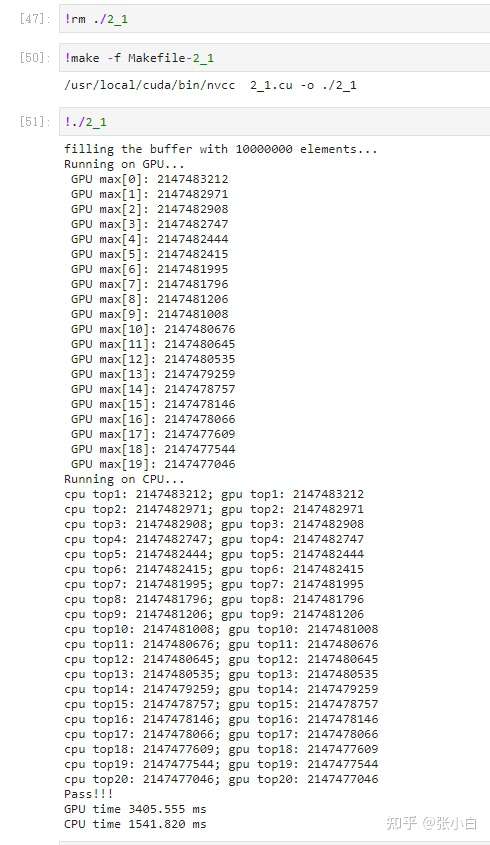
top50:

LOL, Zhang Xiaobai thought too well ~~
I have to change it to top40 have a look : It seems to be a little slow , But there is still a result :
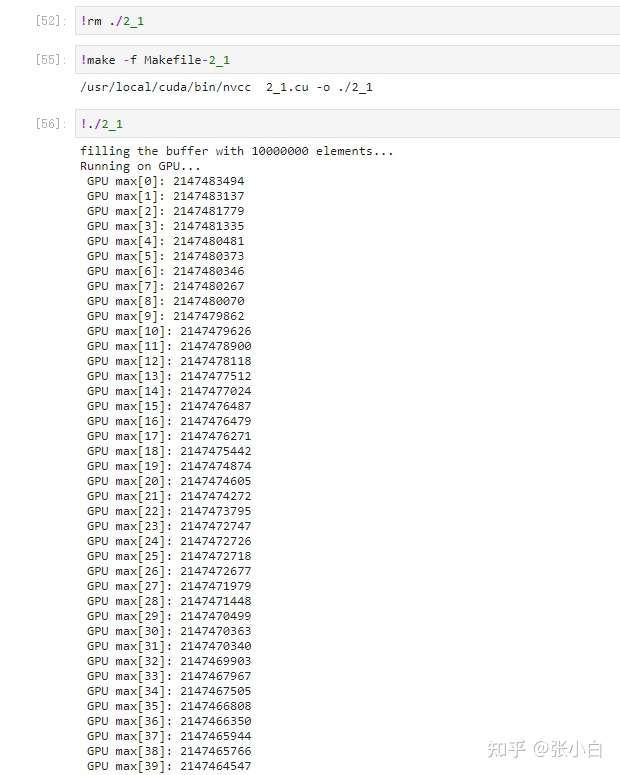

So what is a good way to calculate ?
also , Can the current method speed up ?
The weather of Xiao Jingteng , It also created several problems for Zhang Xiaobai ....
It seems that you have to study hard ...
in addition , Zhang Xiaobai forgot that he had another Jetson AGX Orin 了 . Let's see if it can break the lower limit :
Still use top40 Calculation .
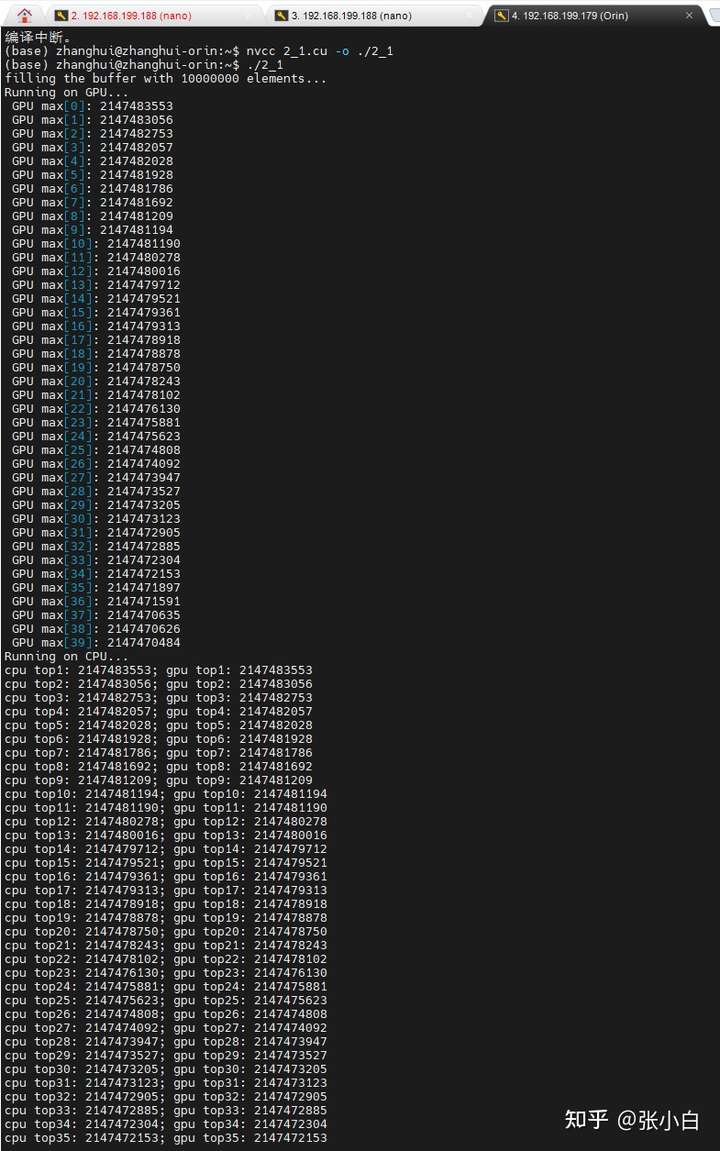
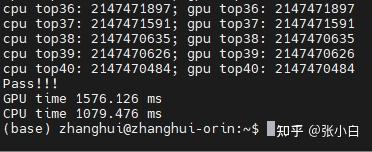
Do than Nano Much faster ( But I still can't run CPU)
Change to top50:

forehead , Still can't compile .4G Memory and 32G Memory devices , It seems shared memory It's the same size ??
Zhang Xiaobai silently looked at the definition :
__shared__ int topk_per_block[BLOCK_SIZE * TOPK];Yes, of course, . One block At most 48kB. in other words , If BLOCK_SIZE Set to 256 Words , that TOPK by 50 When ,256X50X4 Has more than 48K 了 .(1 individual int Occupy 4 Bytes ). So teacher Fan said ,BLOCK_SIZE=256 When ,TOPK As far as you can go 48.
Let's try :
#define BLOCK_SIZE 256#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) #define TOPK 48Nano The performance of the :

Change to TOP49, Sure enough, it can't be compiled :

There is only one way , Is to reduce BLOCK_SIZE, For example, change to 128. According to the previous algorithm ,128X4X96 be equal to 48K. And so on , You can count to 64,32 When the TOPN The largest number .
We won't take screenshots one by one , Fill in the results directly in the form :
Just one :

Form the following :
| TOPN | BLOCK_SIZE | Nano CPU(ms) | NanoGPU(ms) | Orin CPU(ms) | Orin GPU(ms) |
|---|---|---|---|---|---|
| 5 | 256 | 433.401 | 252.809 | 131.366 | 44.420 |
| 10 | 256 | 107.692 | 777.333 | 240.604 | 99.995 |
| 20 | 256 | 476.221 | 3414.480 | 511.257 | 256.927 |
| 40 | 256 | 765.036 | 29736.022 | 1079.476 | 1576.126 |
| 48 | 256 | 845.735 | 40406.832 | 1259.630 | 224.732 |
| 50 | 256 | Compile error | Compile error | ||
| 50 | 128 | 882.799 | 34380.985 | 1355.741 | 1512.643 |
| 100 | 64 | 1575.113 | 94527.526 | 2709.505 | 1940.573 |
| 96 | 128 | 1513 | 138183.392 | 2576.214 | 5307.144 |
| 97 | 128 | Compile error | Compile error | ||
| 192 | 64 | 2831.961 | 653679.935 | 5193.001 | 6091.511 |
| 193 | 64 | Compile error | Compile error | ||
| 384 | 32 | It's too long | It's too long | 70072.332 | 10363.466 |
| 385 | 32 | Compile error | Compile error | ||
| 48 | 128 | 859.618 | 32778.153 | 1293.652 | 1194.083 |
| 48 | 64 | 853.534 | 21058.578 | 1293.964 | 926.699 |
| 48 | 32 | 845.070 | 15701.802 | 1292.892 | 997.095 |
notes : The above results are only one measurement . It is not ruled out that there will be jitter or great difference in multiple measurements .
The above results confirm several things :
1. The maximum shared memory is only 48K, No more hair . It's hard to squeeze toothpaste .
2. The current reduce The algorithm still has great limitations , It's in TOPN It is more efficient when it is small .
3. about TOPN more , It's better to call cublas perhaps thrust Do a complete sort ( But Zhang Xiaobai didn't take the exam —— So I didn't study hard ..LOL.. Make it up next time )
4. Reduce BLOCKSIZE It is indeed possible to calculate , however BLOCKSIZE The smaller it is ,SN The smaller the share . One SM At most 2048( Or less ) The thread of , stay BLOCKSIZE=128 when , The occupancy rate is 6.25%;BLOCKSIZE=64 when , The occupancy rate is 3.125%;BLOCKSIZE=32 when , The occupancy rate is 1.5625%. As can be seen from the above results ,BLOCKSIZE Changes do cause great changes in performance .
Such as TOP48:
Orin from BLOCK 256-》128-》64》32 Namely 224ms-》1194ms-》926ms-》997ms. There is not much difference between the latter several ( Because there is preheating ), however 256 To 128 Great changes have taken place , It indicates that the best value is 256 here .
Nano from BLOCK 256-》128-》64》32 Namely 40s-》32s-》32s-》15s. Instead, it's BLOCK The smaller the speed, the faster . Of course, this does not mean that there is a proportional relationship . That means Nano The device is not running TOP48 The best machine selection .
therefore , Next test , If you can change it to Orin colony .. How wonderful the exam will be for everyone ~~~
In the final development CUDA When it comes to programming , It is from the perspective of the whole program , If a place is not the key , There is no need to optimize to the extreme . Any algorithm can be used . First, we should make efforts to solve the most critical part .
notes : Go to TOPK Insert TOPK Elements , And ultimately retain TOPK Elements ( Just leave TOPK Elements ), If you use the insertion method , The time complexity is O(n^2) Of . With K Expansion of , For instance from 10 A into 100 In the case of , The increase of algorithm time will be disastrous . This point can also be seen slightly in Zhang Xiaobai's test .
In fact, the children's shoes in the training camp have proposed a linear solution , For example, double pointer method , And such as bucket Law , You can combine two groups TOPK Elements are combined into 1 Groups are sorted by height K Elements , The time complexity of the algorithm at this time is O(n). in addition , For the distribution characteristics of random numbers , You can also quickly find TOPK. this , Zhang Xiaobai had to leave it as a question , I will study it again in the future ...
( To be continued )
边栏推荐
- Vim到底可以配置得多漂亮?
- Comprehensive and detailed SQL learning guide (MySQL direction)
- Performance optimization analysis tool | perf
- Achieve the effect of a menu tab
- 10 suggestions for 10x improvement of application performance
- Leetcode question brushing - sorting
- The function of that sentence
- [semantic segmentation] 2021-pvt2 cvmj
- Create PHP message board system with kubernetes
- Evolution of xxl-job architecture for distributed scheduling
猜你喜欢

函数——(C游记)

Comprehensive and detailed SQL learning guide (MySQL direction)

DW: optimize the training process of target detection and more comprehensive calculation of positive and negative weights | CVPR 2022

Comprehensively design an oppe home page -- the bottom of the page

Orbslam2 installation test and summary of various problems

MySQL 8 of relational database -- deepening and comprehensive learning from the inside out

remap_ Use of table in impdp

【论文阅读】Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
![[HFCTF 2021 Final]easyflask](/img/58/8113cafae8aeafcb1c9ad09eefd30f.jpg)
[HFCTF 2021 Final]easyflask

leetcode刷题——排序
随机推荐
HTB-AdmirerToo
The function of that sentence
Performance optimization analysis tool | perf
Modulenotfounderror: no module named 'pywt' solution
What are the compensation standards for hospital misdiagnosis? How much can the hospital pay?
[fortran]vscode配置fortran跑hello world
Attachment of text of chenjie Report
Introduction to distributed scheduling xxl-job features
DW: optimize the training process of target detection and more comprehensive calculation of positive and negative weights | CVPR 2022
[HFCTF 2021 Final]easyflask
架构实战营模块八作业
The server
ECCV 2022 | CMU提出在视觉Transformer上进行递归,不增参数,计算量还少
根据给定字符数和字符,打印输出“沙漏”和剩余数
不堆概念、换个角度聊多线程并发编程
Is it safe to open an account online now? Do you want to know that you must go to the business hall to open an account now?
Is error log monitoring enough? Don't try JVM monitoring of microservices
What happens when MySQL tables change from compressed tables to ordinary tables
跟着李老师学线代——行列式(持续更新)
云服务大厂高管大变阵:技术派让位销售派