当前位置:网站首页>CVPR 2022 | interpretation of 6 excellent papers selected by meituan technical team
CVPR 2022 | interpretation of 6 excellent papers selected by meituan technical team
2022-07-03 13:29:00 【Haibao 7】
CVPR 2022 | Interpretation of selected papers of meituan technical team
International Conference on computer vision CVPR 2022 Recently, it was held in New Orleans , This year, many papers of the meituan technical team were CVPR 2022 Included , These papers cover model compression 、 Video target segmentation 、3D Visual positioning 、 Image description 、 Model security 、 Cross modal video content retrieval and other research fields .
This article will 6 A brief introduction to selected papers ( Download link attached ), I hope it can be helpful or enlightening to students engaged in relevant research .
Paper 01 | Compressing Models with Few Samples: Mimicking then
ReplacingPaper 02 | Language-Bridged Spatial-Temporal Interaction for Referring
Video Object SegmentationPaper 03 | 3D-SPS: Single-Stage 3D Visual Grounding via Referred Point
Progressive SelectionPaper 04 | DeeCap: Dynamic Early Exiting for Efficient Image
CaptioningPaper 05 | Boosting Black-Box Attack with Partially Transferred
Conditional Adversarial DistributionPaper 06 | Semi-supervised Video Paragraph Grounding with Contrastive
Encoder
CVPR Introduce
CVPR The full name is IEEE International Conference on computer vision and pattern recognition (IEEE Conference on Computer Vision and Pattern Recognition), The meeting began with 1983 year , And ICCV and ECCV It is also called the top three conferences on computer vision . According to Google academic 2021 Ranking of the latest academic journals and conferences in ,CVPR Ranked No. in all academic journals 4, Second only to Nature、NEJM and Science.CVPR This year, we received a total of 8100 Multiple papers submitted , Final 2067 Received , The reception rate is about 25%.
Paper 01 |
Compressing Models with Few Samples: Mimicking then Replacing
Author of the paper : Wanghuanyu ( Meituan intern & Nanjing University ), Liu Junjie ( Meituan ), Ma Xin ( Meituan ), Yong Yang ( Meituan intern & Xi'an Jiaotong University ), Chaizhenhua ( Meituan ), Wujianxin ( Nanjing University )
| remarks : What is in brackets is when the paper is published , The unit where the author of the paper belongs . | Types of papers :CVPR Main Conference(Long Paper)
Model pruning is a mature research direction in model compression , But in millions / The time-consuming problem of tuning after pruning under tens of millions of data sets , It is an important pain point restricting the promotion of this direction . In recent years , Model pruning under small samples has attracted the attention of the academic circles , Especially in large-scale data sets or data source sensitive scenarios , It can quickly complete the compression and optimization of the model . however , The layer by layer channel alignment method used in the existing research , In the complex structure, it will greatly limit the scope of the prunable area . meanwhile , In case of uneven sample distribution , Overemphasize the consistency of feature distribution between layers , On the contrary, it will lead to optimization error .
Contrary to intuition , In this paper, we propose a new method called MiR (Mimicking then Replacing) Methods – Use only Penultimate Layer The transfer of knowledge , It discards the posterior distribution alignment that the traditional knowledge distillation method relies on . And by grafting the classification head in the original model / Detect the compressed model , It can quickly complete the re - tuning of the compression model under a small number of samples . Experiments show that the algorithm proposed in this paper is much better than various baseline methods ( And better than the same period TPAMI Work ), At the same time, we are in the scene of meituan image security audit , It has also been further verified .

Paper 02 |
Language-Bridged Spatial-Temporal Interaction for Referring Video Object Segmentation
Author of the paper : Ding Zihan ( Meituan ), Hui Tianrui ( University of Chinese Academy of Sciences ), Huangjunshi ( Meituan ), Wei Xiaoming ( Meituan ), Han Jizhong ( University of Chinese Academy of Sciences ), Liu He ( Beijing university of aeronautics and astronautics ) |
Types of papers :CVPR 2022 Main Conference Long Paper(Poster)
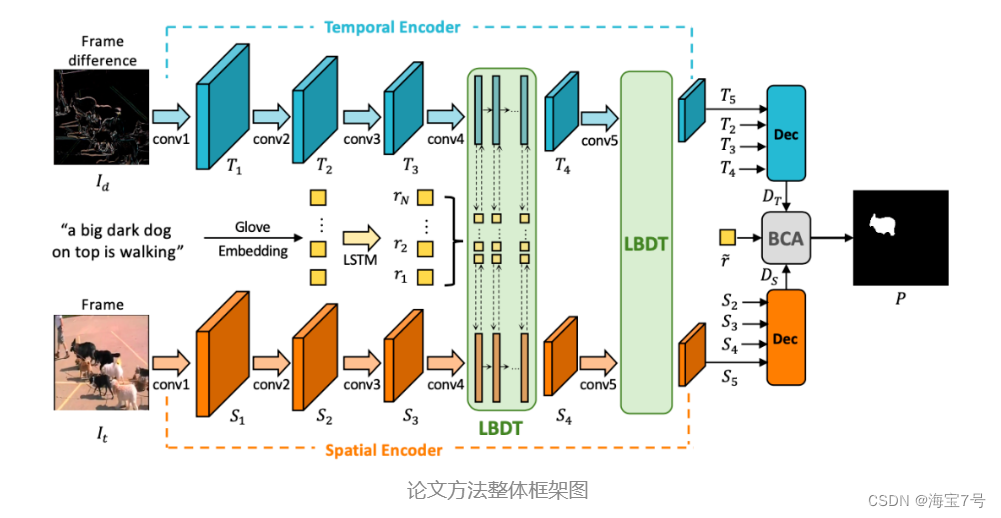
Video object refers to segmentation , It aims to segment the foreground pixels of the object referred to in the natural language description in the video . Previous approaches either relied on 3D Convolution network , Or in combination with additional 2D The winder network acts as an encoder to extract mixed spatiotemporal features . However , Due to the delay and implicit spatiotemporal interaction in the decoding phase , These methods have the problems of spatial dislocation or error interference .
To address these limitations , We propose a language bridging two-way transmission (LBDT) modular , This module uses language as an intermediate bridge , Explicit and adaptive spatiotemporal interactions are accomplished early in the coding phase . say concretely , In the time encoder 、 Between pronouns and spatial coders , We aggregate and transmit language related motion and apparent information through the cross modal attention mechanism . Besides , We also propose a bilateral channel activation in the decoding phase (BCA) modular , It is used to further denoise and highlight spatiotemporal consistent features through channel activation . A lot of experiments show that , Our method achieves optimal performance in four commonly used public data sets without pre training of image referential segmentation , And the efficiency of the model has been significantly improved .
Paper 03 |
3D-SPS: Single-Stage 3D Visual Grounding via Referred Point Progressive Selection
Author of the paper : Luo Junyu ( Meituan intern & Beijing university of aeronautics and astronautics ), Fujiahui ( Meituan intern & Beijing university of aeronautics and astronautics ), Kongxianghao ( Meituan intern & Beijing university of aeronautics and astronautics ), Gao Chen ( Beijing university of aeronautics and astronautics ), Ren Haibing ( Meituan ), Shen Hao ( Meituan ), Xia Huaxia ( Meituan ), Liu He ( Beijing university of aeronautics and astronautics )
| Types of papers :CVPR 2022 Main Conference(Oral)
3D The visual localization task aims to locate the described object in the point cloud scene according to the natural language . Most of the previous methods follow the two-stage paradigm , That is, language independent target detection and cross modal target matching , In this paradigm of separation , Because the point cloud is compared to the image , It has the characteristics of irregularity and large scale , The detector needs to sample keys from the original point cloud and generate a preselection box for each key .
however , Sparse pre selection boxes may miss potential targets during the detection phase , The dense pre selection box may increase the difficulty of the later matching stage . Besides , The proportion of key points obtained from language independent sampling is also small , It also makes the target prediction worse .
In this paper , We propose a single-stage progressive selection of key points (3D-SPS) Method , Thus, under the guidance of language, we can gradually select key points and directly locate the target . say concretely , We propose a key point sampling method to describe perception (DKS) modular , To initially focus on the point cloud data on language related objects .
Besides , We designed a goal - oriented progressive relationship mining (TPM) modular , It focuses on the target object by modeling the multi-layer intra modal relationship and mining the inter modal objects .3D-SPS Avoided 3D Separation between detection and matching in visual localization task , Direct targeting in a single phase .
Paper 04 |
DeeCap: Dynamic Early Exiting for Efficient Image Captioning
| Author of the paper : Fei zhengcong ( Meituan ), Yan Xu ( Institute of computing, Chinese Academy of Sciences ), Wang Shuhui ( Institute of computing, Chinese Academy of Sciences ), Tian Qi ( Huawei ) | Types of papers :CVPR 2022 Main
Conference Long Paper(Poster)
Accurate description and efficient generation , It is very important for the application of image description in real scenes . be based on Transformer A significant performance improvement has been achieved for the model , But the computational cost of the model is very high . A feasible method to reduce the time complexity is to early exit from the shallow layer in the internal decoding layer for prediction , And not through the processing of the whole model .
However , We found the following in the actual test 2 A question : First , The learning representation in the shallow layer lacks high-level semantics for accurate prediction and sufficient cross modal fusion information ; secondly , Existing decisions made by internal classifiers are sometimes unreliable .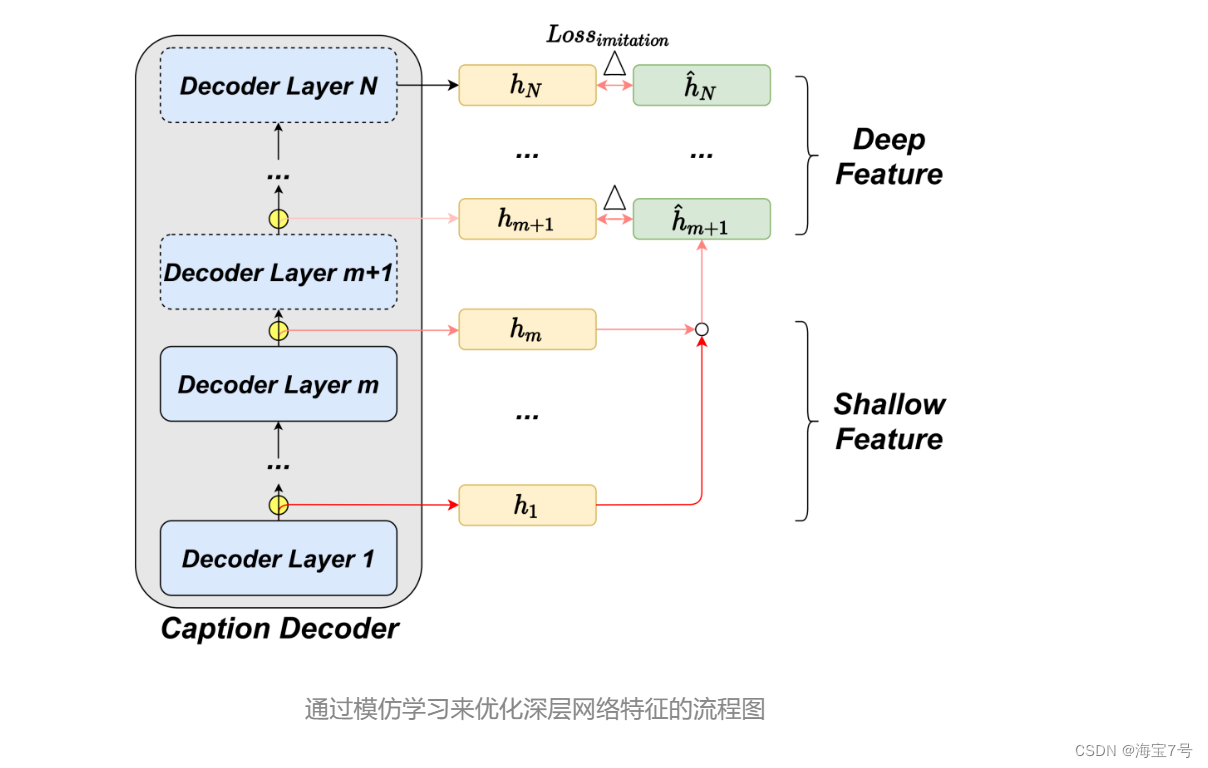
Regarding this , We propose a method for efficient image description DeeCap frame , Dynamically select the appropriate number of decoding layers from the global perspective to exit in advance . The key to accurate exit lies in the introduction of imitation learning mechanism , It uses shallow features to predict deep features . By incorporating imitation learning into the whole image description model , The simulated deep representation can reduce the loss caused by the lack of actual deep representation during early exit , Thus, the computing cost is effectively reduced , And ensure that the loss of accuracy is very small .
stay MS COCO and Flickr30K Experiments on data sets show that , What this article puts forward DeeCap The model has 4 Double acceleration while maintaining very competitive performance . Related code link :DeeCap.
Paper 05 |
Boosting Black-Box Attack with Partially Transferred Conditional Adversarial Distribution
| Author of the paper : Feng Yan ( Meituan ), Wu Baoyuan ( Chinese University of Hong Kong ), Fanyanbo ( tencent ), Liu Li ( Chinese University of Hong Kong ), Li Zhifeng ( tencent ), Xia Shutao ( Tsinghua University )
| Types of papers :CVPR 2022 Main Conference Long Paper(Poster)
This paper studies model security in black box scenario , That is, the attacker only gives through the model query feedback, To attack the target model . The current mainstream method is to use some white box agent models and target models ( The attacked model ) The antagonism between them is transferable (adversarial transferrability) To improve the attack effect .
However , There may be differences in the model architecture and training data set between the agent model and the target model , namely “ Proxy deviation ”(Surrogate Bias), The contribution of adversarial mobility to improving attack performance may be weakened .
To solve this problem , In this paper, we propose an anti - mobility mechanism which is robust to agent bias . The general idea is to transfer some parameters of the conditional antagonism distribution of the agent model , At the same time, according to the Query Learn non migrated parameters , To maintain the flexibility of adjusting the conditions of the target model against the distribution on any new clean sample .
In this paper, large-scale data sets and real API A lot of experiments have been done on , The experimental results prove the effectiveness of the proposed method .
Paper 06 |
Semi-supervised Video Paragraph Grounding with Contrastive Encoder
| Author of the paper : Jiangxun ( University of electronic technology ), Xu Xing ( University of electronic technology ), Zhangjingran ( University of electronic technology ), Shenfumin ( University of electronic technology ), Cao Zuo ( Meituan ), Shen hengtao ( University of electronic technology )
| Types of papers :CVPR Main Conference, Long Paper(Poster)
Video event location is a task of cross modal video content retrieval , Designed to be based on the input Query, Retrieve from an uncut video Query Corresponding video clip , Corresponding video clips can be used for subsequent generation Query Corresponding dynamic diagram , In the search scenario, the dynamic graph is searched by .
And video text retrieval (Video-Text Retrieval, VTR) The retrieval result is different from the coarse-grained retrieval mechanism of video files , This task emphasizes fine-grained cross modal retrieval at the event level in video , Based on Collaborative understanding of video content and natural language , Achieve alignment between multiple modes in time sequence .
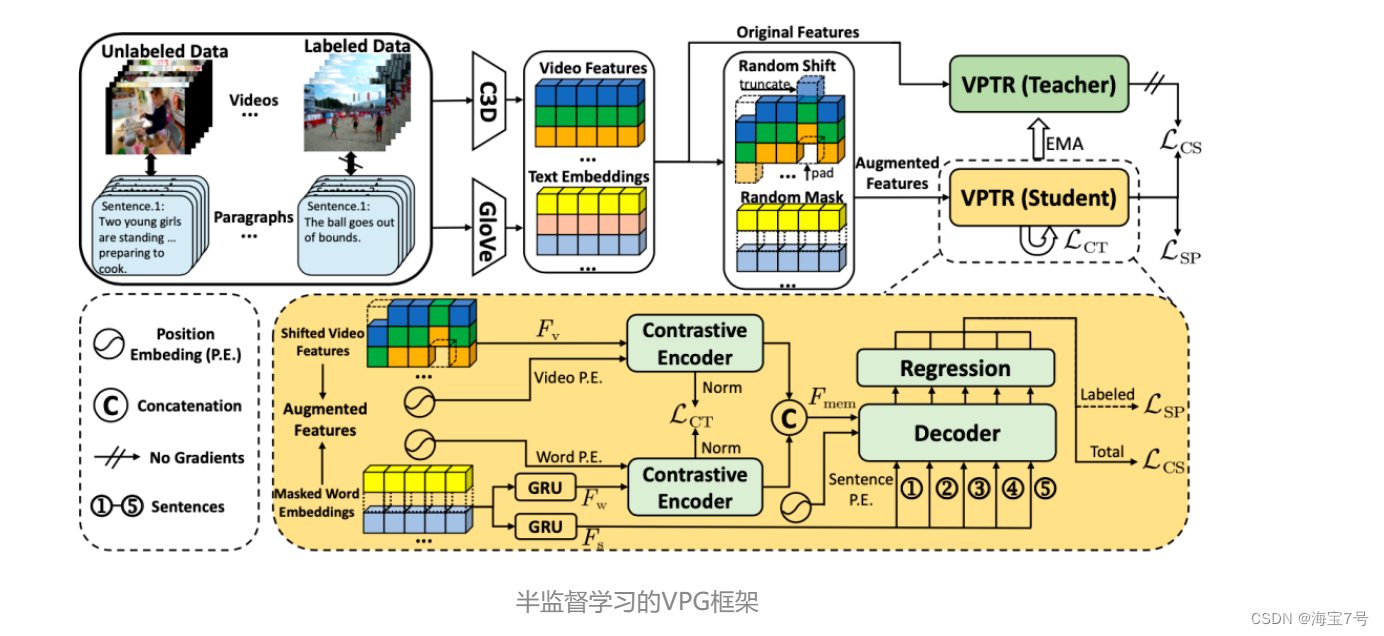
In this paper, a semi supervised learning method is proposed for the first time VPG frame , You can use the event context information in a paragraph more effectively while , Significantly reduce the dependence on time annotation data . say concretely , It consists of two key components :(1) One is based on Transformer The basic model of , Learn coarse-grained alignment between video and paragraph text by comparing encoders , At the same time, the context information between events is learned by guiding the interaction between each sentence in the paragraph ;(2) One by (1) As the core of the semi supervised learning framework , The average teacher model is used to reduce the dependence on annotated data . Experimental results show that , The performance of our method is SOTA, At the same time, in the case of greatly reducing the proportion of annotation data , Still able to achieve quite competitive results .
Besides , stay CVPR 2022 in , The visual intelligence department of meituan technical team won the 9th fine-grained visual classification seminar (FGVC9) The champion of the herbarium identification track , The review division won the champion of the large-scale cross modal product image recall competition . Besides , The car Hailing business division of meituan.com has won the lightweight NAS Runner up in the international competition . Meituan visual intelligence department won the third place in the deep fake face detection competition 、SoccerNet 2022 Third place in the pedestrian recognition competition 、 Large scale video target segmentation competition (Youtube-VOS) Fifth place .
Related technology sharing , Subsequently, it will be pushed successively on the official account of meituan technical team , Coming soon .
The source of the original :https://mp.weixin.qq.com/s/sblDFcBUI4U8ZPHWN9leow
Meituan technical team
https://tech.meituan.com/
2021 Meituan technology annual collection :http://dpurl.cn/6YkRcBYz
2019-2021 Front end collection :http://dpurl.cn/LP0HtN7z
2019-2021 Back end collection :http://dpurl.cn/r416CCBz
2019-2021 Annual algorithm collection :http://dpurl.cn/xKyb85dz
2019-2021 Comprehensive articles in :http://dpurl.cn/narxiDez
Meituan technical team Also actively participate in international challenges , Hope to put more scientific research projects into practice , And then generate more business value and social value . The problems and solutions we encountered in the actual work scenario , It is reflected in the thesis and the competition , I hope it can be helpful or enlightening , You are also welcome to communicate with us .
边栏推荐
- JSON serialization case summary
- The network card fails to start after the cold migration of the server hard disk
- Introduction to the implementation principle of rxjs observable filter operator
- Useful blog links
- Idea full text search shortcut ctr+shift+f failure problem
- JS convert pseudo array to array
- R语言使用data函数获取当前R环境可用的示例数据集:获取datasets包中的所有示例数据集、获取所有包的数据集、获取特定包的数据集
- 18W word Flink SQL God Road manual, born in the sky
- stm32和电机开发(从mcu到架构设计)
- 2022-02-11 heap sorting and recursion
猜你喜欢
已解决TypeError: Argument ‘parser‘ has incorrect type (expected lxml.etree._BaseParser, got type)

Libuv库 - 设计概述(中文版)

Road construction issues

正则表达式

MySQL functions and related cases and exercises

MySQL installation, uninstallation, initial password setting and general commands of Linux

Sword finger offer 14- ii Cut rope II

Can newly graduated European college students get an offer from a major Internet company in the United States?
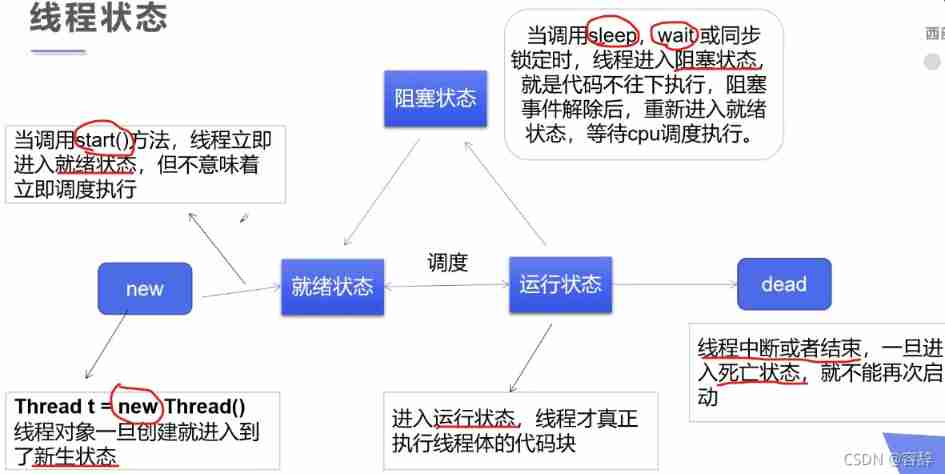
Detailed explanation of multithreading

【电脑插入U盘或者内存卡显示无法格式化FAT32如何解决】
随机推荐
Oracle memory management
Task6: using transformer for emotion analysis
untiy世界边缘的物体阴影闪动,靠近远点的物体阴影正常
JS 将伪数组转换成数组
Today's sleep quality record 77 points
双链笔记 RemNote 综合评测:快速输入、PDF 阅读、间隔重复/记忆
Flink code is written like this. It's strange that the window can be triggered (bad programming habits)
Logback 日志框架
Resolved (error in viewing data information in machine learning) attributeerror: target_ names
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter V exercises]
MySQL constraints
71 articles on Flink practice and principle analysis (necessary for interview)
Asp.Net Core1.1版本没了project.json,这样来生成跨平台包
Can newly graduated European college students get an offer from a major Internet company in the United States?
My creation anniversary: the fifth anniversary
Father and basketball
Libuv库 - 设计概述(中文版)
Sword finger offer 16 Integer power of numeric value
STM32 and motor development (from MCU to architecture design)
Solve system has not been booted with SYSTEMd as init system (PID 1) Can‘t operate.