当前位置:网站首页>When we are doing flow batch integration, what are we doing?
When we are doing flow batch integration, what are we doing?
2022-07-03 13:10:00 【Big data sheep said】
1. Preface
This article mainly shares the background of the integration of streaming and batching that bloggers understand at present , The problem I want to solve , And the ideas that may be realized in the future , And introduce it with several cases . throw away a brick in order to get a gem , Let us not only stay in the integration of flow and batch , But to think more deeply about the reasons behind .
2. background
Before introducing the integration of flow and batch , First, let's take a look at the engines commonly used in the field of flow and batch :
Batch task : Commonly used Hive、Spark.
Flow task : Commonly used Flink.Spark Streaming And Storm Currently, the usage rate in the streaming scenario will be less than Flink.
3. What problem led to the concept of integrating flow and batch ?
A premise : In the production scenario , When indicators of the same caliber use flow tasks to produce real-time data , Offline data is produced with batch tasks , Will consider whether it is necessary to integrate flow and batch . If an indicator only needs to output offline , What about the integration of flow and batch ?
An angle : Bloggers think , The integration of flow and batch should be considered from the perspective of flow , To put the results of the flow task in the batch field ( Or in the form of batch data ) Reuse , Not just on the side of the engine ,API Interface level unification . This thinking is similar to Ali in the figure below (From FFA 2020) The point of view of the said problem is similar , Bloggers understand that real-time reuse in the offline field may be an abstraction of the problems listed by Alibaba . Because if it can be reused , The three problems in the figure below do not exist !

Problem solved : On the basis of the above premise and thinking angle , Bloggers think , At present, the most important thing to be solved in the integration of flow and batch is to solve the quality problem of flow task output data , This is also the premise that stream data can be reused in batch scenarios . Used to Flink Students who do real-time data development should have encountered Flink When producing data , There will always be some exceptions ( For example, the use of windows may lead to loss of numbers ) Lead to and offline Hive、Spark There are some slight differences in the output data , In this way, it is impossible to reuse real-time data in the offline field . Bloggers understand , The key to the integration of flow and batch is to solve this problem , Others are in resource conservation 、 The advantages in improving human efficiency are based on the added value .
4. So what is the cause of data quality problems in flow tasks , What are the common scenarios ?
Bloggers think , At present, the most important reason is the data quality problem caused by data disorder .
There are two common scenarios in the real-time field :
The first is Flink The scene of task opening window . give an example , One opened TUMBLE WINDOW Of Flink Mission , Encounter serious data disorder ( The maximum disorder of user configuration 、 Parameters such as allowable delay cannot be solved ), Then the task will throw away the data , This scenario will lead to differences between real-time data and offline data .
The second is the scenario of real-time dimension table Association . If the data of the fact table comes first , The data in the dimension table cannot be associated . Thus, it is different from offline .
Of course, there are other scenes , Here is not a list .
5. Want to solve the above data quality problems , What are the feasible ideas ?
- Idealized thinking : With TUMBLE WINDOW For example , TUMBLE WINDOW Our original intention is to produce constant results ( namely append flow ), Therefore, data with great delay cannot be processed , Then we can TUMBLE WINDOW Use GROUP AGG(retract flow 、 Or called CDC Pattern ) Replace to calculate . When there is late data ,GROUP AGG It will handle normally and withdraw the last result , Issue the new results of recalculation . But the problem with this method is if we want to use CDC Mode to run tasks , We need the whole link to CDC The mode to run , Including computing engines 、 Message queue 、OLAP Engine, etc , But also to protect Exactly-once.( But when it comes to CDC Did you think of the data Lake ? This may also be a follow-up development direction ). Then take Ali (From FFA 2020) One minute mentioned \ Examples of hourly cumulative indicators , Let's see how Ali does it . Alibaba actually uses GROUP AGG Do the calculations ( But I don't know whether to use the following link CDC The way it works ).
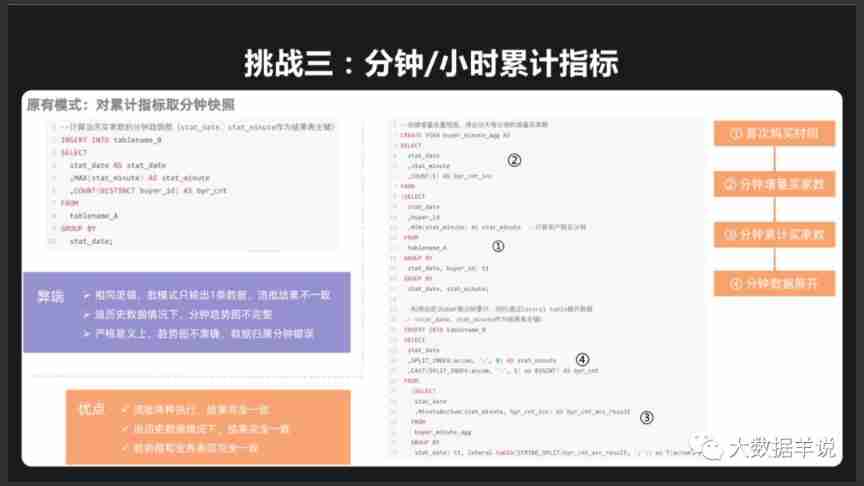
minute / Hourly cumulative indicator
- Ali's idea (From FFA 2020): As shown in the figure below , Scenario 1 is if the input source of stream batch integration is different , Batch task scheduling correction results are required , Scenario 2 is if the flow batch results are the same , Don't run the batch task . In the first case, there is nothing to say ; But in the second case , Here is a brief analysis of : We know that the premise of verifying the same flow batch results is , Run a batch of tasks and produce results. Take the initiative to compare the results with those of flow tasks , But in scenario 2, the batch task is actually not running !!! So what can be thought of here is the need to be in advance 、 In the matter 、 After the event, a lot of monitoring is done to ensure that the overall process of flow task output has no problems , So as to ensure that we can achieve and Expected batch tasks The results are the same .

Comparison of new and old R & D modes
summary : The first idea above is relatively idealized , Basically, we think from the perspective that the data produced by flow tasks can be reused in batch mode , Leaving aside the batch tasks, the implementation of this process . The second kind of Ali FFA 2020 In comparison, the link software and hardware conditions are not so high , Bloggers think it is more feasible .
6. summary
This paper mainly introduces the following three parts :
The birth of flow batch integration is to solve the problem that the same indicator is offline 、 The difference of real-time task output data ( Data quality )
The root cause of data differences is data disorder
If you want to solve this problem , Idealization is full link CDC, For more operational ideas, please refer to Alibaba FFA 2020
Please pay attention to what you like + give the thumbs-up + Look again .
Previous recommendation
[
flink sql Know why ( 6、 ... and )| flink sql Appointment calcite( Just read this one )
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489112&idx=1&sn=21e86dab0e20da211c28cd0963b75ee2&chksm=c1549aa0f62313b6674833cd376b2a694752a154a63532ec9446c9c3013ef97f2d57b4e2eb64&scene=21#wechat_redirect)
[
flink sql Know why ( 5、 ... and )| Customize protobuf format
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488994&idx=1&sn=20236350b1c8cfc4ec5055687b35603d&chksm=c154991af623100c46c0ed224a8264be08235ab30c9f191df7400e69a8ee873a3b74859fb0b7&scene=21#wechat_redirect)
[
flink sql Know why ( Four )| sql api Type system
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488788&idx=1&sn=0127fd4037788762a0401313b43b0ea5&chksm=c15499ecf62310fa747c530f722e631570a1b0469af2a693e9f48d3a660aa2c15e610653fe8c&scene=21#wechat_redirect)
[
flink sql Know why ( 3、 ... and )| Customize redis Data summary ( Source code attached )
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488720&idx=1&sn=5695e3691b55a7e40814d0e455dbe92a&chksm=c1549828f623113e9959a382f98dc9033997dd4bdcb127f9fb2fbea046545b527233d4c3510e&scene=21#wechat_redirect)
[
flink sql Know why ( Two )| Customize redis Data dimension table ( Source code attached )
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488635&idx=1&sn=41817a078ef456fb036e94072b2383ff&chksm=c1549883f623119559c47047c6d2a9540531e0e6f0b58b155ef9da17e37e32a9c486fe50f8e3&scene=21#wechat_redirect)
[
flink sql Know why ( One )| source\sink principle
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488486&idx=1&sn=b9bdb56e44631145c8cc6354a093e7c0&chksm=c1549f1ef623160834e3c5661c155ec421699fc18c57f2c63ba14d33bab1d37c5930fdce016b&scene=21#wechat_redirect)
边栏推荐
- Kotlin notes - popular knowledge points asterisk (*)
- [exercise 6] [Database Principle]
- Image component in ETS development mode of openharmony application development
- elk笔记24--用gohangout替代logstash消费日志
- Create a dojo progress bar programmatically: Dojo ProgressBar
- 【习题六】【数据库原理】
- Kotlin - improved decorator mode
- 2022-02-14 analysis of the startup and request processing process of the incluxdb cluster Coordinator
- 【数据库原理及应用教程(第4版|微课版)陈志泊】【第五章习题】
- Tencent cloud tdsql database delivery and operation and maintenance Junior Engineer - some questions of Tencent cloud cloudlite certification (TCA) examination
猜你喜欢

高效能人士的七个习惯
Seven second order ladrc-pll structure design of active disturbance rejection controller

elk笔记24--用gohangout替代logstash消费日志
对业务的一些思考

Dojo tutorials:getting started with deferrals source code and example execution summary

Analysis of a music player Login Protocol
![[problem exploration and solution of one or more filters or listeners failing to start]](/img/82/e7730d289c4c1c4800b520c58d975a.jpg)
[problem exploration and solution of one or more filters or listeners failing to start]

Application of ncnn neural network computing framework in orange school orangepi 3 lts development board
![[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter IV exercises]](/img/8b/bef94d11ac22e3762a570dab3a96fa.jpg)
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter IV exercises]
Elk note 24 -- replace logstash consumption log with gohangout
随机推荐
Leetcode234 palindrome linked list
正则表达式
【数据库原理及应用教程(第4版|微课版)陈志泊】【SQLServer2012综合练习】
2022-02-09 survey of incluxdb cluster
高效能人士的七个习惯
Simple use and precautions of kotlin's array array and set list
2022-01-27 redis cluster cluster proxy predixy analysis
如何在微信小程序中获取用户位置?
Ali & ant self developed IDE
[Exercice 5] [principe de la base de données]
Dojo tutorials:getting started with deferrals source code and example execution summary
sitesCMS v3.0.2发布,升级JFinal等依赖
Huffman coding experiment report
elk笔记24--用gohangout替代logstash消费日志
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter III exercises]
IDEA 全文搜索快捷键Ctr+Shift+F失效问题
有限状态机FSM
【习题七】【数据库原理】
【习题六】【数据库原理】
Logback log framework