当前位置:网站首页>2022-02-14 analysis of the startup and request processing process of the incluxdb cluster Coordinator
2022-02-14 analysis of the startup and request processing process of the incluxdb cluster Coordinator
2022-07-03 13:04:00 【a tracer】
Catalog
It can be seen that the process is as follows :
Open up a new collaboration for each new connection :
Read the data and parse the request :
With executeSelectStatement As an example of request processing source code :
Abstract :
analysis influxdb Cluster startup and request processing process
Sequence diagram :
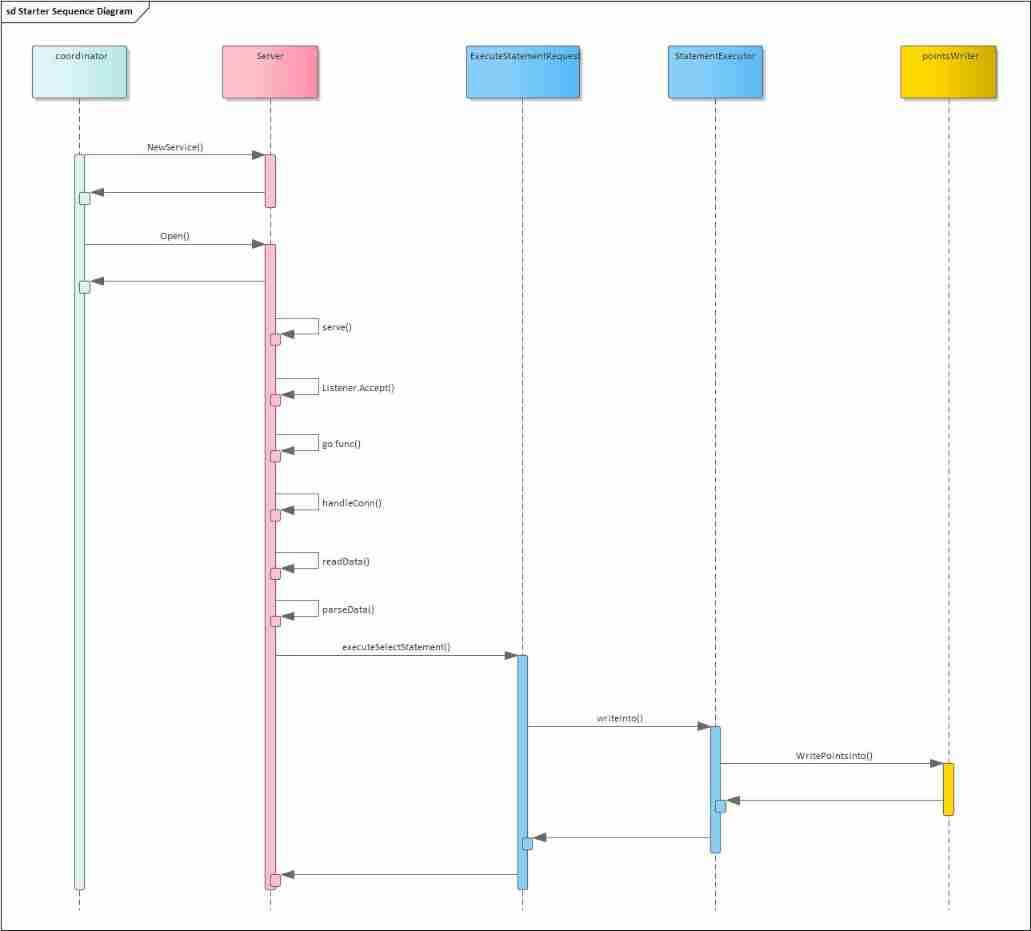
It can be seen that the process is as follows :
- After starting the service, listen to the corresponding port
- After connection is requested , Create a new process to process the data of the connection
- Each connection has a separate coprocessor processing data
- Read the data sent by the connection , Resolve request
- Make different interface distribution according to the type of request
Source code processing :
Start the service :
// Service processes data received over raw TCP connections.
type Service struct {
mu sync.RWMutex
wg sync.WaitGroup
closing chan struct{}
Listener net.Listener
MetaClient interface {
ShardOwner(shardID uint64) (string, string, *meta.ShardGroupInfo)
}
TSDBStore TSDBStore
Logger *zap.Logger
statMap *expvar.Map
}
// NewService returns a new instance of Service.
func NewService(c Config) *Service {
return &Service{
closing: make(chan struct{}),
//Logger: log.New(os.Stderr, "[cluster] ", log.LstdFlags),
Logger: zap.NewNop(),
statMap: freetsdb.NewStatistics("cluster", "cluster", nil),
}
}
// Open opens the network listener and begins serving requests.
func (s *Service) Open() error {
s.Logger.Info("Starting cluster service")
// Begin serving conections.
s.wg.Add(1)
go s.serve()
return nil
}Open up a new collaboration for each new connection :
// serve accepts connections from the listener and handles them.
func (s *Service) serve() {
defer s.wg.Done()
for {
// Check if the service is shutting down.
select {
case <-s.closing:
return
default:
}
// Accept the next connection.
conn, err := s.Listener.Accept()
if err != nil {
if strings.Contains(err.Error(), "connection closed") {
s.Logger.Info("cluster service accept", zap.Error(err))
return
}
s.Logger.Info("accept", zap.Error(err))
continue
}
// Delegate connection handling to a separate goroutine.
s.wg.Add(1)
go func() {
defer s.wg.Done()
s.handleConn(conn)
}()
}
}
Read the data and parse the request :
// handleConn services an individual TCP connection.
func (s *Service) handleConn(conn net.Conn) {
// Ensure connection is closed when service is closed.
closing := make(chan struct{})
defer close(closing)
go func() {
select {
case <-closing:
case <-s.closing:
}
conn.Close()
}()
for {
// Read type-length-value.
typ, err := ReadType(conn)
if err != nil {
if strings.HasSuffix(err.Error(), "EOF") {
return
}
s.Logger.Info("unable to read type", zap.Error(err))
return
}
// Delegate message processing by type.
switch typ {
case writeShardRequestMessage:
buf, err := ReadLV(conn)
if err != nil {
s.Logger.Info("unable to read length-value:", zap.Error(err))
return
}
s.statMap.Add(writeShardReq, 1)
err = s.processWriteShardRequest(buf)
if err != nil {
s.Logger.Info("process write shard error:", zap.Error(err))
}
s.writeShardResponse(conn, err)
case executeStatementRequestMessage:
buf, err := ReadLV(conn)
if err != nil {
s.Logger.Info("unable to read length-value:", zap.Error(err))
return
}
err = s.processExecuteStatementRequest(buf)
if err != nil {
s.Logger.Info("process execute statement error:", zap.Error(err))
}
s.writeShardResponse(conn, err)
case createIteratorRequestMessage:
s.statMap.Add(createIteratorReq, 1)
s.processCreateIteratorRequest(conn)
return
case fieldDimensionsRequestMessage:
s.statMap.Add(fieldDimensionsReq, 1)
s.processFieldDimensionsRequest(conn)
return
default:
s.Logger.Info("coordinator service message type not found:", zap.Uint8("Type", uint8(typ)))
}
}
}
With executeSelectStatement As an example of request processing source code :
func (e *StatementExecutor) executeSelectStatement(stmt *influxql.SelectStatement, ctx *query.ExecutionContext) error {
cur, err := e.createIterators(ctx, stmt, ctx.ExecutionOptions)
if err != nil {
return err
}
// Generate a row emitter from the iterator set.
em := query.NewEmitter(cur, ctx.ChunkSize)
defer em.Close()
// Emit rows to the results channel.
var writeN int64
var emitted bool
var pointsWriter *BufferedPointsWriter
if stmt.Target != nil {
pointsWriter = NewBufferedPointsWriter(e.PointsWriter, stmt.Target.Measurement.Database, stmt.Target.Measurement.RetentionPolicy, 10000)
}
for {
row, partial, err := em.Emit()
if err != nil {
return err
} else if row == nil {
// Check if the query was interrupted while emitting.
select {
case <-ctx.Done():
return ctx.Err()
default:
}
break
}
// Write points back into system for INTO statements.
if stmt.Target != nil {
n, err := e.writeInto(pointsWriter, stmt, row)
if err != nil {
return err
}
writeN += n
continue
}
result := &query.Result{
Series: []*models.Row{row},
Partial: partial,
}
// Send results or exit if closing.
if err := ctx.Send(result); err != nil {
return err
}
emitted = true
}
// Flush remaining points and emit write count if an INTO statement.
if stmt.Target != nil {
if err := pointsWriter.Flush(); err != nil {
return err
}
var messages []*query.Message
if ctx.ReadOnly {
messages = append(messages, query.ReadOnlyWarning(stmt.String()))
}
return ctx.Send(&query.Result{
Messages: messages,
Series: []*models.Row{
{
Name: "result",
Columns: []string{"time", "written"},
Values: [][]interface{}{
{time.Unix(0, 0).UTC(), writeN}},
}},
})
}
// Always emit at least one result.
if !emitted {
return ctx.Send(&query.Result{
Series: make([]*models.Row, 0),
})
}
return nil
}
func (e *StatementExecutor) writeInto(w pointsWriter, stmt *influxql.SelectStatement, row *models.Row) (n int64, err error) {
if stmt.Target.Measurement.Database == "" {
return 0, errNoDatabaseInTarget
}
// It might seem a bit weird that this is where we do this, since we will have to
// convert rows back to points. The Executors (both aggregate and raw) are complex
// enough that changing them to write back to the DB is going to be clumsy
//
// it might seem weird to have the write be in the Executor, but the interweaving of
// limitedRowWriter and ExecuteAggregate/Raw makes it ridiculously hard to make sure that the
// results will be the same as when queried normally.
name := stmt.Target.Measurement.Name
if name == "" {
name = row.Name
}
points, err := convertRowToPoints(name, row)
if err != nil {
return 0, err
}
if err := w.WritePointsInto(&IntoWriteRequest{
Database: stmt.Target.Measurement.Database,
RetentionPolicy: stmt.Target.Measurement.RetentionPolicy,
Points: points,
}); err != nil {
return 0, err
}
return int64(len(points)), nil
}
// writeToShards writes points to a shard and ensures a write consistency level has been met. If the write
// partially succeeds, ErrPartialWrite is returned.
func (w *PointsWriter) writeToShard(shard *meta.ShardInfo, database, retentionPolicy string,
consistency ConsistencyLevel, points []models.Point) error {
atomic.AddInt64(&w.stats.PointWriteReqLocal, int64(len(points)))
// The required number of writes to achieve the requested consistency level
required := len(shard.Owners)
switch consistency {
case ConsistencyLevelAny, ConsistencyLevelOne:
required = 1
case ConsistencyLevelQuorum:
required = required/2 + 1
}
// response channel for each shard writer go routine
type AsyncWriteResult struct {
Owner meta.ShardOwner
Err error
}
ch := make(chan *AsyncWriteResult, len(shard.Owners))
for _, owner := range shard.Owners {
go func(shardID uint64, owner meta.ShardOwner, points []models.Point) {
if w.Node.ID == owner.NodeID {
atomic.AddInt64(&w.stats.PointWriteReqLocal, int64(len(points)))
err := w.TSDBStore.WriteToShard(shardID, points)
// If we've written to shard that should exist on the current node, but the store has
// not actually created this shard, tell it to create it and retry the write
if err == tsdb.ErrShardNotFound {
err = w.TSDBStore.CreateShard(database, retentionPolicy, shardID, true)
if err != nil {
ch <- &AsyncWriteResult{owner, err}
return
}
err = w.TSDBStore.WriteToShard(shardID, points)
}
ch <- &AsyncWriteResult{owner, err}
return
}
atomic.AddInt64(&w.stats.PointWriteReqRemote, int64(len(points)))
err := w.ShardWriter.WriteShard(shardID, owner.NodeID, points)
if err != nil && tsdb.IsRetryable(err) {
// The remote write failed so queue it via hinted handoff
atomic.AddInt64(&w.stats.WritePointReqHH, int64(len(points)))
hherr := w.HintedHandoff.WriteShard(shardID, owner.NodeID, points)
if hherr != nil {
ch <- &AsyncWriteResult{owner, hherr}
return
}
// If the write consistency level is ANY, then a successful hinted handoff can
// be considered a successful write so send nil to the response channel
// otherwise, let the original error propagate to the response channel
if hherr == nil && consistency == ConsistencyLevelAny {
ch <- &AsyncWriteResult{owner, nil}
return
}
}
ch <- &AsyncWriteResult{owner, err}
}(shard.ID, owner, points)
}
var wrote int
timeout := time.After(w.WriteTimeout)
var writeError error
for range shard.Owners {
select {
case <-w.closing:
return ErrWriteFailed
case <-timeout:
atomic.AddInt64(&w.stats.WriteTimeout, 1)
// return timeout error to caller
return ErrTimeout
case result := <-ch:
// If the write returned an error, continue to the next response
if result.Err != nil {
atomic.AddInt64(&w.stats.WriteErr, 1)
w.Logger.Info("write failed", zap.Uint64("shard", shard.ID), zap.Uint64("node", result.Owner.NodeID), zap.Error(result.Err))
// Keep track of the first error we see to return back to the client
if writeError == nil {
writeError = result.Err
}
continue
}
wrote++
// We wrote the required consistency level
if wrote >= required {
atomic.AddInt64(&w.stats.WriteOK, 1)
return nil
}
}
}
if wrote > 0 {
atomic.AddInt64(&w.stats.WritePartial, 1)
return ErrPartialWrite
}
if writeError != nil {
return fmt.Errorf("write failed: %v", writeError)
}
return ErrWriteFailed
}
边栏推荐
- 剑指 Offer 14- II. 剪绳子 II
- 01 three solutions to knapsack problem (greedy dynamic programming branch gauge)
- [exercice 7] [principe de la base de données]
- [comprehensive question] [Database Principle]
- 【数据库原理及应用教程(第4版|微课版)陈志泊】【第六章习题】
- 【R】【密度聚类、层次聚类、期望最大化聚类】
- How to get user location in wechat applet?
- 剑指 Offer 14- I. 剪绳子
- 对业务的一些思考
- 2022-01-27 redis cluster technology research
猜你喜欢
【计网】第三章 数据链路层(2)流量控制与可靠传输、停止等待协议、后退N帧协议(GBN)、选择重传协议(SR)

Sitescms v3.1.0 release, launch wechat applet
Some thoughts on business

【R】【密度聚类、层次聚类、期望最大化聚类】
Method overloading and rewriting
The latest version of lottery blind box operation version
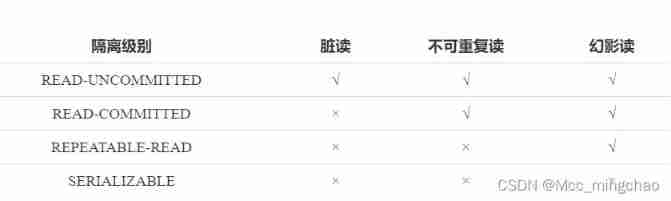
Four problems and isolation level of MySQL concurrency

Swift bit operation exercise
![[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter III exercises]](/img/b4/3442c62586306b4fceca992ce6294a.png)
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter III exercises]

Xctf mobile--app3 problem solving
随机推荐
Attack and defense world mobile--ph0en1x-100
How to stand out quickly when you are new to the workplace?
Logback 日志框架
C graphical tutorial (Fourth Edition)_ Chapter 13 entrustment: delegatesamplep245
C graphical tutorial (Fourth Edition)_ Chapter 20 asynchronous programming: examples - cases without asynchronous
2022-01-27 research on the minimum number of redis partitions
Leetcode234 palindrome linked list
C graphical tutorial (Fourth Edition)_ Chapter 17 generic: genericsamplep315
Grid connection - Analysis of low voltage ride through and island coexistence
Cache penetration and bloom filter
Simple use and precautions of kotlin's array array and set list
【Colab】【使用外部数据的7种方法】
SSH login server sends a reminder
【習題七】【數據庫原理】
【习题六】【数据库原理】
Seven second order ladrc-pll structure design of active disturbance rejection controller
2022-01-27 use liquibase to manage MySQL execution version
关于CPU缓冲行的理解
elk笔记24--用gohangout替代logstash消费日志
CVPR 2022 图像恢复论文