当前位置:网站首页>Literature reading ten - Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learn
Literature reading ten - Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learn
2022-08-04 23:06:00 【White river small _ _】
系列文章目录
- 谣言检测文献阅读一—A Review on Rumour Prediction and Veracity Assessment in Online Social Network
- 谣言检测文献阅读二—Earlier detection of rumors in online social networks using certainty‑factor‑based convolutional neural networks
- 谣言检测文献阅读三—The Future of False Information Detection on Social Media:New Perspectives and Trends
- 谣言检测文献阅读四—Reply-Aided Detection of Misinformation via Bayesian Deep Learning
- 谣言检测文献阅读五—Leveraging the Implicit Structure within Social Media for Emergent Rumor Detection
- 谣言检测文献阅读六—Tracing Fake-News Footprints: Characterizing Social Media Messages by How They Propagate
- 谣言检测文献阅读七—EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
- 谣言检测文献阅读八—Detecting breaking news rumors of emerging topics in social media
- 谣言检测文献阅读九—人工智能视角下的在线社交网络虚假信息 检测、传播与控制研究综述
- Literature reading ten——Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learn
文章目录
前言
文章:Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learning
发表会议:The Web Conference 2019 - Proceedings of the World Wide Web Conference, WWW 2019 (A 类会议论文)
时间:2019年
摘要
分析表明,The proliferation of rumours is often the result of deliberately promoted information campaigns,The aim is to shape collective opinions about the related news and events.在本文中,We try to fight this chaos with ourselves,Making automatic rumor detection more robust and effective.Our idea is inspired by Generative Adversarial Networks(GAN)Inspired by adversarial learning methods.我们提出了一种GAN式的方法,i.e. designing a generator to generate uncertain or conflicting sounds,Complicates the original conversation thread,in order to put pressure on the discriminator,make it from enhanced、Learn stronger rumor-indicative representations from more challenging examples.Compared with traditional data-driven rumor detection methods(深度学习方法)不同,Our method can capture low-frequency but stronger extraordinary patterns through this adversarial training(non-trivial).在两个TwitterExtensive experiments on benchmark datasets show that,我们的谣言检测方法比最先进的方法取得了更好的结果.
1 介绍
Disinformation campaigners often conduct information campaigns through social networks,Promote controversial memes(meme)、虚假新闻等
注:meme 模因:elements of a cultural or behavioral system,by non-genetic means(especially imitation)spread among people
然而,Existing data-driven approaches often rely on finding indicative responses,such as doubts and disagreements to detect.Rumor makers can use propaganda campaigns to sway public opinion( entangle public opinions)or influence collective positions,to be widely disseminated and expanded.The data driven method is put forward the major technical challenges,Because text patterns and other explicit features become indistinguishable.The coexistence of various conflicting and uncertain voices can seriously interfere with the learning of useful features(或提取).图1shows an about“Saudi Arabia Beheads First Female Robot Citizen”Rumours of a campaign,Demonstrates popular indicating patterns of doubt and disagreement,如“假新闻”、“不确定”、“没有真相”How it got inundated with propaganda posts.因此,There is an urgent need to develop a more powerful feature learner for rumor detection.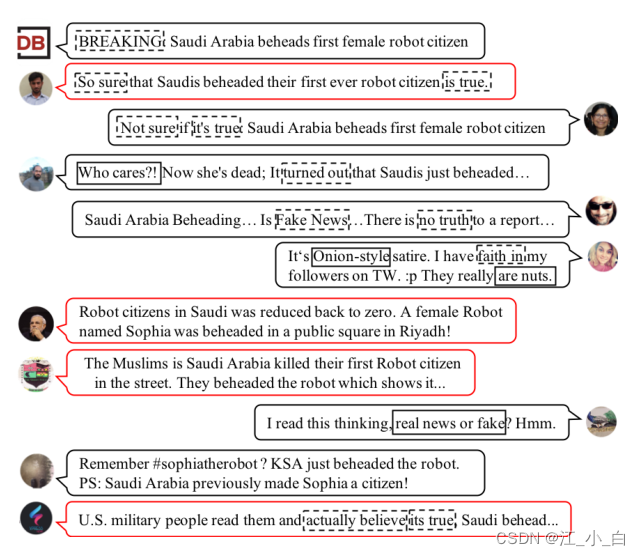 图1:in a publicity campaign,对关于“Saudi Arabia beheads its first female robot citizen”Sample responses to rumors of.Social bot activity is marked with a red box.Supportive responses are listed on the left,Denial is listed on the right(或不确定)反应.Patterns captured by existing methods are marked with dashed rectangles,Potentially missing patterns are marked with solid rectangles.
图1:in a publicity campaign,对关于“Saudi Arabia beheads its first female robot citizen”Sample responses to rumors of.Social bot activity is marked with a red box.Supportive responses are listed on the left,Denial is listed on the right(或不确定)反应.Patterns captured by existing methods are marked with dashed rectangles,Potentially missing patterns are marked with solid rectangles.
在本文中,We propose a novel rumor detection method using the information movement mechanism and generalize it in a controllable manner,for a more robust、more efficient detection.Our seemingly counterintuitive idea was inspired by Generative Adversarial Networks or known as GAN,where the discriminative classifier learns to distinguish whether an instance comes from the real world,and train the generative model,Confuse the discriminator by generating near-real examples.
We do it by parodying the campaign,Including misleading grassroots conversations with uncertain and conflicting voices(grassroots conversations),Train the generator to output challenging examples,thereby driving our discriminator to enhance feature learning from such difficult examples,to capture more discriminative patterns.
直观地说,why such aGANStyle-based methods do better at feature learning?如图1所示,Various user engagements can easily break the data-driven approach of the past,These methods usually employ a repeating pattern when responding to a post.due to activities,frequently in response to rumors“假新闻”或“不真实”and other high-frequency patterns and in non-rumoured responses“真实/确定”etc. High frequency patterns become less discriminative.因此,Discrimination is adaptively adjusted to focus on capturing relatively low frequency mode,如 "洋葱式 “(onion-style)和 “Nuts type(be nuts 傻里傻气)”,These patterns are as important as high frequency mode,However, it is ignored in the existing feature learning methods..(As a result, the discriminator is adjusted adaptively to focus on capturing the relatively low-frequency patterns, such as “onion-style” and “be nuts”, which are expected non-trivial as high-frequency ones while used to be ignored in existing feature learning methods)In order to preserve the discriminative power of the original high frequency patterns,We use the generated similar movement of the examples and original example in strengthen the training on the training data of discrimination.
创新点:
- 据我们所知,This is the first text-basedGANA Generative Method for Rumor Detection Using a Style Framework,在这种框架中,We make the text generator and the discriminator enhance each other,Representation Learning to Enhance Rumor Indication Patterns.
- We model rumor propagation as a generative information campaign,For generating confusing training examples,The detection ability of the discriminator challenge.
- 在 GAN framed by style,We strengthen our discriminator,It is trained on a set of more challenging examples supplemented by the generator,Focus on learning low frequency but discriminating patterns.
- 我们通过实验证明,Than our model based on two public benchmark data sets of the most advanced baseline is more powerful and effective,用于 Twitter rumor detection task on.
2 问题陈述
For reliable feature extraction,在 Twitter rumor detection task,Claims usually consist of a set of posts related to the claim(即推文)表示,These posts can be accessed through Twitter The search function of the collection.We denote the rumor dataset as X {X} X,其中每个 X = ( y , x 1 x 2 . . . x T ) X = (y, x_1x_2 ... x_T ) X=(y,x1x2...xT) is a tuple representing the given declaration:X by real labels y ∈ {N , R} Composition Statement(Namely the rumor or rumors)and a series of related posts x 1 , x 2 . . . x T x_1,x_2 . .. x_T x1,x2...xT ,其中每个 x t x_t xt Can represent a single post or more generally a batch of posts within a time interval,and in time steps t 进行索引.因此,Claims can be thought of as a time series of related posts.为清楚起见,我们将实例(声明)X 写为 X y X_y Xy,即 X R X_R XR to express a rumour, X N X_N XN express non-rumour.
emsp;Information activity challenges existing rumor detection models,Because frequent patterns indicating authenticity become distorted and misleading.Our basic idea is to enhance representation learning of rumor-indicative features inspired by generative adversarial learning mechanisms.我们提出了一个 GAN 风格的模型,where the generator tries to boost activity by generating hard examples,Whereas the discriminator aims to identify robust features to overcome the difficulties brought by the generator.Against recent event adversarial models for multimodal fake news detection [18] and a neural user response generator for early detection [16] 不同,Our thinking and the mechanics we employ are very different.
3 Generative Adversarial Learning for Rumor Detection
3.1 Controversial example generation
Our generative model aims to generate uncertain or conflicting voices for a given claim,thereby making it harder to distinguish rumors from non-rumors that used to rely on repeating patterns.
A straightforward approach is to distort or complicate the views expressed in the raw data examples through some regular templates.例如,我们可以
- 将“真的吗?”、“是真的吗?”、“不确定”And ask express joining in to reply to posts;
- 通过在“be”add after verb“not”To deny the post position;
- Apply antonym substitution to certain parts of a keyword,例如,用“真”代替“假”,用“错”代替“对”等.但是,It is difficult to generalize these rules to formally generate any controversial voices.A general approach is to convert our generator into a trainable model,The model can cover various expression changes.
注:These methods are to change the original meaning,We can study methods to attack without changing the original intention(not found how to say)或者减少“噪声”
为此,We designed two generators,one used to twist a non-rumour to look like a rumour,另一个用于“粉饰”Rumor makes it seem like a non-rumor: 1) G N → R G_N→R GN→R Voices of doubt or disapproval of non-rumor claims; 2) G R → N G_R→N GR→N Generate voices in support of rumors.我们定义了一个函数 f g f_g fg To make our generation model: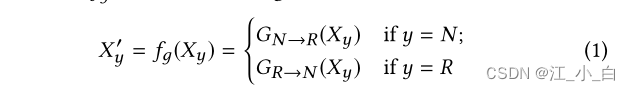 其中 X y X_y Xy is the original instance from the training set,Can be rumour or non-rumour, X y ′ X'_y Xy′is a transform instance with a generator,while the label remains the same.
其中 X y X_y Xy is the original instance from the training set,Can be rumour or non-rumour, X y ′ X'_y Xy′is a transform instance with a generator,while the label remains the same.
Considering the time series of posts in each instance,We use a sequence to sequence model [11, 17] make a build transformation,如图 2 所示.我们通过 RNN 将输入序列 X y X_y Xy Encode as hidden vector encoder,然后通过 RNN The decoder generates the transformed sequence from X y ′ X'_y Xy′.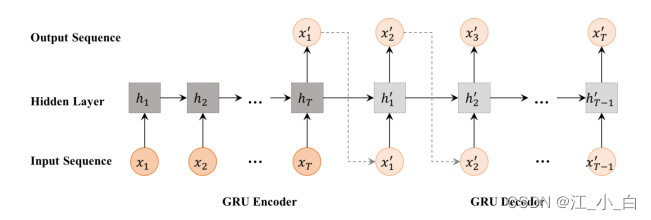 GRU-RNN 编码器: 我们按照 [12] Similar time splitting described in batches related posts into time intervals,and treat each batch as a unit in the time series.使用 RNN,We will each input cell x t ∈ X y x_t ∈ X_y xt∈Xy map to a hidden vector h t h_t ht中,我们使用 GRU [4] to store the hidden representation:
GRU-RNN 编码器: 我们按照 [12] Similar time splitting described in batches related posts into time intervals,and treat each batch as a unit in the time series.使用 RNN,We will each input cell x t ∈ X y x_t ∈ X_y xt∈Xy map to a hidden vector h t h_t ht中,我们使用 GRU [4] to store the hidden representation: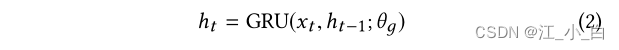 x t x_t xt Is represented as from falling into the first t Vocabulary words calculated for posts at time steps tf*idf input cell of a vector of values, h t − 1 h_{t-1} ht−1 Refers to the previous hidden state, 和 θ g θ_g θg 表示 GRU 的所有参数.GRU-RNN The last time step of the encoder h T h_T hT 的输出是 X y X_y Xy 的隐藏表示
x t x_t xt Is represented as from falling into the first t Vocabulary words calculated for posts at time steps tf*idf input cell of a vector of values, h t − 1 h_{t-1} ht−1 Refers to the previous hidden state, 和 θ g θ_g θg 表示 GRU 的所有参数.GRU-RNN The last time step of the encoder h T h_T hT 的输出是 X y X_y Xy 的隐藏表示
GRU-RNN解码器: Each unit usesGRU和softmaxThe output function is sequentially generated(each unit is sequentially generated using GRU followed by a softmax output function).在每个步骤t中,softmaxThe output layer calculates the distribution of vocabulary words by,将通过GRUobtained hidden state h ′ t h′_t h′tMapped to a batchPOSTtarget representation x ′ t + 1 x′_{t+1} x′t+1
构建one-hot词汇表(5000),然后根据softmaxCalculate the maximum probability,Find the converted word
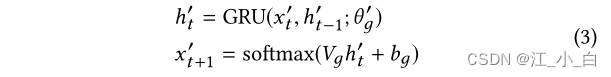 其中 h ′ t − 1 h′_{t−1} h′t−1是GRUThe previous hidden state of the decoder, θ ′ g θ′_g θ′g表示GRU2内的所有参数, V g V_g Vg和 b g b_g bgare the trainable parameters of the output layer.
其中 h ′ t − 1 h′_{t−1} h′t−1是GRUThe previous hidden state of the decoder, θ ′ g θ′_g θ′g表示GRU2内的所有参数, V g V_g Vg和 b g b_g bgare the trainable parameters of the output layer.
3.2 GANadversarial learning model
在这个编码器-解码器框架中, f g ( X y ) f_g(X_y) fg(Xy)Defines the generated controversial posts on behalf of the strategy,These posts are used to obfuscate based on input X y X_y Xy的判别器的.A key question is how to control the generator to generate the desired.为此,We use the performance of the discriminator as a reward to guide the generator.Before introducing the discriminator,Let us introduce ourGANStructure and Control Mechanisms of the Formula Model,如图3所示,It consists of an adversarial learning module and two reconstruction modules(one for rumors,another for non-rumours)组成.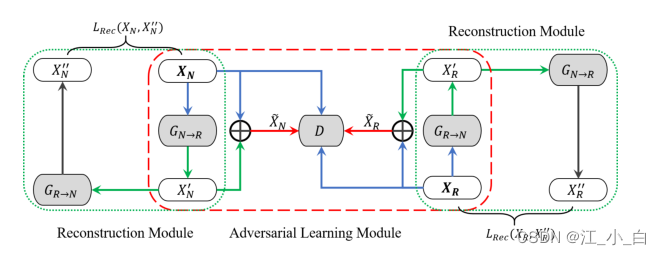 图3:我们的GANOverview of the Rumor Detection Model. G N → R G_N→R GN→R(或 G R → N G_R→N GR→N)是一个生成器.D表示判别器
图3:我们的GANOverview of the Rumor Detection Model. G N → R G_N→R GN→R(或 G R → N G_R→N GR→N)是一个生成器.D表示判别器
Adversarial Learning Module: 在我们的模型中,Encourage the generator to produce motion-like instances to fool the discriminator,This allows the discriminator to focus on learning more discriminative features.Such an objective suggests that the training objective is similar to adversarial learning.We formulate the adversarial loss as the negative of the discriminator loss based on the training data augmented by the generator.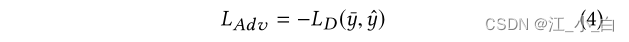 其中, L D ( − ) L_D(-) LD(−)is the true class probability distribution y ˉ \bar{y} yˉClass distribution with discriminator predictions y ^ \hat{y} y^之间的损失( L D ( − ) L_D(-) LD(−)For the specific form, see the formula11).
其中, L D ( − ) L_D(-) LD(−)is the true class probability distribution y ˉ \bar{y} yˉClass distribution with discriminator predictions y ^ \hat{y} y^之间的损失( L D ( − ) L_D(-) LD(−)For the specific form, see the formula11).
We combine the generated example with the original example,By taking their and set( X ~ y ⋃ X y \tilde{X}_y\bigcup X_y X~y⋃Xy)来扩充训练集,其中 X ~ y = X y ⊕ X y ′ \tilde{X}_y=X_y⊕ X'_y X~y=Xy⊕Xy′is the element-wise addition of the original example and the generated example.注意,Elemental addition has the effect of canceling out influential high frequency patterns,and improve the chances of important low frequency modes being selected.同时,We didn't want to seriously cripple these useful features in the original example.因此,如图3所示,original example X y X_y Xy与 X ~ y \tilde{X}_y X~ycombination for training.
重建模块: The generator may change some fundamental aspects of the story by changing,Distort the original example into an unexpected orientation.例如,“Saudi beheads robot citizen”the subject may be distorted into“Saudi Arabia digs canal for Qatar”,it's irrelevant,also does not help.为了避免这种情况,We introduced a refactoring mechanism,To generate a reversible process.其思想是,Via two generators in opposite directions,voice of opinion(opinionated voices)将是可逆的,to minimize loss of information fidelity.We define the reconstruction function as follows: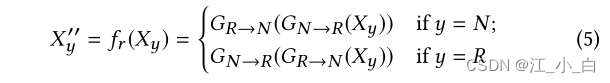 其中 X y ′ ′ X''_y Xy′′is generated from the original instance via two opposite generators X y X_y Xy Rebuilt instance.我们将 X y ′ ′ X''_y Xy′′和 X y X_y XyThe difference between is denoted as reconstruction loss:
其中 X y ′ ′ X''_y Xy′′is generated from the original instance via two opposite generators X y X_y Xy Rebuilt instance.我们将 X y ′ ′ X''_y Xy′′和 X y X_y XyThe difference between is denoted as reconstruction loss: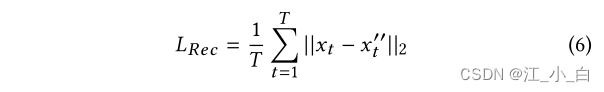 ∣ ∣ ⋅ ∣ ∣ 2 || · ||_2 ∣∣⋅∣∣2 是向量的 L2 范数.
∣ ∣ ⋅ ∣ ∣ 2 || · ||_2 ∣∣⋅∣∣2 是向量的 L2 范数.
优化目标: 我们的GANThe overall loss function is defined as type against learning L A d v L_{Adv} LAdv和 L R e c L_{Rec} LRec的线性插值: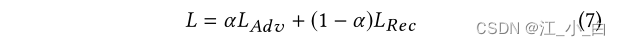 其中αis the trade-off factor between adversarial loss and reconstruction loss.The objective of adversarial learning adopts the minimum-The biggest form:
其中αis the trade-off factor between adversarial loss and reconstruction loss.The objective of adversarial learning adopts the minimum-The biggest form: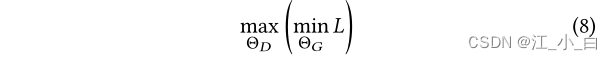 其中, Θ G = { θ k , θ ′ k , V k , b k } Θ_G=\{θ_k,θ′_k,V_k,b_k\} ΘG={ θk,θ′k,Vk,bk}是生成器的参数, Θ D Θ_D ΘDare the parameters of the discriminator,将在下一节中详细介绍.在最小-during maximum process,We first by minimizing against losses L A d v L_{Adv} LAdv(The biggest loss discriminator L D L_D LD)and reconstruction loss L R e c L_{Rec} LRec来优化 Θ G Θ_G ΘG,to generate confusing but reversible examples;然后,We maximize the adversarial loss by L A d v L_{Adv} LAdv(i.e. minimize the discriminator loss L D L_D LD)Optimizing discriminator parameters for classification Θ D Θ_D ΘD,并注意到 L R e c L_{Rec} LRec独立于 Θ D Θ_D ΘD.
其中, Θ G = { θ k , θ ′ k , V k , b k } Θ_G=\{θ_k,θ′_k,V_k,b_k\} ΘG={ θk,θ′k,Vk,bk}是生成器的参数, Θ D Θ_D ΘDare the parameters of the discriminator,将在下一节中详细介绍.在最小-during maximum process,We first by minimizing against losses L A d v L_{Adv} LAdv(The biggest loss discriminator L D L_D LD)and reconstruction loss L R e c L_{Rec} LRec来优化 Θ G Θ_G ΘG,to generate confusing but reversible examples;然后,We maximize the adversarial loss by L A d v L_{Adv} LAdv(i.e. minimize the discriminator loss L D L_D LD)Optimizing discriminator parameters for classification Θ D Θ_D ΘD,并注意到 L R e c L_{Rec} LRec独立于 Θ D Θ_D ΘD.
3.3 rumor discriminator
我们基于RNNRumor detection model(马静 2016)built the discriminator.给定一个实例(The original or generated),RNN模型首先使用GRU将第tstep related posts x t x_t xtMapped to the hidden vector s t s_t st: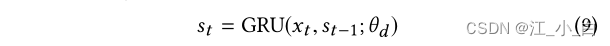 然后输入到softmaxClassify instances in layers:
然后输入到softmaxClassify instances in layers: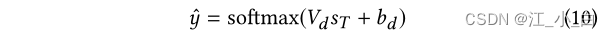 其中 y ^ \hat{y} y^is a vector of predicted probabilities over two classes, V d V_d Vd是输出层的权重矩阵, b d b_d bdis the trainable bias.
其中 y ^ \hat{y} y^is a vector of predicted probabilities over two classes, V d V_d Vd是输出层的权重矩阵, b d b_d bdis the trainable bias.
The loss of the discriminator is defined as the squared error between the predicted class and the true class distribution: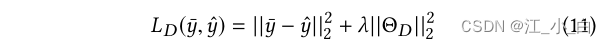 其中 y ˉ \bar{y} yˉ 和 y ^ \hat{y} y^are the true and predicted class probability distributions, respectively, Θ D = { θ d , V d , b d } Θ_D =\{θ_d ,V_d ,b_d\} ΘD={ θd,Vd,bd} 是判别器参数,λ 是权衡系数.
其中 y ˉ \bar{y} yˉ 和 y ^ \hat{y} y^are the true and predicted class probability distributions, respectively, Θ D = { θ d , V d , b d } Θ_D =\{θ_d ,V_d ,b_d\} ΘD={ θd,Vd,bd} 是判别器参数,λ 是权衡系数.
3.4 Generative Adversarial Training Algorithms
算法 1 展示了我们的 GAN Iterative training process of generator and discriminator in the style framework.with the original used to get a better generator GAN不同,Our goal is to enhance the discriminator to make it more discriminative and generalizable. Generator and discriminator are trained decently alternately using stochastic gradients in mini-batches.在每个 epoch 中,Both generate controversial examples and augment them with the original training data.我们用公式8Optimize the generator and discriminator,The formula passes the algorithm1中的步骤8-11执行最小-最大博弈.
Generator and discriminator are trained decently alternately using stochastic gradients in mini-batches.在每个 epoch 中,Both generate controversial examples and augment them with the original training data.我们用公式8Optimize the generator and discriminator,The formula passes the algorithm1中的步骤8-11执行最小-最大博弈.
在训练中,We initialize the model parameters with a uniform distribution;We train iteratively,直到达到最大 epoch 数,设置为 200;We fix the vocabulary size as 5,000,The size of the hidden vector is 100,and tune hyperparameters using holdout dataset α、λ 和 ε.
边栏推荐
猜你喜欢
【字符串函数内功修炼】strcpy + strcat + strcmp(一)
C5750X7R2E105K230KA(电容器)MSP430F5249IRGCR微控制器资料
【3D建模制作技巧分享】在zbrush中如何雕刻头发 ZBrush头发雕刻小技巧
PHP(3)
2022年全网最全接口自动化测试框架搭建,没有之一
If you can't get your heart, use "distributed lock" to lock your people

各行各业都受到重创,游戏行业却如火如荼,如何加入游戏模型师职业
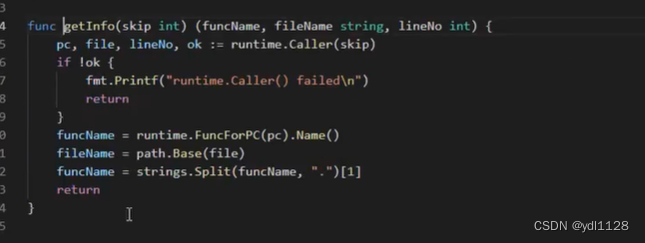
go语言的日志实现(打印日志、日志写入文件、日志切割)
956. 最高的广告牌
407. 接雨水 II
随机推荐
typeScript-部分应用函数
【3D建模制作技巧分享】ZBrush如何重新拓扑
一点点读懂cpufreq(一)
特征工程资料汇总
仪表板展示 | DataEase看中国:数据呈现中国资本市场
【游戏建模模型制作全流程】ZBrush蜥蜴模型雕刻教程
智慧养老整体解决方案
ClickHouse 二级索引
Pytest学习-Fixture
Service Mesh落地路径
407. 接雨水 II
【3D建模制作技巧分享】ZBrush纹理贴图怎么导入
go语言的time包介绍
The Record of Reminding myself
Go 编程语言(简介)
Service Mesh落地路径
学生管理系统架构设计
Use ngrok to optimize web pages on raspberry pi (1)
The Controller layer code is written like this, concise and elegant!
视频gif如何制作?试试这个视频制作gif神器