当前位置:网站首页>[Paper Notes KDD2021] MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems
[Paper Notes KDD2021] MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems
2022-08-04 22:36:00 【mountain top sunset】
学习总结
零、论文简介
论文题目:MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems
论文链接:http://keg.cs.tsinghua.edu.cn/jietang/publications/KDD21-Huang-et-al-MixGCF.pdf
论文代码:https://github.com/huangtinglin/MixGCF
论文作者:Tinglin Huang,Teacher Tang Jie and others
一、Introduction
导言:GNN被广泛应用于embeddinggenerated scene,对user和item分别进行embedding化,使用双塔模型;类似像Graphsage、PinSage、LightGCNAlgorithms such as these have also been used in recommender systems in the industry,但是GNNThe negative sampling technique is still to be studied,Most algorithms in the past select negative samples from real data,而忽略了embedding的信息,而MixGCFis data augmented、Aggregate methods obtain negative samples and their representations.NGCF和LightGCN在使用MixGCF后,在NDCG指标上分别提高了26%和22%.
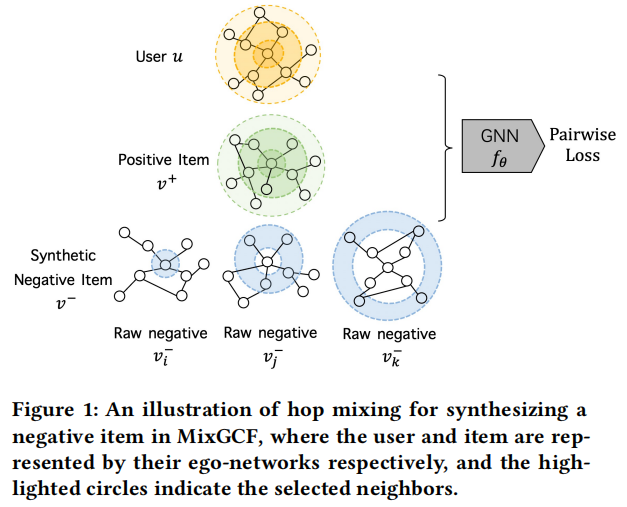
1.1 聚合 Aggregation
聚合过程: e u ( l + 1 ) = ∑ i ∈ N u 1 ∣ N u ∣ ∣ N i ∣ e i ( l ) , e v ( l + 1 ) = ∑ j ∈ N v 1 ∣ N v ∥ N j ∣ e j ( l ) \mathbf{e}_{u}^{(l+1)}=\sum_{i \in N_{u}} \frac{1}{\sqrt{\left|N_{u}\right|\left|N_{i}\right|}} \mathbf{e}_{i}^{(l)}, \mathbf{e}_{v}^{(l+1)}=\sum_{j \in N_{v}} \frac{1}{\sqrt{\left|N_{v} \| N_{j}\right|}} \mathbf{e}_{j}^{(l)} eu(l+1)=i∈Nu∑∣Nu∣∣Ni∣1ei(l),ev(l+1)=j∈Nv∑∣Nv∥Nj∣1ej(l)
1.2 池化过程
池化过程: e u ∗ = ∑ l = 0 L λ l e u ( l ) , e v ∗ = ∑ l = 0 L λ l e v ( l ) \mathbf{e}_{u}^{*}=\sum_{l=0}^{L} \lambda_{l} \mathbf{e}_{u}^{(l)}, \mathbf{e}_{v}^{*}=\sum_{l=0}^{L} \lambda_{l} \mathbf{e}_{v}^{(l)} eu∗=l=0∑Lλleu(l),ev∗=l=0∑Lλlev(l)
1.3 Negative sampling optimization
一般LTRThe loss function for the task is BPR loss: max ∏ v + , v − ∼ f S ( u ) P u ( v + > v − ∣ Θ ) \max \prod_{v^{+}, v^{-} \sim f_{S}(u)} P_{u}\left(v^{+}>v^{-} \mid \Theta\right) maxv+,v−∼fS(u)∏Pu(v+>v−∣Θ)
其中参数:
- v + v^{+} v+和 v − v^{}- v−分别表示positive items和negative items
- P u ( a > b ) P_{u}(a>b) Pu(a>b)表示用户u,相比于item b来说,more preferreditem a
- f S ( u ) f_{S}(u) fS(u)是negative sampling的分布,Many recommendation algorithms(如LightGCN、NCF、BPR、NGCF等算法)都是将negative sample服从于uniform均匀分布( f S ( u ) = f uniform ( u ) f_{S}(u)=f_{\text {uniform }}(u) fS(u)=funiform (u))
1.4 Negative sampling problem
- 经典的BPR loss栗子.
- Negative sampling is generally useduniform distribution,为了改进GNN的负采样:
- PinSage根据PageRankThe score is negatively sampled;
- MCNConsider the structural correlation between positive and negative samples,Re-involved the distribution of positive and negative samples;
- But these algorithms are only mainly indiscrete graph space中负采样,而忽略了GNN在embeddingA unique neighbor aggregation process in space.
- MixGCFSubject to data augmentation and metric learningthought proposed,进行hard负样本的生成.
二、MixGCF算法
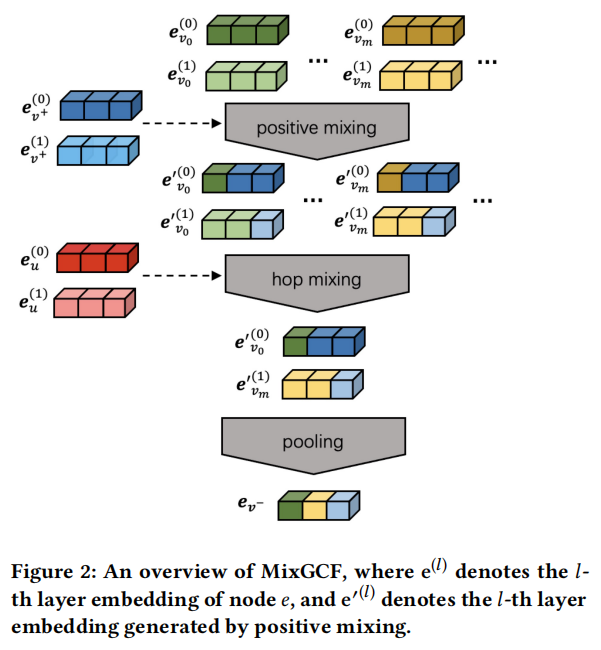
2.1 positive mixing
positive mixing的操作: e v m ′ ( l ) = α ( l ) e v + ( l ) + ( 1 − α ( l ) ) e v m ( l ) , α ( l ) ∈ ( 0 , 1 ) \mathbf{e}_{v_{m}}^{\prime(l)}=\alpha^{(l)} \mathbf{e}_{v^{+}}^{(l)}+\left(1-\alpha^{(l)}\right) \mathbf{e}_{v_{m}}^{(l)}, \alpha^{(l)} \in(0,1) evm′(l)=α(l)ev+(l)+(1−α(l))evm(l),α(l)∈(0,1)
其中参数:
- α ( l ) \alpha^{(l)} α(l)是每一个hopuniformly sampledmixing因子;
- mixup的mixingfactor is frombeta分布 Beta ( β , β ) \operatorname{Beta}(\beta, \beta) Beta(β,β)sampled from,It has a great impact on the generalization ability of the model;
- In order to alleviate this effect mentioned above,positive mixing中的mixing因子 α ( l ) \alpha^{(l)} α(l)统一从(0, 1)sampling from the distribution;
- E ′ \mathcal{E}^{\prime} E′是候选negatives M增强后的embedding集合.
positive mixing增强negatives通过以下两种方式:
1)把positive information注射到negative samples,This helps to force the optimization algorithm to work harder、More aggressive use of decision boundaries.
2)用mixingFactors introduce random uncertainty into them.
2.2 Hop Mixing

2.3 optimization with MixGCF
L B P R = ∑ ( u , v + ) ∈ O + e v − ∼ f M i x G C F ( u , v + ) ln σ ( e u ⋅ e v − − e u ⋅ e v + ) \mathcal{L}_{\mathrm{BPR}}=\sum_{\substack{\left(u, v^{+}\right) \in O^{+} \\ \mathbf{e}_{v^{-}} \sim f_{\mathrm{MixGCF}}\left(u, v^{+}\right)}} \ln \sigma\left(\mathbf{e}_{u} \cdot \mathbf{e}_{v^{-}}-\mathbf{e}_{u} \cdot \mathbf{e}_{v^{+}}\right) LBPR=(u,v+)∈O+ev−∼fMixGCF(u,v+)∑lnσ(eu⋅ev−−eu⋅ev+)
2.4 关于MixGCF的相关讨论
2.5 时间复杂度
三、实验环节
3.1 experimental settings
(1)评估指标
(2)推荐算法模型
(3)Baselines
(4)超参数设置
3.2 Performance comparison
实验结果对比: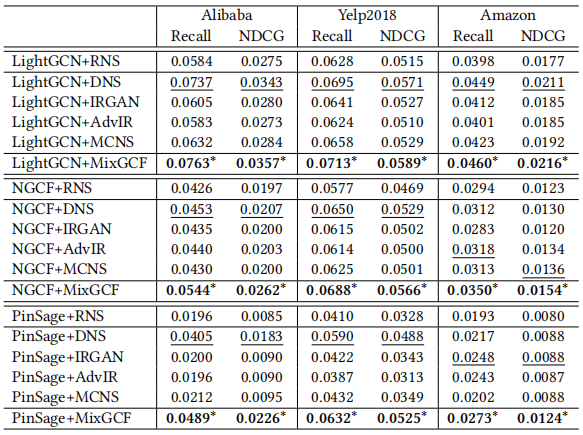
(1)running time
(2)running time
四、相关工作
4.1 基于GNN的推荐算法
- PinSage、GC-MC、NGCF、LightGCN
- 利用side info:社交网络、知识图谱 …
4.2 推荐系统中的负采样
- Static Sampler Negative sampling from a fixed distribution
- 均匀分布、流行度 指数 3/4
- GAN-based Sampler Negative sampling based on generative adversarial networks
- IRGAN、KBGAN、AdvIR
- Hard Negative Sampler Adaptively selected for the current user hardest 负样本
- DNS
- Graph-based Sampler Negative sampling based on graph information
- MCNS、KGPolicy、PinSage(基于Personalized PageRank)
Reference
[1] http://keg.cs.tsinghua.edu.cn/jietang/publications/KDD21-Huang-et-al-MixGCF.pdf
[2] https://huangtinglin.github.io/experience/
[3] Bayesian Personalized Sorting AlgorithmBPR
边栏推荐
- SQL Server calls WebService
- 历史上的今天:PHP公开发布;iPhone 4 问世;万维网之父诞生
- rk3399-9.0一级二级休眠
- MQTT[一]基础知识介绍
- rk3399-0.0 svc command
- 【3D建模制作技巧分享】ZBrush模型如何添加不同材质
- js中小数四则运算精度问题原因及解决办法
- How to make a video gif?Try this video making gif artifact
- JVM memory configuration parameter GC log
- If you can't get your heart, use "distributed lock" to lock your people
猜你喜欢

逆序对的数量
SRv6网络的安全解决方案
正则表达式绕过
3D激光SLAM:LeGO-LOAM---两步优化的帧间里程计及代码分析
rk3399 驱动屏参的几种方式

Open source summer | Cloud server ECS installs Mysql, JDK, RocketMQ

FinClip崁入式搭建生态平台,降低合作门槛
【论文笔记KDD2021】MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems

the warmest home

【社媒营销】WhatsApp Business API:您需要知道的一切
随机推荐
遍历await方法的区别:以for和forEach为例
VSCode - common shortcut keys (continuous recording
good luck
双非读者,一举拿下阿里、字节、美团、京东、虾皮offer
一招包治pycharm DEBUG报错 UnicodeDecodeError: ‘utf-8‘ codec can‘t decode
使用cpolar优化树莓派上的网页(2)
直播带货为农产品开拓销售渠道
How to right use of WebSocket in project
软件测试技术之如何编写测试用例(4)
第二讲 软件生命周期
赶紧进来!!!教你C语言实现扫雷小游戏(文章最后有源码!!!)
生成回文数
中国的顶级黑客在国际上是一个什么样的水平?
# #ifndef/#define/#endif使用详解
Operations on std::vector
深度学习 RNN架构解析
【TCP/IP 五 ICMP】
最温馨的家园
力扣24-两两交换链表中的节点——链表
【社媒营销】WhatsApp Business API:您需要知道的一切