当前位置:网站首页>Big data processing black Technology: revealing the parallel computing technology of Pb level data warehouse gaussdb (DWS)
Big data processing black Technology: revealing the parallel computing technology of Pb level data warehouse gaussdb (DWS)
2020-11-06 21:35:00 【Huawei cloud developer community】
Abstract : Through this article , We get it GaussDB(DWS) The principle of parallel computing technology and optimization strategy . The majority of developers in practice hope that , Better performance optimization .
With the hardware system getting better and better , Database running CPU、 disk 、 Memory resources are increasing ,SQL The serial execution of statements cannot make full use of resources , It can't meet the growing needs . So ,GaussDB(DWS) Developed parallel computing technology , It can make full use of hardware resources for parallel acceleration when executing statements , Improve execution throughput . This article will introduce in detail GaussDB(DWS) The principle of parallel computing technology , And its performance Display in information , Help developers to better analyze the performance of parallel , So as to optimize the parallel execution .
The principle of parallel computing is very simple , The original work of a thread is evenly distributed to multiple threads to complete , The schematic diagram is shown in the figure below : The associated operation in the diagram , We had to work with four pieces of data , The degree of parallelism is 4 After parallel computing of , Each child thread only needs to process one piece of data , In theory, the performance improvement can reach 4 times .

Usually , The theoretical performance improvement is not attainable , Because parallel computing also has its performance loss , Include : The cost of starting a thread , And the cost of data transfer between threads . therefore , Only low performance loss , Much less than the benefits of parallelism , The benefits of parallel computing are obvious . therefore , Only in the case of large amount of data can parallel achieve higher performance benefits , Very suitable for analytical AP scene .
Through the above analysis , We can see that , The difficulty of parallel computing is not how to parallelize , It's about how to choose the parallelism correctly . When the amount of data is small , Maybe serial performance is the best , When the amount of data increases , Consider parallelization . For a complex execution plan , It may contain more than one operator , The amount of data processed by each operator is different , How to comprehensively consider parallelism , And deal with the data transmission relationship between operators , It will become the key difficulty of parallel computing technology .
GaussDB(DWS) Based on cost estimates , According to the amount of data in the table to generate the appropriate parallelism for the plan fragment , Let's say TPC-DS Q48 Take... For example ,GaussDB(DWS) What does the parallel plan look like ?
select sum (ss_quantity)
from store_sales, store, customer_demographics, customer_address, date_dim
where s_store_sk = ss_store_sk
and ss_sold_date_sk = d_date_sk and d_year = 1998
and
(
(
cd_demo_sk = ss_cdemo_sk
and
cd_marital_status = 'M'
and
cd_education_status = '4 yr Degree'
and
ss_sales_price between 100.00 and 150.00
)
or
(
cd_demo_sk = ss_cdemo_sk
and
cd_marital_status = 'D'
and
cd_education_status = 'Primary'
and
ss_sales_price between 50.00 and 100.00
)
or
(
cd_demo_sk = ss_cdemo_sk
and
cd_marital_status = 'U'
and
cd_education_status = 'Advanced Degree'
and
ss_sales_price between 150.00 and 200.00
)
)
and
(
(
ss_addr_sk = ca_address_sk
and
ca_country = 'United States'
and
ca_state in ('KY', 'GA', 'NM')
and ss_net_profit between 0 and 2000
)
or
(ss_addr_sk = ca_address_sk
and
ca_country = 'United States'
and
ca_state in ('MT', 'OR', 'IN')
and ss_net_profit between 150 and 3000
)
or
(ss_addr_sk = ca_address_sk
and
ca_country = 'United States'
and
ca_state in ('WI', 'MO', 'WV')
and ss_net_profit between 50 and 25000
)
)
;Corresponding performance The message is :
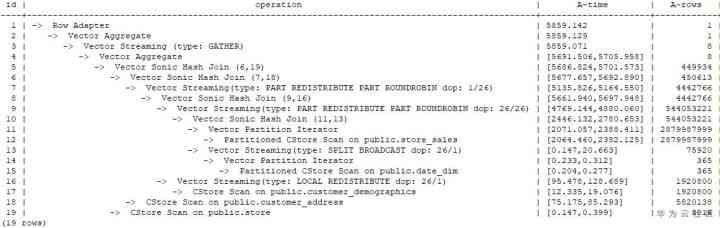
By way of performance Information turns into a plan tree , The plan tree of the plan can be obtained, as shown in the figure below : among 1-3 The sign operator is in CN On the implementation ,DN Cross thread data transfer on Stream Operators to separate , It's going to start 5 Threads .GaussDB(DWS) use pipeline The iterative execution pattern of , Threads 4 and 5 Read data from disk , Every other Stream Operator separated threads read data from child threads , To perform , And return the result to the upper operator , top floor DN Thread returns data to CN Handle . Through this picture , We can see that , Threads 1,4,5 The degree of parallelism used is 1, And threads 2,3 The degree of parallelism used is 26. Through planning information , We can see that ,8-13 The number operator processes a large amount of data , It's just a thread 2,3 The scope of processing , So we chose a higher degree of parallelism .
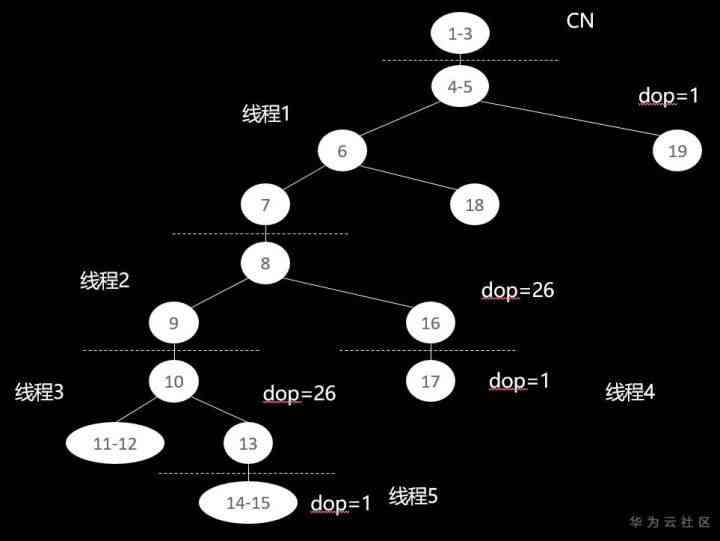
Parallel computing Stream Threads are still used DN Between the Stream Threads start and stop , but DN Internal data transfer is changed to memory copy , More saving network resources , But with a certain amount of memory overhead . meanwhile , The increase of parallelism also makes it possible to cross DN The data buffer for data transfer between is increased , The memory overhead becomes larger . therefore , Large memory is also a necessary factor to improve parallelism . So how do threads connect in parallel ?
By planning , We can see that , In parallel scenarios ,Stream Threads are shown as :Streaming(type: T dop:N/M), This is an extension of the serial scenario , You can also see the execution time of each thread at the thread level , Number of rows processed and memory used . In a serial scenario , We support three types of Stream operator , Respectively redistribute, broadcast and gather, For details, see 《GaussDB(DWS) Performance Tuning Series basic part 2 : The greatest truths are the simplest explain Distributed planning 》 The first chapter introduces .
The parallel scenario is a serial scenario DN Upper redistribute and broadcast type Stream Operators are extended , It includes the following categories :
1)Streaming(type: SPLIT REDISTRIBUTE): This is the same as in the serial scenario Redistribute, But data transfer is done on a thread by thread basis , Each tuple is sent to a destination thread .
2)Streaming(type: SPLIT BROADCAST): This is the same as in the serial scenario Broadcast, But data transfer is done on a thread by thread basis , Each thread will receive the full amount of data .
3)Streaming(type: LOCAL REDISTRIBUTE): Role is DN Internal data according to the current distribution key Redistribute. It is usually applied after base table scanning , Because the base table scan is divided into threads by page , At this time, the thread does not press DN Bond distribution , Need to add this DN Internal redistribution operations .
4)Streaming(type: LOCAL BROADCAST): Role is DN Internal data Broadcast, Each thread sends data to this DN All threads of , Each thread gets the DN The full amount of data .5)Streaming(type: LOCAL GATHER): Role is DN Internal aggregation of data from multiple threads to a single thread .
Be careful :“dop:N/M” Indicates the sender's dop by M, On the receiving end dop by N, So as to finish from M The parallelism of threads is changed to N Tasks with thread parallelism .
stay GaussDB(DWS) in , We added parameters query_dop, To control the parallelism of statements , The values are as follows :
1)query_dop=1, Serial execution , The default value is
2)query_dop=[2..N], Specifies the degree of parallelism for parallel execution
3)query_dop=0, Adaptive tuning , According to the complexity of the parallel statements and the system
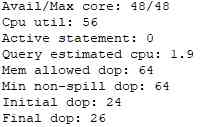
Because opening and merging will take up more memory , So at present GaussDB(DWS) The default parallelism of is 1. In a large memory environment , It can be set manually query_dop To achieve the purpose of parallel acceleration . Usually , We can consider setting query_dop=0, View the execution plan of the statement 、performance Information and performance . stay performance Below the message Query Summary One column , You can see the adaptation dop Selected information , for example :TPC-DS Q48 dop The selection information is shown in the figure below , It can be seen that the preliminary selection of initial dop by 24, It's final final dop by 26.dop All factors will be taken into consideration , The information is also shown in the diagram .
Because the adaptive selection of parallelism is based on the complexity of statements and the utilization of system resources , The system resource utilization is to obtain the resource utilization of the previous period , There may be inaccuracies , At this point, it is necessary to set the parallelism manually . Set the parallelism artificially , It's not that the bigger the setting, the better ,dop Set too large , Will lead to a sharp increase in the number of threads in the system , Lead to CPU The additional overhead of thread switching by conflict . To set the parallelism artificially , You also need to use a single machine CPU The kernel and the complexity of the sentence are considered . We define stand-alone CPU Check the number / stand-alone DN Count for each DN Usable CPU Check the number x, And then according to the serial plan DN Stream How to determine the complexity of several statements y( Such as below TPC-H Q1 There is only one in the plan Stream node , be y by 1), Single concurrent , Use x/y Value settings for query_dop. Concurrent scenarios , Divide it by the concurrency number p Set up query_dop. Since this formula is a rough estimate , Therefore, you can consider expanding the search scope when setting , To find the right degree of parallelism .

In a concurrent scenario ,GaussDB(DWS) And support max_active_statements To control the number of executed statements , When the number of statements exceeds CPU Checking time , Consider using this parameter to limit the number of concurrencies , And then set a reasonable query_dop tuning . Take the example just now , Single machine has 96 nucleus ,2 individual DN, Then each DN You can use 48 nucleus , At the same time 6 individual TPC-H Q1 When inquiring , Parallelism can be set to 8.
Through this article , We get it GaussDB(DWS) The principle of parallel computing technology and optimization strategy . The majority of developers in practice hope that , Better performance optimization .
Click to follow , The first time to learn about Huawei's new cloud technology ~
版权声明
本文为[Huawei cloud developer community]所创,转载请带上原文链接,感谢
边栏推荐
- 2020-08-30:裸写算法:二叉树两个节点的最近公共祖先。
- Using iceberg on kubernetes to create a new generation of cloud original data Lake
- Building a new generation cloud native data lake with iceberg on kubernetes
- EOS founder BM: what's the difference between UE, UBI and URI?
- What is the meaning of sector sealing of filecoin mining machine since the main network of filecoin was put online
- To solve the problem that the data interface is not updated after WPF binding set
- How about small and medium-sized enterprises choose shared office?
- Open source a set of minimalist front and rear end separation project scaffold
- To teach you to easily understand the basic usage of Vue codemirror: mainly to achieve code editing, verification prompt, code formatting
- Zero basis to build a web search engine of its own
猜你喜欢

What the hell is fastthreadlocal? The existence of ThreadLocal!!
ORA-02292: 违反完整约束条件 (MIDBJDEV2.SYS_C0020757) - 已找到子记录
What is the purchasing supplier system? Solution of purchasing supplier management platform
Diamond standard
检测证书过期脚本
All the way, I was forced to talk about C code debugging skills and remote debugging
GitHub: the foundation of the front end
Interviewer: how about shardingsphere
An article will take you to understand CSS3 fillet knowledge
The method of realizing high SLO on large scale kubernetes cluster
随机推荐
轻量型 GPU 应用首选 京东智联云推出 NVIDIA vGPU 实例
2020-08-20:GO语言中的协程与Python中的协程的区别?
An article will take you to understand CSS alignment
意外的元素..所需元素..
CCR coin frying robot: the boss of bitcoin digital currency, what you have to know
Visual rolling [contrast beauty]
ORA-02292: 违反完整约束条件 (MIDBJDEV2.SYS_C0020757) - 已找到子记录
细数软件工程----各阶段必不可少的那些图
Can you do it with only six characters?
An article takes you to understand CSS gradient knowledge
What is alicloud's experience of sweeping goods for 100 yuan?
[learning] interface test case writing and testing concerns
ES6 learning notes (5): easy to understand ES6's built-in extension objects
Introduction to the development of small game cloud
How to make characters move
How much disk space does a new empty file take?
Understanding formatting principles
2020-08-19:TCP是通过什么机制保障可靠性的?
Stickinengine architecture 12 communication protocol
Novice guidance and event management system in game development