当前位置:网站首页>【点云处理之论文狂读前沿版9】—Advanced Feature Learning on Point Clouds using Multi-resolution Features and Learni
【点云处理之论文狂读前沿版9】—Advanced Feature Learning on Point Clouds using Multi-resolution Features and Learni
2022-07-03 08:53:00 【LingbinBu】
PointStack:Advanced Feature Learning on Point Clouds using Multi-resolution Features and Learnable Pooling
摘要
- 问题: (1) 现有的点云特征学习网络通常都是不断地进行sampling, neighborhood grouping, neighborhood-wise feature learning, feature aggregation来学习点云的global context,但是这种处理过程会因为sampling而导致granular information的大量缺失;(2) 由于max-pooling feature aggregation完全抛弃了non-maximum point features,因此导致的信息损失更严重;(3)由于granular information和non-maximum point features的损失,导致现有网络提取的最终high-semantic点特征无法有效地表示点云的local context
- 方法: 提出了一种新的点云特征学习网络PointStack,使用了multi-resolution feature learning 和 learnable pooling(LP) 两种处理方法
- 技术细节:
①通过在多层间聚合不同分辨率的点特征实现 multi-resolution feature learning,最终的点特征会同时包含high-semantic和 high-resolution 信息
②Learnable pooling可以看作是广义pooling函数,通过带有learnable queries的注意力机制计算multi-resolution point features 的加权和 - 效果:
①在损失granular information和non-maximum point features的情况下提取high-semantic点特征
②最终聚合后的点特征可以同时表示点云的global和localcontext
③PointStack的network head能够更好地理解点云的globa结构和local形状细节 - 代码:https://github.com/kaist-avelab/PointStack PyTorch版本
引言
- 来自不同分辨率的点特征对特定任务的head而言是很有帮助的。
- 从所有点特征结合信息的广义pooling函数(permutation invariant)可以提高点特征的聚合能力
PointStack
Multi-resolution Feature Learning
与2D图像相比,3D形状更复杂,3D形状的一些重要纹理和曲线只有在最高的粒度级别上才能观察到。现有的方法都是牺牲细粒度构造high-semantic特征,因此multi-resolution point features就成为了既能收集足够的语义信息,又能一定程度上保留细粒度的方法。

通过现有的基于MLP方法(PointMLP)获取 m m m个不同分辨率下的点特征:
- 通过 m m m 个重复的残差块学习点的基础表示,与输入相比,每个残差块的输出分辨率更低但是具有更高的语义信息,选择残差块而不选择transformer块的原因是在内存消耗和计算复杂度上,残差块更占优势
- 在学习到合适的表示后,对输出的特征执行pooling操作。在第 i i i层中,大小为 N i × C i N_i \times C_i Ni×Ci的特征通过 P F i p o o l e d \mathbf{PF}_i^{pooled} PFipooled后,得到大小为 N m × C m N_m \times C_m Nm×Cm的pooled特征,该特征中包含了该层分辨率下的重要特征
- 将每一层通过 P F i p o o l e d \mathbf{PF}_i^{pooled} PFipooled后的特征进行拼接,得到大小为 N i × m ⋅ C i N_i \times m \cdot C_i Ni×m⋅Ci的stacked 特征,再通过 P F p o o l e d \mathbf{PF}^{pooled} PFpooled即可获得全局特征向量
由于全局特征向量是从 m m m个分辨率中得到的,因此它包含了high-semantic 和 high-resolution features信息。
本来在每一层pooling后的特征大小可以是不固定的,但是我们通过实验发现固定pooling后的特征大小有助于提升分类性能。原因可能因为 m m m个不同分辨率下的点特征会有不同数量的entries,即较高分辨率的点特征要比较低分辨率的点特征要有更多的特征向量,不同数量特征向量之间的差异可能会影响最后一个multi-resolution L P \mathrm{LP} LP。
Learnable Pooling

结构上,LP使用了multi-head attention (MHA),MHA被看作做一个信息检索的过程,一组queries被用于从values中检索信息,values是基于queries 和 keys相关性得到的。将keys和values设置为相同的点特征张量,而queries 是可学习参数。通过网络来学习合适的queries,那么检索到的点特征(values)与learning objectives就会高度相关。由于queries直接被learning objectives监督,values是通过所有点特征的加权和得到的,所以LP能够在最小信息损失的情况下聚合点特征。
性质1. 所提出的LP是一个对称函数,对于点云而言是permutation-invariance的
LP的permutation invariant性质最关键的点就是使用了point-wise shared-MLP,并且keys和values的选择都是相同的row-permuted feature matrix,那么permutation matrix是正交的,scaled dot-product attention mechanism 也就是permutation-invariance的。
实验
残差块使用的是PointMLP,single-resolution pooling 和 multi-resolution pooling中可学习的queries大小分别为 64 × 1024 64 \times 1024 64×1024和 1 × 4096 1 \times 4096 1×4096,残差块的数量设置为4,每个残差块中的可学习的queries都不一样。
Shape Classification
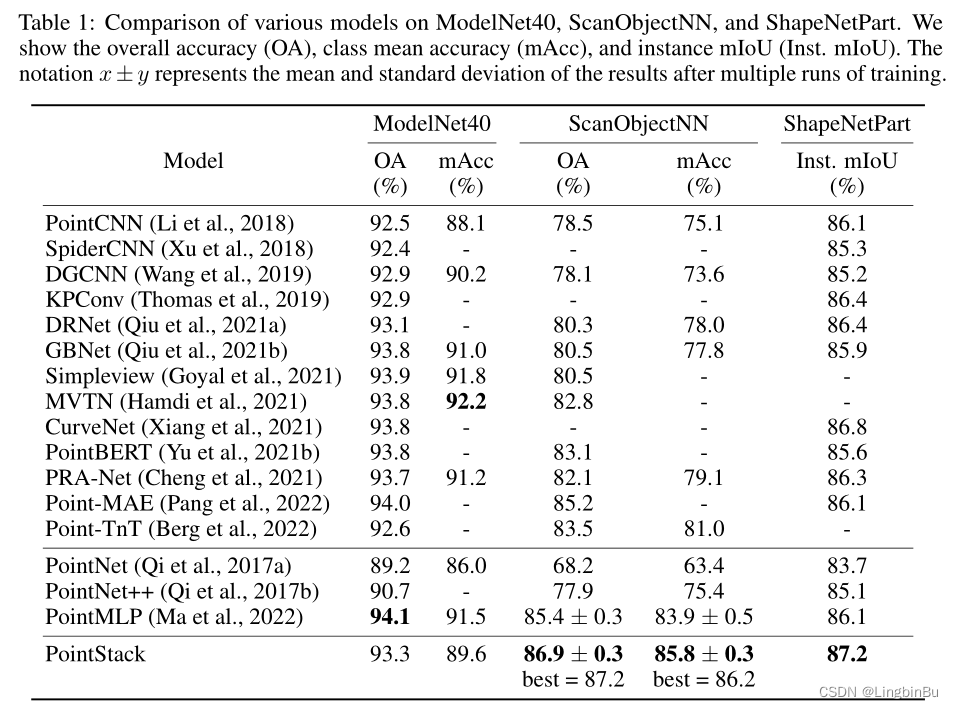
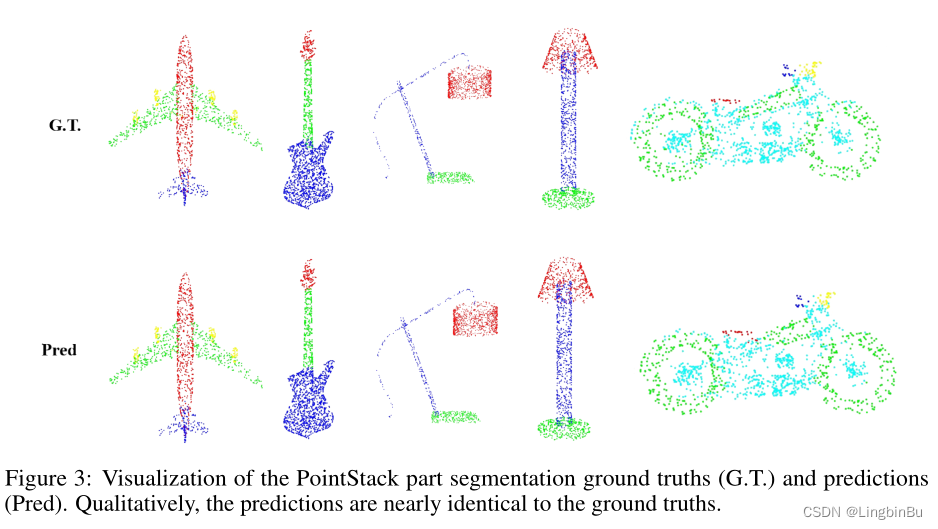
Part Segmentation
Ablation Study

Permutation Invariant Property of the Learnable Pooling

Limitations on the Number of Training Samples
- PointStack在ModelNet40上表现不好的原因可能是因为训练的样本不足
- 将ScanObjectNN样本减少,表现一样不太好,如表4所示
边栏推荐
- Mortgage Calculator
- Apache startup failed phpstudy Apache startup failed
- LeetCode 508. The most frequent subtree elements and
- Education informatization has stepped into 2.0. How can jnpf help teachers reduce their burden and improve efficiency?
- 网络安全必会的基础知识
- 高斯消元 AcWing 883. 高斯消元解线性方程组
- LeetCode 513. 找树左下角的值
- ES6 promise learning notes
- MySQL index types B-tree and hash
- I made mistakes that junior programmers all over the world would make, and I also made mistakes that I shouldn't have made
猜你喜欢
AcWing 788. 逆序对的数量
Facial expression recognition based on pytorch convolution -- graduation project

Phpstudy 80 port occupied W10 system
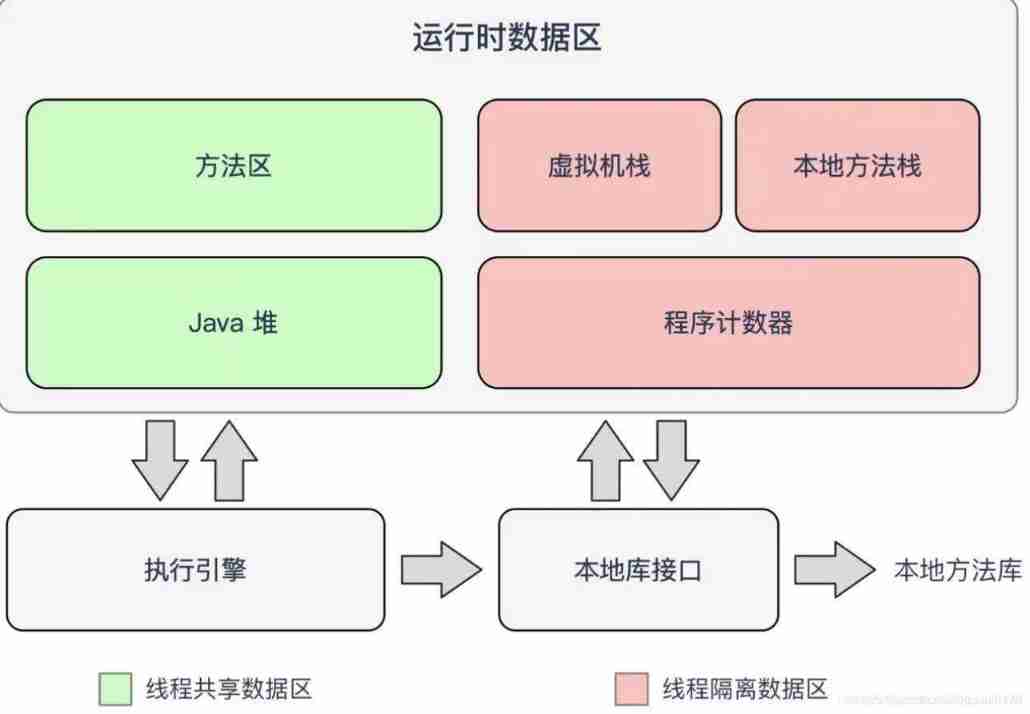
Deep parsing JVM memory model
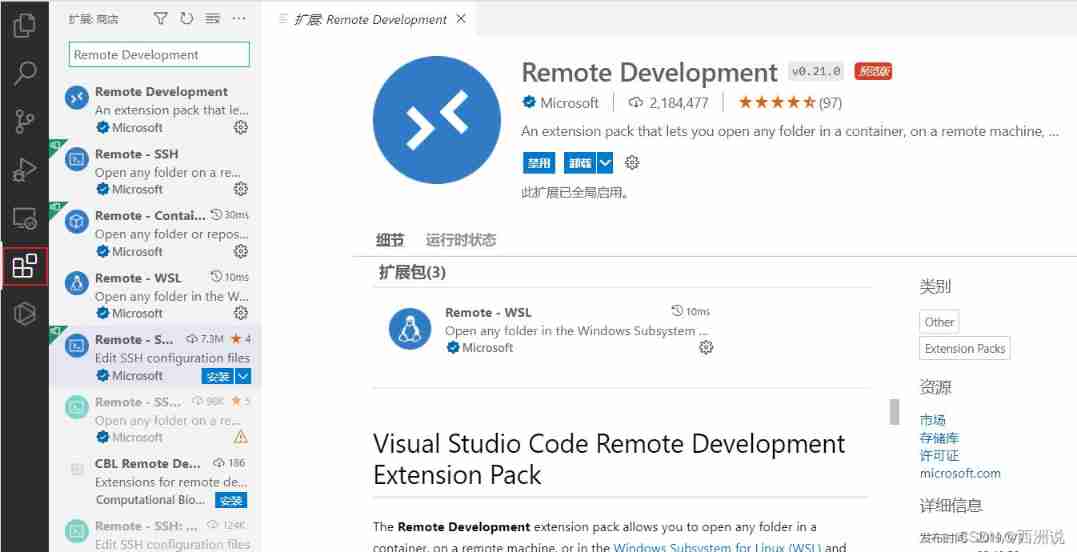
Vscode connect to remote server

MySQL three logs
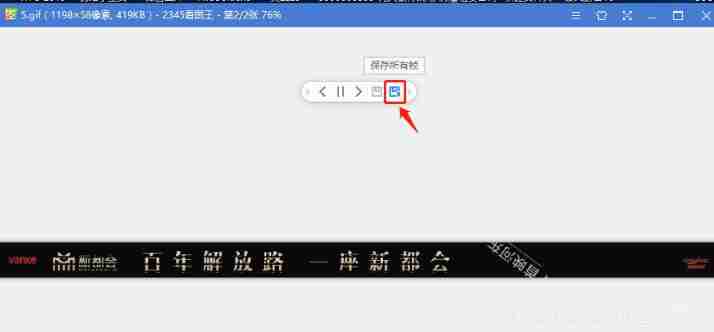
Gif remove blank frame frame number adjustment
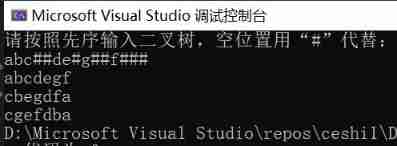
Binary tree traversal (first order traversal. Output results according to first order, middle order, and last order)
浅谈企业信息化建设

LeetCode 508. 出现次数最多的子树元素和
随机推荐
Binary tree sorting (C language, int type)
22-06-28 西安 redis(02) 持久化机制、入门使用、事务控制、主从复制机制
too many open files解决方案
What are the stages of traditional enterprise digital transformation?
On a un nom en commun, maître XX.
LeetCode 871. Minimum refueling times
LeetCode 1089. 复写零
Alibaba canal actual combat
PIC16F648A-E/SS PIC16 8位 微控制器,7KB(4Kx14)
Use of sort command in shell
How to delete CSDN after sending a wrong blog? How to operate quickly
Six dimensional space (C language)
AcWing 785. 快速排序(模板)
Using DLV to analyze the high CPU consumption of golang process
cres
LeetCode 30. Concatenate substrings of all words
LeetCode 513. Find the value in the lower left corner of the tree
URL backup 1
Common DOS commands
Dom4j traverses and updates XML