当前位置:网站首页>Code implementation MNLM
Code implementation MNLM
2022-07-02 13:46:00 【InfoQ】
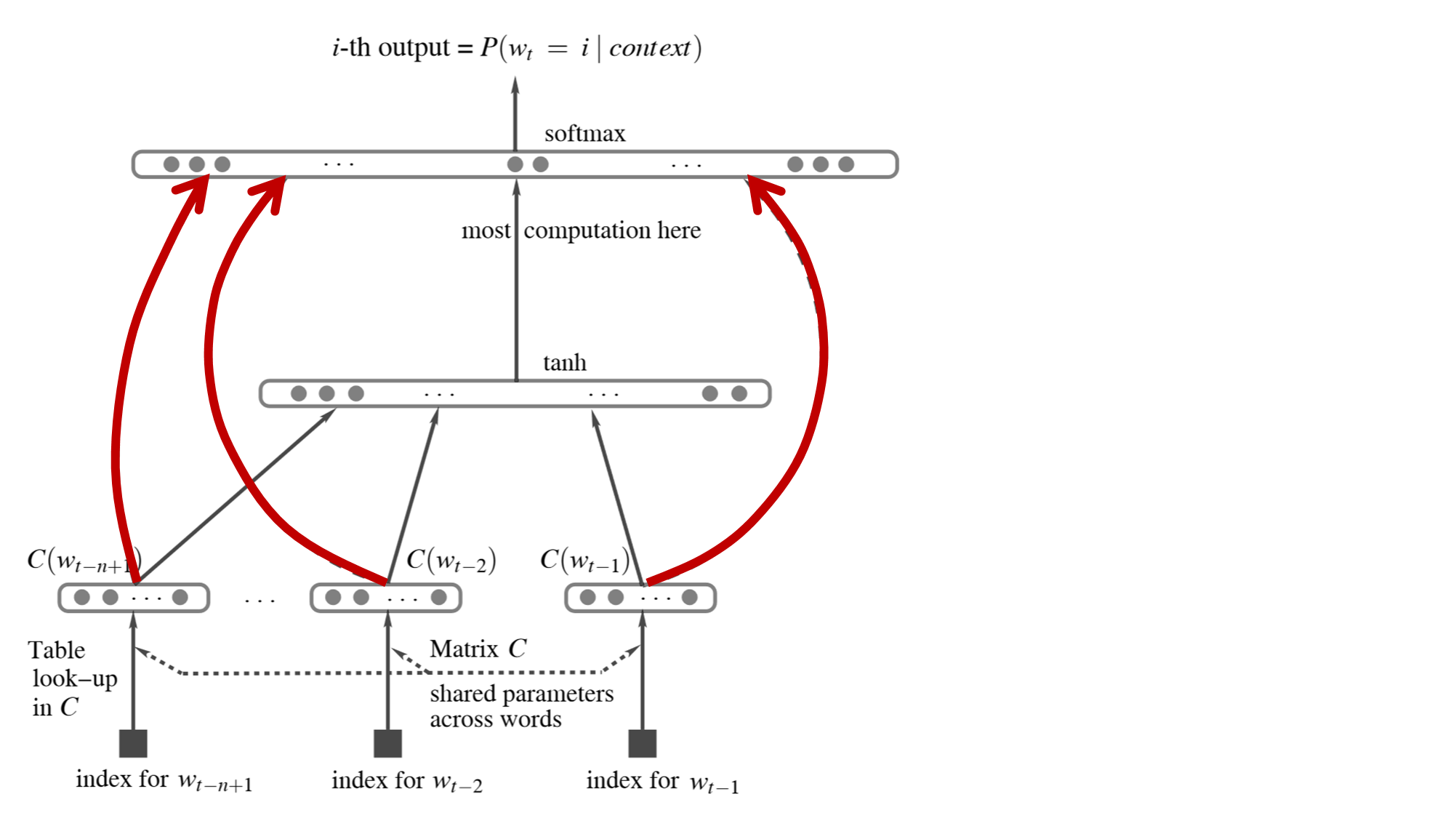
Let's review the model structure first

- y It's output
- x It's input , Then it will be transformed into C,But the original formula is still used x Express
- d It's a hidden layer bias
- H Is the weight of the input layer to the hidden layer
- U Is the weight from the hidden layer to the output layer
- W yes c Weight directly to the output layer
- b It's the output layer bias
Explain how the Internet came out



Code
The model code
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(len_sen * m, n_hidden,requires_grad=True))
self.d = nn.Parameter(torch.randn(n_hidden))
self.U = nn.Parameter(torch.randn(n_hidden, n_class,requires_grad=True))
self.W = nn.Parameter(torch.zeros(len_sen * m, n_class,requires_grad=True))
self.b = nn.Parameter(torch.randn(n_class))
def forward(self, X): # X : [batch_size, len_sen]
X = self.C(X) # X : [batch_size, len_sen, m]
X = X.view(-1, len_sen * m) # [batch_size, len_sen * m]
tanh = torch.tanh(self.d + X @ self.H) # [batch_size, n_hidden]
output = self.b + X @ self.W + tanh @ self.U # [batch_size, n_class]
return output
__init__(self)This part is the above parameter quantity .
self.CIt's a embedding operation .
- The rest is the parameters in the network . Mentioned W Initialize to 0 matrix , therefore W Use it there
torch.zeros, The rest use random initializationtorch.randn.
forward(self, X)Is to set forward propagation ,
X = self.C(X), First the X Carry out a embedding Handle , Then return the result to X. It corresponds to what we mentioned earlier , Although it takes a embedding Handle , But the input in the original formula still uses X It means .
Tensor.viewThe function is to modify the shape of the tensor .torch.Tensor.view — PyTorch 1.11.0 documentation. After the dimension is modified, the word in each sentence is word embedding Join the vectors together .
self.d + X @ self.HHere is the calculation of the hidden layer of the input layer .
tanh = torch.tanh(self.d + X @ self.H)The calculation result needs to go through tanh The activation function of . Here is the general tanh The result of the calculation of the activation function is directly assigned to a named tanh The variable of .
output = self.b + X @ self.W + tanh @ self.UThen there is the output layer calculation . Note here that the result of the output layer is composed of two parts . Part is the result of the hidden layer , Part is the result from the input layer , The calculation of hidden layer is only after the two are added .
batch_sizelen_senmn_hiddenn_class- At first, your input is a group of sentences , So your input X The shape of should be [batch_size, len_sen]. At this point, each element of the matrix is a word .

- After the first step embedding After calculation , It will be transformed into eigenvector representation . At this time X The shape of should be [batch_size, len_sen, m]. Because you are an element , To express a word . Now it becomes a word , Use an eigenvector to represent . So a dimension is added to represent the eigenvector . Now it becomes a three-dimensional matrix .

- after
Tensor.viewModify shape . Here isX.view(-1, len_sen * m)Change to two-dimensional matrix , The second dimension of the matrix is len_sen * m, The first dimension is adaptive (-1 It means adaptive ). It means to make a representation of different words in a sentence concate, Splice up .

tanhHere we have reached the hidden layer . So the length of the input vector will become the size of the hidden layer . The size of this hidden layern_hiddenYou need to set it yourself . The size of the hidden layer determines the quality of the network . Of course, the amount of data here is relatively small , So whether it's good or not actually has little effect on the size of the hidden layer . Generally, the size of the hidden layer follows the following rules .
- hypothesis :
- The input layer size is
- The output layer is divided intoclass
- The number of samples is
- A constant
- A common view is the number of hidden layers:
- ……
- How to determine the number and size of hidden layers in neural network _LolitaAnn Technology blog _51CTO Blog
- Here we use. The length entered in our code is
len_sen * m. The classification size is the length of the word listn_class. After calculation h The size is 14.
- At this time
tanhDimension for [batch_size, n_hidden].

- The shape of the output layer is [batch_size, n_class], What the output layer needs to do is calculate each sample and finally obtain a vector . The length of this vector is the same as the length of the word list , This indicates the position of the prediction result in the word list .

Data preprocessing part of the code
sentences = ["The cat is walking in the bedroom",
"A dog was running in a room",
"The cat is running in a room",
"A dog is walking in a bedroom",
"The dog was walking in the room"]
word_list = " ".join(sentences).lower().split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
- The seventh line of code
word_listIs to splice all sentences in the data set with spaces . Then convert it to lowercase . Then separate them with a space , Divided into different words . At this point, you get a list of words . But now there will be a lot of repeated words .
- The code on the eighth line
word_listFirst use set, Convert the list obtained above into a set , Remove duplicate words , Then convert back to the list .
- The ninth and tenth lines of code are dictionaries that use enumeration to create word lists .
def dataset():
input = []
target = []
for sen in sentences:
word = sen.lower().split() # space tokenizer
i = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
t = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input.append(i)
target.append(t)
return input, target

Complete code
import torch
import torch.nn as nn
import torch.optim as optim
def dataset():
input = []
target = []
for sen in sentences:
word = sen.lower().split() # space tokenizer
i = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
t = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input.append(i)
target.append(t)
return input, target
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(len_sen * m, n_hidden,requires_grad=True))
self.d = nn.Parameter(torch.randn(n_hidden))
self.U = nn.Parameter(torch.randn(n_hidden, n_class,requires_grad=True))
self.W = nn.Parameter(torch.zeros(len_sen * m, n_class,requires_grad=True))
self.b = nn.Parameter(torch.randn(n_class))
def forward(self, X): # X : [batch_size, len_sen, m]
X = self.C(X) # X : [batch_size, len_sen, m]
X = X.view(-1, len_sen * m) # [batch_size, len_sen * m]
tanh = torch.tanh(self.d + X @ self.H) # [batch_size, n_hidden]
output = self.b + X @ self.W + tanh @ self.U # [batch_size, n_class]
return output
if __name__ == '__main__':
sentences = ["The cat is walking in the bedroom",
"A dog was running in a room",
"The cat is running in a room",
"A dog is walking in a bedroom",
"The dog was walking in the room"]
word_list = " ".join(sentences).lower().split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary
len_sen = 6 # number of steps, n-1 in paper
m = 3 # embedding size, m in paper
n_hidden = (int)((len_sen*m*n_class)**0.5) # number of hidden size, h in paper
model = NNLM()
loss = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
input, target = dataset()
input = torch.LongTensor(input)
target = torch.LongTensor(target)
# Look at the effect before training .
predict = model(input).data.max(1, keepdim=True)[1]
print([sen.split()[:6] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
# Training
for epoch in range(5000):
optimizer.zero_grad()
output = model(input)
# output : [batch_size, n_class], target : [batch_size]
Loss = loss(output, target)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(Loss))
Loss.backward()
optimizer.step()
# Predict & test
predict = model(input).data.max(1, keepdim=True)[1]
print([sen.split()[:6] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
边栏推荐
- 2、 Frame mode MPLS operation
- mysql ---- Oracle中的rownum转换成MySQL
- Add sequence number column to query results in MySQL
- [youcans' image processing learning course] general contents
- (POJ - 1308)Is It A Tree? (tree)
- Solve "sub number integer", "jump happily", "turn on the light"
- 诚邀青年创作者,一起在元宇宙里与投资人、创业者交流人生如何做选择……...
- Skillfully use SSH to get through the Internet restrictions
- 口袋奇兵点评
- Unity skframework framework (XIX), POI points of interest / information points
猜你喜欢

【蓝桥杯选拔赛真题43】Scratch航天飞行 少儿编程scratch蓝桥杯选拔赛真题讲解

Unity skframework framework (XIX), POI points of interest / information points
能自动更新的万能周报模板,有手就会用!

Qt入门-制作一个简易的计算器
Qt新项目_MyNotepad++
ensp简单入门

Research shows that "congenial" is more likely to become friends
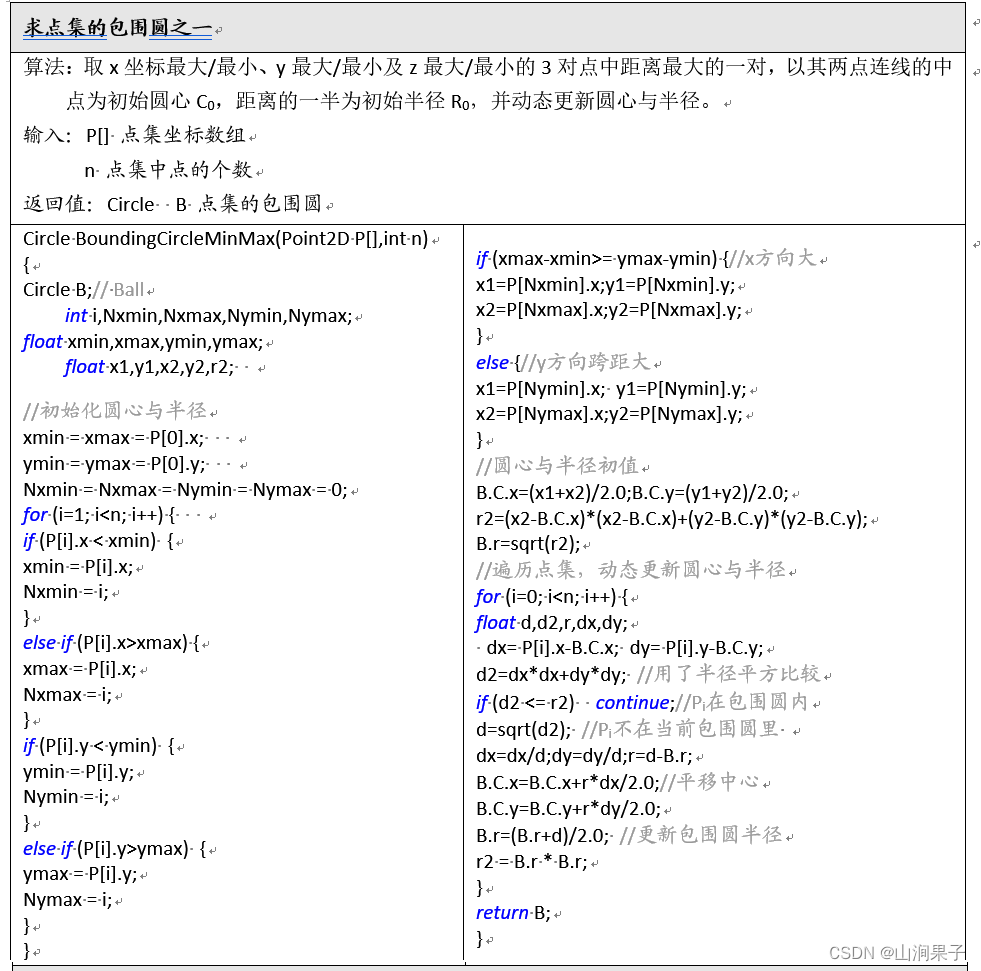
Professor of Shanghai Jiaotong University: he Yuanjun - bounding box (containment / bounding box)
二、帧模式 MPLS 操作

Partner cloud form strong upgrade! Pro version, more extraordinary!
随机推荐
Qt如何设置固定大小
量子三体问题: Landau Fall
How to use SAP's metadata framework (MDF) to build custom business rules?
二、帧模式 MPLS 操作
Quantum three body problem: Landau fall
Numpy array calculation
Professor of Shanghai Jiaotong University: he Yuanjun - bounding box (containment / bounding box)
【模板】最长公共子序列 (【DP or 贪心】板子)
Web Foundation
uniapp小程序 subPackages分包配置
Qt入门-制作一个简易的计算器
OpenApi-Generator:简化RESTful API开发流程
numpy数组计算
Why can't d link DLL
Qt-制作一个简单的计算器-实现四则运算
A better database client management tool than Navicat
Android kotlin fragment technology point
你的 Sleep 服务会梦到服务网格外的 bookinfo 吗
Fundamentals of machine learning (II) -- division of training set and test set
linux下清理系统缓存并释放内存