当前位置:网站首页>MySQL---aggregate function
MySQL---aggregate function
2022-07-31 17:16:00 【Narwhals need water】
聚合函数介绍
聚合(或聚集、分组)函数,它是对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值.
AVG和SUM函数
AVG / SUM :只适用于数值类型的字段(或变量)
SELECT AVG(salary),SUM(salary),AVG(salary) * 107
FROM employees;
如下的操作没有意义
SELECT SUM(last_name),AVG(last_name),SUM(hire_date)
FROM employees;
MIN和MAX函数
MAX / MIN :适用于数值类型、字符串类型、日期时间类型的字段(或变量)
SELECT MAX(salary),MIN(salary)
FROM employees;
SELECT MAX(last_name),MIN(last_name),MAX(hire_date),MIN(hire_date)
FROM employees;
COUNT函数
作用:计算指定字段在查询结构中出现的个数(不包含NULL值的)
SELECT COUNT(employee_id),COUNT(salary),COUNT(2 * salary),COUNT(1),COUNT(2),COUNT(*)
FROM employees ;
如果计算表中有多少条记录,如何实现?
方式1:COUNT(*)
方式2:COUNT(1)
方式3:COUNT(具体字段) : 不一定对!
COUNT(expr) 返回expr不为空的记录总数.
如何需要统计表中的记录数,使用COUNT(*)、COUNT(1)、COUNT(具体字段) 哪个效率更高呢?
如果使用的是MyISAM 存储引擎,则三者效率相同,都是O(1)
如果使用的是InnoDB 存储引擎,则三者效率:COUNT(*) = COUNT(1)> COUNT(字段)
问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的.这种引擎内部有一计数器在维护着行数.
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍.但好
于具体的count(列名).
问题:能不能使用count(列名)替换count(*)?
不要使用 count(列名)来替代 count(*) , count(*) 是 SQL92 定义的标准统计行数的语法,跟数
据库无关,跟 NULL 和非 NULL 无关.
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行
group by
基本使用
查询各个部门的平均工资,最高工资
SELECT department_id,AVG(salary),SUM(salary)
FROM employees
GROUP BY department_id
查询各个job_id的平均工资
SELECT job_id,AVG(salary)
FROM employees
GROUP BY job_id;
使用多个列分组
查询各个department_id,job_id的平均工资
方式1:
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id,job_id;
方式2:
SELECT job_id,department_id,AVG(salary)
FROM employees
GROUP BY job_id,department_id;
GROUP BY中使用WITH ROLLUP
使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所
有记录的总和,即统计记录数量
SELECT department_id,AVG(salary)
FROM employees
GROUP BY department_id WITH ROLLUP;
查询各个部门的平均工资,按照平均工资升序排列
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id
ORDER BY avg_sal ASC;
当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的.
错误的:
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id WITH ROLLUP
ORDER BY avg_sal ASC;
小结
结论1:SELECT中出现的非组函数的字段必须声明在GROUP BY 中.
反之,GROUP BY中声明的字段可以不出现在SELECT中.
结论2:GROUP BY 声明在FROM后面、WHERE后面,ORDER BY 前面、LIMIT前面
HAVING(作用:用来过滤数据的)
要求1:如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE.否则,报错.
要求2:HAVING 必须声明在 GROUP BY 的后面.
要求3:开发中,我们使用HAVING的前提是SQL中使用了GROUP BY
#正确的写法:
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
方式1:推荐,执行效率高于方式2.
SELECT department_id,MAX(salary)
FROM employees
WHERE department_id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary) > 10000;
方式2:
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN (10,20,30,40);
结论:当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中.
当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE中或
HAVING中都可以.但是,建议大家声明在WHERE中.
WHERE 与 HAVING 的对比
1. 从适用范围上来讲,HAVING的适用范围更广.
2. 如果过滤条件中没有聚合函数:这种情况下,WHERE的执行效率要高于HAVING
SELECT的执行过程
SELECT 语句的完整结构
sql92语法:
SELECT ....,....,....(存在聚合函数)
FROM ...,....,....
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....
sql99语法:
SELECT ....,....,....(存在聚合函数)
FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件
(LEFT / RIGHT)JOIN ... ON ....
WHERE 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....
SQL语句的执行过程:
FROM ...,...-> ON -> (LEFT/RIGNT JOIN) -> WHERE -> GROUP BY -> HAVING -> SELECT ->
DISTINCT -> ORDER BY -> LIMIT
聚合函数练习
1.where子句可否使用组函数进行过滤?
NO
2.查询公司员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary), MIN(salary), AVG(salary), SUM(salary)
FROM employees;
3.查询各job_id的员工工资的最大值,最小值,平均值,总和
SELECT job_id, MAX(salary), MIN(salary), AVG(salary), SUM(salary)
FROM employees
GROUP BY job_id;
4.选择具有各个job_id的员工人数
SELECT job_id, COUNT(*)
FROM employees
GROUP BY job_id;
5. 查询员工最高工资和最低工资的差距(DIFFERENCE)
SELECT MAX(salary), MIN(salary), MAX(salary) - MIN(salary) DIFFERENCE
FROM employees;
6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
SELECT manager_id, MIN(salary)
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
HAVING MIN(salary) > 6000;
7.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
SELECT department_name, location_id, COUNT(employee_id), AVG(salary) avg_sal
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
GROUP BY department_name, location_id
ORDER BY avg_sal DESC;
8.查询每个工种、每个部门的部门名、工种名和最低工资
SELECT department_name,job_id,MIN(salary)
FROM departments d LEFT JOIN employees e
ON e.`department_id` = d.`department_id`
GROUP BY department_name,job_id
边栏推荐
猜你喜欢

Introduction of Jerry voice chip ic toy chip ic_AD14NAD15N full series development
使用 Postman 工具高效管理和测试 SAP ABAP OData 服务的试读版

Golang 小数操作之判断几位小数点与四舍五入
![[pytorch] pytorch automatic derivation, Tensor and Autograd](/img/99/c9632a7d3f70a13e1e26b9aa67b8b9.png)
[pytorch] pytorch automatic derivation, Tensor and Autograd

【网络通信三】研华网关Modbus服务设置
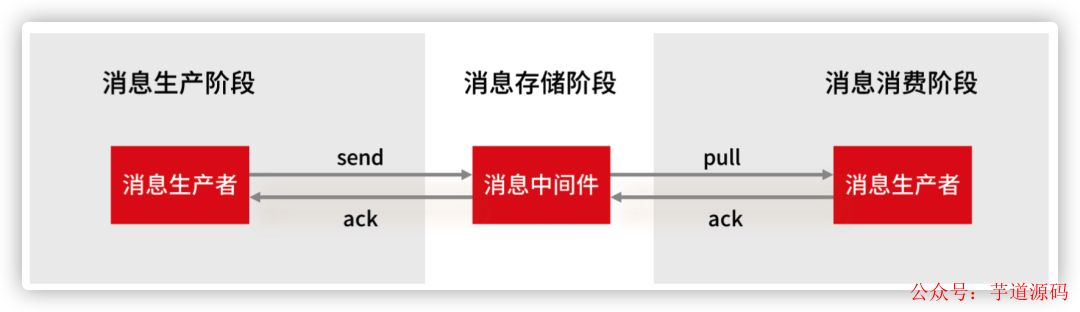
Three aspects of Ali: How to solve the problem of MQ message loss, duplication and backlog?
Design and Implementation of Compiler Based on C Language

AcWing 1282. 搜索关键词 题解((AC自动机)Trie+KMP)+bfs)

flyway的快速入门教程

自动化测试—web自动化—selenium初识
随机推荐
Introduction of Jerry voice chip ic toy chip ic_AD14NAD15N full series development
[pytorch] 1.7 pytorch and numpy, tensor and array conversion
Go1.18升级功能 - 模糊测试Fuzz 从零开始Go语言
华为顶级工程师历时9年总结的“趣谈网络协议”PDF文档,太强了
智能垃圾桶(九)——震动传感器(树莓派pico实现)
MySQL---创建和管理数据库和数据表
go mode tidy出现报错go warning “all“ matched no packages
20.支持向量机—数学原理知识
Anaconda如何顺利安装CV2
Kotlin coroutines: continuation, continuation interceptor, scheduler
杰理语音芯片ic玩具芯片ic的介绍_AD14NAD15N全系列开发
利用PHP开发具有注册、登陆、文件上传、发布动态功能的网站
【Yugong Series】July 2022 Go Teaching Course 020-Array of Go Containers
IP协议从0到1
【C语言】LeetCode27.移除元素
研发过程中的文档管理与工具
Istio介绍
【码蹄集新手村600题】不通过字符数组来合并俩个数字
flowable工作流所有业务概念
How to install CV2 smoothly in Anaconda