当前位置:网站首页>pdf 提取文字
pdf 提取文字
2022-07-27 14:45:00 【桂花很香,旭很美】
import os
import pandas as pd
import sys
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice, TagExtractor
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import XMLConverter, HTMLConverter, TextConverter
from pdfminer.cmapdb import CMapDB
from pdfminer.layout import LAParams
from pdfminer.image import ImageWriter
# debug option
debug = 1
# input option
password = b''
pagenos = set()
maxpages = 0
# output option
outtype = 'text'
imagewriter = None
rotation = 0
stripcontrol = False
layoutmode = 'normal'
encoding = 'utf-8'
pageno = 1
scale = 1
caching = True
showpageno = True
laparams = LAParams()
PDFDocument.debug = debug
PDFParser.debug = debug
CMapDB.debug = debug
PDFPageInterpreter.debug = debug
#遍历目录下的所有text文件
import time
txt_list = []
for root, dirs, files in os.walk("pdf_sentence/", topdown=False):
for i,name in enumerate(files):
rsrcmgr = PDFResourceManager(caching=caching)
#获取文件绝对地址
end = name.split('.')[1]
if 'pdf'in end:
print(i,name)
fname = name
outfile = name.split('.')[0] + '.txt'
outfp = open("pdf_txt/"+outfile, 'a+', encoding=encoding)
device = TextConverter(rsrcmgr, outfp, laparams=laparams,
imagewriter=imagewriter)
with open("pdf_sentence/"+fname, 'rb') as fp:
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.get_pages(fp, pagenos,
maxpages=maxpages, password=password,
caching=caching, check_extractable=True):
page.rotate = (page.rotate+rotation) % 360
time.sleep(1)
interpreter.process_page(page)
txt_list.append(outfile)
print(fname + " done !")
device.close()
outfp.close()
print(" device release")还有一种简单的:
#遍历目录下的所有text文件
import time
import os
txt_list = []
for root, dirs, files in os.walk("pdf_sentence/", topdown=False):
for i,name in enumerate(files):
end = name.split('.')[1]
if 'pdf'in end:
fname = name
outfile = name.split('.')[0]
re = os.system("python pdf2txt_self.py -o pdf_txt/%s.txt -d pdf_sentence/%s"%(outfile,name))
print("extract "+name+ " done!")这里调用了pdf2txt.py
来看一下他的代码:
#!/usr/bin/env python
import sys
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice, TagExtractor
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import XMLConverter, HTMLConverter, TextConverter
from pdfminer.cmapdb import CMapDB
from pdfminer.layout import LAParams
from pdfminer.image import ImageWriter
# main
def main(argv):
import getopt
def usage():
print(f'usage: {argv[0]} [-P password] [-o output] [-t text|html|xml|tag]'
' [-O output_dir] [-c encoding] [-s scale] [-R rotation]'
' [-Y normal|loose|exact] [-p pagenos] [-m maxpages]'
' [-S] [-C] [-n] [-A] [-V] [-M char_margin] [-L line_margin]'
' [-W word_margin] [-F boxes_flow] [-d] input.pdf ...')
return 100
try:
(opts, args) = getopt.getopt(argv[1:], 'dP:o:t:O:c:s:R:Y:p:m:SCnAVM:W:L:F:')
except getopt.GetoptError:
return usage()
if not args: return usage()
# debug option
debug = 0
# input option
password = b''
pagenos = set()
maxpages = 0
# output option
outfile = None
outtype = None
imagewriter = None
rotation = 0
stripcontrol = False
layoutmode = 'normal'
encoding = 'utf-8'
pageno = 1
scale = 1
caching = True
showpageno = True
laparams = LAParams()
for (k, v) in opts:
if k == '-d': debug += 1
elif k == '-P': password = v.encode('ascii')
elif k == '-o': outfile = v
elif k == '-t': outtype = v
elif k == '-O': imagewriter = ImageWriter(v)
elif k == '-c': encoding = v
elif k == '-s': scale = float(v)
elif k == '-R': rotation = int(v)
elif k == '-Y': layoutmode = v
elif k == '-p': pagenos.update( int(x)-1 for x in v.split(',') )
elif k == '-m': maxpages = int(v)
elif k == '-S': stripcontrol = True
elif k == '-C': caching = False
elif k == '-n': laparams = None
elif k == '-A': laparams.all_texts = True
elif k == '-V': laparams.detect_vertical = True
elif k == '-M': laparams.char_margin = float(v)
elif k == '-W': laparams.word_margin = float(v)
elif k == '-L': laparams.line_margin = float(v)
elif k == '-F': laparams.boxes_flow = float(v)
#
PDFDocument.debug = debug
PDFParser.debug = debug
CMapDB.debug = debug
PDFPageInterpreter.debug = debug
#
rsrcmgr = PDFResourceManager(caching=caching)
if not outtype:
outtype = 'text'
if outfile:
if outfile.endswith('.htm') or outfile.endswith('.html'):
outtype = 'html'
elif outfile.endswith('.xml'):
outtype = 'xml'
elif outfile.endswith('.tag'):
outtype = 'tag'
if outfile:
outfp = open(outfile, 'w', encoding=encoding)
else:
outfp = sys.stdout
if outtype == 'text':
device = TextConverter(rsrcmgr, outfp, laparams=laparams,
imagewriter=imagewriter)
elif outtype == 'xml':
device = XMLConverter(rsrcmgr, outfp, laparams=laparams,
imagewriter=imagewriter,
stripcontrol=stripcontrol)
elif outtype == 'html':
device = HTMLConverter(rsrcmgr, outfp, scale=scale,
layoutmode=layoutmode, laparams=laparams,
imagewriter=imagewriter, debug=debug)
elif outtype == 'tag':
device = TagExtractor(rsrcmgr, outfp)
else:
return usage()
for fname in args:
with open(fname, 'rb') as fp:
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.get_pages(fp, pagenos,
maxpages=maxpages, password=password,
caching=caching, check_extractable=True):
page.rotate = (page.rotate+rotation) % 360
interpreter.process_page(page)
device.close()
outfp.close()
return
if __name__ == '__main__': sys.exit(main(sys.argv))
代码写的很清楚,稍微改了一丢丢(基本没改哈哈哈)就能用的
#!/usr/bin/env python
import sys
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice, TagExtractor
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import XMLConverter, HTMLConverter, TextConverter
from pdfminer.cmapdb import CMapDB
from pdfminer.layout import LAParams
from pdfminer.image import ImageWriter
# main
def main(argv):
import getopt
def usage():
print(f'usage: {argv[0]} [-P password] [-o output] [-t text|html|xml|tag]'
' [-O output_dir] [-c encoding] [-s scale] [-R rotation]'
' [-Y normal|loose|exact] [-p pagenos] [-m maxpages]'
' [-S] [-C] [-n] [-A] [-V] [-M char_margin] [-L line_margin]'
' [-W word_margin] [-F boxes_flow] [-d] input.pdf ...')
return 100
try:
(opts, args) = getopt.getopt(argv[1:], 'dP:o:t:O:c:s:R:Y:p:m:SCnAVM:W:L:F:')
except getopt.GetoptError:
return usage()
if not args: return usage()
# debug option
debug = 0
# input option
password = b''
pagenos = set()
maxpages = 0
# output option
outfile = None
outtype = 'text'
imagewriter = None
rotation = 0
stripcontrol = False
layoutmode = 'normal'
encoding = 'utf-8'
pageno = 1
scale = 1
caching = True
showpageno = True
laparams = LAParams()
for (k, v) in opts:
if k == '-d': debug += 1
elif k == '-P': password = v.encode('ascii')
elif k == '-o': outfile = v
elif k == '-t': outtype = v
elif k == '-O': imagewriter = ImageWriter(v)
elif k == '-c': encoding = v
elif k == '-s': scale = float(v)
elif k == '-R': rotation = int(v)
elif k == '-Y': layoutmode = v
elif k == '-p': pagenos.update( int(x)-1 for x in v.split(',') )
elif k == '-m': maxpages = int(v)
elif k == '-S': stripcontrol = True
elif k == '-C': caching = False
elif k == '-n': laparams = None
elif k == '-A': laparams.all_texts = True
elif k == '-V': laparams.detect_vertical = True
elif k == '-M': laparams.char_margin = float(v)
elif k == '-W': laparams.word_margin = float(v)
elif k == '-L': laparams.line_margin = float(v)
elif k == '-F': laparams.boxes_flow = float(v)
#
PDFDocument.debug = debug
PDFParser.debug = debug
CMapDB.debug = debug
PDFPageInterpreter.debug = debug
#
rsrcmgr = PDFResourceManager(caching=caching)
if outfile:
outfp = open(outfile, 'a+', encoding=encoding)
else:
outfp = sys.stdout
if outtype == 'text':
device = TextConverter(rsrcmgr, outfp, laparams=laparams,
imagewriter=imagewriter)
for fname in args:
with open(fname, 'rb') as fp:
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.get_pages(fp, pagenos,
maxpages=maxpages, password=password,
caching=caching, check_extractable=True):
page.rotate = (page.rotate+rotation) % 360
interpreter.process_page(page)
device.close()
outfp.close()
return
if __name__ == '__main__': sys.exit(main(sys.argv))
边栏推荐
猜你喜欢

Time series ARIMA model

测试新手学习宝典(有思路有想法)
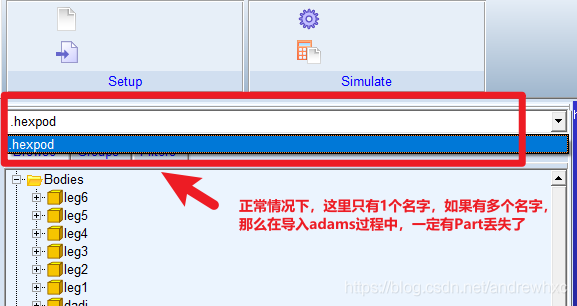
solidwork装配体导入到Adams中出现多个Part重名和Part丢失的情况处理

Boolean value

Servlet basic knowledge points

Embedded development: tips and techniques -- seven techniques to meet the real-time deadline

C channel simply implements the publishing and subscription of message queue

Time series - use tsfresh for classification tasks

DEX and AMMS of DFI security

Draw circuit diagram according to Verilog code
随机推荐
Nacos
Makefile specifies the path of the library file loaded when the program runs
2.2 JMeter基本元件
Leetcode25 question: turn the linked list in a group of K -- detailed explanation of the difficult questions of the linked list
MapReduce instance (II): Average
DRF learning notes (II): Data deserialization
Coding technique - Global log switch
JSP基础
centos yum方式安装mysql
Web test learning notes 01
Solve the problem that Flink cannot be closed normally after startup
Reduce program ROM ram, GCC -ffunction sections -fdata sections -wl, – detailed explanation of GC sections parameters
webRTC中的coturn服务安装
Paper_ Book
solidwork装配体导入到Adams中出现多个Part重名和Part丢失的情况处理
ARIMA模型选择与残差
IO stream introduction
Use of arrow function
Yys mouse connector
Keil implements compilation with makefile