当前位置:网站首页>浅谈GPU:历史发展,架构
浅谈GPU:历史发展,架构
2022-06-27 06:11:00 【honky-tonk_man】
GPU历史
要将GPU当然要从CPU开始说起,CPU在设计之初并没有规定特定的workload,而是假设所有的workload都会发生在CPU上,所以CPU的设计目的是为了“通用(generalists)”各种工作场景
我们都知道CPU有流水线,但是,CPU的设计者都尽量的将CPU的流水线设计的短一点,对于每一个指令在CPU流水线中有着以下的步骤
- 从内存中load 指令给CPU(此时指令的地址或者叫做指针已经在PC中)
- CPU解码指令,并且根据指令从寄存器中得到对应的操作数,这个操作数是我们指令需要用到的
- CPU执行指令,CPU用ALU执行指令
- 假如指令是关于内存的,我们要读或者写内存的数据
- 将指令执行的结果写回寄存器
假设我们有以下的一段伪代码
a := b+c
if a == 0 then
do this...
else
do that:
endif
我们看上面的伪代码有非常多的分支,首先我们肯定是执行第一个IF指令,当我们的IF指令执行到CPu流水线的第二阶段解码阶段,我们按照CPU流水线的设计load第二个条指令到CPU流水线的第一个阶段中,但是我们第一个指令的结果还没出来,我们不知道是load then后面的指令还是load,else后面的指令…此时CPU会进行一个guess,就是随机选一个分支进行load,如果对了完事大吉继续执行,如果错了就清除之前的流水线中的指令然后load正确的分支指令重新进入流水线,所以CPU的流水线不易做的特别长,假如发生了分支预测失败,我们需要在流水线中清除的指令实在太多
FPU
历史上FPU总是作为一个coprocessor对于CPU来说(一般是集成在CPU中),FPU一般不会自己运行,只有到CPU进行浮点数运算的时候才会使用FPU进行计算
为什么CPU不进行浮点数运算,而是交给FPU呢?因为CPU进行浮点数运算非常慢,为什么CPU执行浮点数这么慢?因为浮点数和整数相比不是按照“常规”存储,浮点数存储一般分为3个部分,分别为符号位(代表浮点数的正负),指数位,位数,比如-161.875,首先为负所以第一个符号位为1,然后我们将161.875化成二进制161的二进制为10100001,875的二进制为1101101011,和一起为10100001.1101101011,但是浮点数的指数位只有8位
而我们的cpu在读取float的时候会先取值再解析才能组成最终的float值,和int不一样,
GPU
说了FPU那么和我们GPU有什么关系?要知道GPU是用来并行的做大量浮点数运算,因为GPU需要处理非常多相同指令不同数据的操作,所以GPU用SIMD(single instructtion multiple data)设计了一个非常长的流水线
GPU架构
首先对比GPU和CPU
CPU在延迟方面做了非常大的优化,其目的是为了快速运行程序,尽可能的减少延迟,尽可能快的切换到其他的进程做优化
而GPU是对吞吐量做了优化,其单核执行效率可能没有CPU单核厉害,但是其核心数非常多,意味着同一时间接收的任务或者进程数量也非常多,接收进程数量多也意味着吞吐量非常大
我们先看现代CPU的架构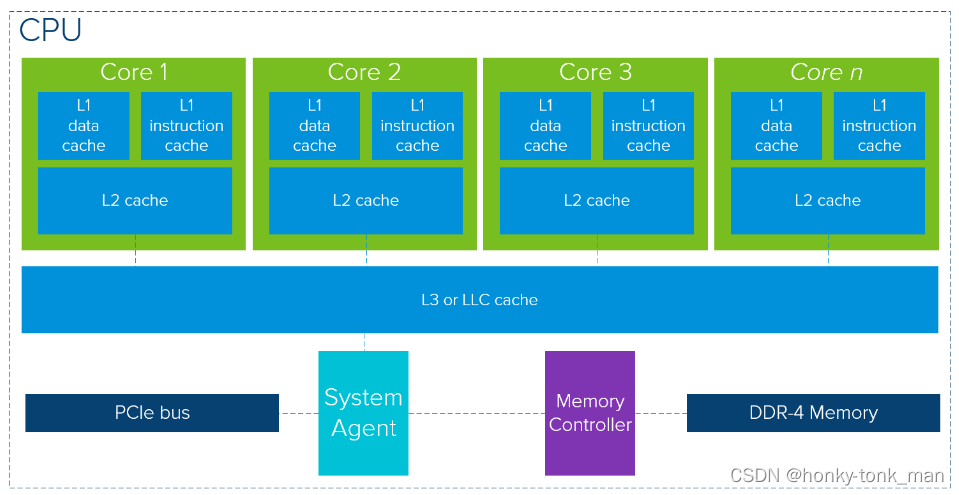
通过上图架构我们知道CPU频繁的使用cache去降低延迟(要知道cache要比内存快得多)
每一个core都有二个一级缓存和一个二级缓存,每一个核的2个一级缓存分别是数据缓存核指令缓存,而他们共享的二级缓存空间比一级缓存更大(当然从速度角度上将二级缓存比一级缓存更慢)
最后每个核都共享三级缓存(三级缓存比二级缓存空间更大,速度更慢),最后就脱离CPU的范畴,比如主存
我们再看GPU架构

和CPU每一个core都有两级缓存相比,GPU的缓存使用就少了很多,其延迟当然也比CPU大不少
从上图得出
一个GPU由多个processor cluster组成(上图就画了四个虽然他标个n)
一个processor cluster由多个Streaming Multiprocessors组成
一个Streaming Multiprocessors里面可能包含多个core,从上图得出Streaming Multiprocessors中一定数量的core共享一级缓存,多个Streaming Multiprocessors共享二级缓存
至此GPU上就没缓存了,其他的就是GPU上插的板载内存(貌似不可拆卸)这个板载内存一般都比较新,比如上图就用了DDR5的内存
程序从CPU到GPU之间需要用PCIE总线去传输数据,这个是非常慢的,假如我们有大量的数据需要GPU执行这个传输可能就是瓶颈
我们的一个服务器可能插多个GPU,英伟达的GPU之间可以通过特殊的方式进行数据传输,比如NVlink,其速率是PCIE的几百倍…
边栏推荐
- yaml文件加密
- Quick personal site building guide using WordPress
- [cocos creator 3.5.1] addition of coordinates
- 【QT小记】QT元对象系统简单认识
- Yaml file encryption
- 【Cocos Creator 3.5.1】input. Use of on
- Crawler learning 5--- anti crawling identification picture verification code (ddddocr and pyteseract measured effect)
- TiDB 中的视图功能
- Keep 2 decimal places after multiplying SQLSEVER fields
- The form verifies the variables bound to the V-model, and the solution to invalid verification
猜你喜欢

【QT小作】使用结构体数据生成读写配置文件代码

IDEA一键生成Log日志
JVM object composition and storage

函数栈帧的形成与释放

Altium designer 19 device silk screen label position shall be placed uniformly in batches

JVM类加载机制

0.0.0.0:x的含义

Kubesphere cluster configuration NFS storage solution - favorite

汇编语言-王爽 第9章 转移指令的原理-笔记

Program ape learning Tiktok short video production
随机推荐
TiDB 基本功能
G1 and ZGC garbage collector
openresty使用文档
Openresty usage document
【养成系】常用正则表达式
Add widget on qlistwidgetitem
30 SCM common problems and solutions!
Webrtc series - Nomination and ice of 7-ice supplement for network transmission_ Model
30个单片机常见问题及解决办法!
使用CSDN 开发云搭建导航网站
使用 WordPress快速个人建站指南
Multithreading basic part part 1
Yaml file encryption
427- binary tree (617. merge binary tree, 700. search in binary search tree, 98. verify binary search tree, 530. minimum absolute difference of binary search tree)
IDEA一键生成Log日志
【QT小记】QT元对象系统简单认识
【Cocos Creator 3.5.1】this. node. Use of getposition (this.\u curpos)
JVM garbage collection mechanism
汇编语言-王爽 第9章 转移指令的原理-笔记
My opinion on test team construction