当前位置:网站首页>Superscalar processor design yaoyongbin Chapter 6 instruction decoding excerpt
Superscalar processor design yaoyongbin Chapter 6 instruction decoding excerpt
2022-07-04 17:37:00 【Qi Qi】
In the assembly line , Instruction decoding decode The task of phase is to extract the information carried in the instruction , The processor uses this information to control the subsequent pipeline to execute this instruction .
The complexity of the instruction set directly determines the workload of this part of the task , about CISC For the instruction set , for example x86 Come on , The length of the instruction is not fixed , The decoding stage first needs to distinguish the boundaries of instructions , Only in this way can we find effective instructions , and x86 The addressing mode of instructions is also very complex , This increases the difficulty of decoding . about RISC For the instruction set , The length of the instruction is fixed , for example MIPS and ARM, All are 32 position , It's easy to distinguish , and RISC The addressing mode of the processor is relatively simple , These factors lead to RISC The decoding difficulty of the processor is much lower than CISC processor , therefore RISC Processors are inherently better than CISC Processors dominate . There is another factor that affects the complexity of processor decoding , That is the number of instructions that can be decoded per cycle , Because each instruction requires a complete decoding circuit , So for each cycle, it can be decoded n Bar superscalar processor , Need n Decoding circuits .
In short , One RISC The decoding part of the processor is as follows
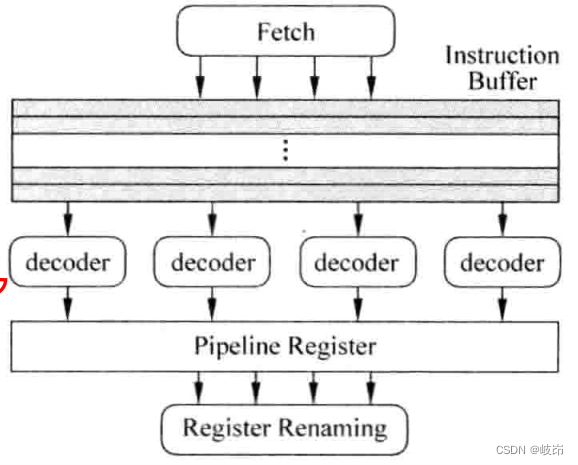
In superscalar processors , Even if it's RISC Instruction set , There are still some alternative instructions , These instructions cannot be processed in the way of general instructions , Require special treatment , For example, some instructions have more destination registers than a multiply accumulate sum LDM/STM etc. , This will affect register renaming register renaming The process . Another example is , There are some RISC The instruction set supports conditional execution of each instruction , However, these alternative instructions are not used frequently , There is no need to add hardware to the later pipeline to process them , This requires converting them into ordinary instructions in the decoding phase , The later pipeline executes them according to the processing method of general instructions .
6.1 Instruction cache
In order to reduce the I-Cache The impact of lack , The processor can fetch instructions from I-Cache The number of instructions extracted from is more than the number of instructions that can be decoded per cycle , for example MIPS 74kf In the processor , Take out every cycle 4 Orders , But each cycle can only be decoded 2 Orders , This requires adding a cache between the instruction fetch and decoding stages , Used to put I-Cache Save all instructions taken , This cache is called instruction cache instruction buffer.
(1) Four instructions , Of course, not all these four instructions are valid ;
(2) Number of valid instructions , When the address of the instruction falls in Cache line The last three words of , Or instruction group fetch group When there are branch instructions predicted to jump in , As a result, the instruction fetch stage cannot write four instructions to the instruction cache , At this time, use this model to tell the instruction cache , Those instructions are valid .
Instruction caching is essentially a FIFO, It can store instructions in the order specified in the program , So the instruction is decoded , It can still be decoded in the order specified in the program , It is convenient to find the correlation between instructions . Instruction cache is a necessary part of superscalar processor , There are two reasons :
(1) In many superscalar processing , The number of instructions that can be fetched per cycle is greater than the number of instructions that can be decoded per cycle , So even in I-Cache When it's missing , There are still some spare instructions in the instruction cache , If I-Cache The lack of can be quickly solved , Basically, it won't cause the pipeline to pause .
(2) In superscalar processors , Even if the number of fetch instructions per week is equal to the number of decoded instructions per cycle , For example, it's all 4 Orders , In the decoding stage of pipeline, there are some special instructions to be processed , This time, all the instructions obtained in the instruction fetching stage cannot be processed in the decoding stage . For example, the multiply accumulate instruction has two destination registers , In order to reduce the impact on the register rename stage , Will split it into two ordinary instructions , Each instruction has only one destination register , therefore , Once the instruction obtained in the instruction fetching stage includes the multiply accumulate instruction , If not handled , This will result in more instructions after decoding than 4 strip , The processing capacity of the subsequent pipeline is processed according to each cycle 4 Instructions to design , It is impossible to increase the processing capacity of AKI's subsequent pipeline because of this unusual situation , This will take up more silicon area , Therefore, it is necessary to process multiply accumulate instructions in the decoding stage .
A compromise in the limitations of superscalar processors is not to add hardware complexity for rare situations . Because of these limitations , In each cycle , The instructions sent in the fetch stage may not be able to be fully decoded in the decoding stage , So we need a place to store these instructions that cannot be decoded , This place is instruction cache , Use it , It can make the design of the decoding part more flexible .
Because the instruction cache can write multiple instructions per cycle , You can also read multiple instructions , So it is a multi port FIFO, Actually, overlap is used interleaving The way , Use multiple single port SRAM To achieve , Thus avoiding the use of multiple ports SRAM The resulting hardware and speed constraints .
6.2 General situation
MIPS Instructions generally include two source registers Rs and Rt And a destination register Rd;ARM Instructions generally include three source registers Rn,Rs and Rm And a destination register Rd, The situation is far more than that , Some special cases are :
(1) For conditionally executed instructions , It also includes the fourth source register , That is to say CPSR.
(2) All instructions that change the status register , It also includes a second destination register , namely CPSR.
(3) For forward and backward indexed load/store Instructions , It also includes the second destination register , That is, the register used as the address , When the instruction execution is completed , In addition to writing normal data to the destination register , You also need to update the contents of the address register .
(4) There are also very different LDM/STM Instructions , It includes an indefinite number of destination registers and source registers .
In the above special case , The first two are reflected in CPSR register , It can be used as a source register , It can also be used as a destination register . In superscalar implementations , If you will CPSR Register is treated as an ordinary register , So at this time ARM Each instruction of includes four source registers and two destination registers , This pair of registers is renamed register renaming The mapping table of the process is very influential , Originally, the number of ports in the mapping table is already large , Area and speed are difficult to optimize , If you are adding additional ports , Then the situation will be even worse ; and CPSR The width of the register is only 4 position (N,C,Z,V), The general purpose register is 32 position , If you will CPSR Registers and general registers are treated in a unified way , Many registers will not be used effectively ,32 Bit registers are loaded only 4 A data . Considering these limitations , In general, they will CPSR Registers are handled separately , by CPSR Register sets a separate physical register stack Physical register file, Used to store renamed CPSR register , And use a separate mapping table mapping table To manage .
about (3) and (4) The particularity embodied is , Split these special instructions into several ordinary RISC Instructions , In this way, general hardware can be used to process these special instructions , In superscalar processors , The number of source registers and destination registers carried by an instruction directly determines the difficulty of implementing the register renaming circuit , For example, the number of ports in the mapping table , The complexity of the correlation check circuit between instructions .
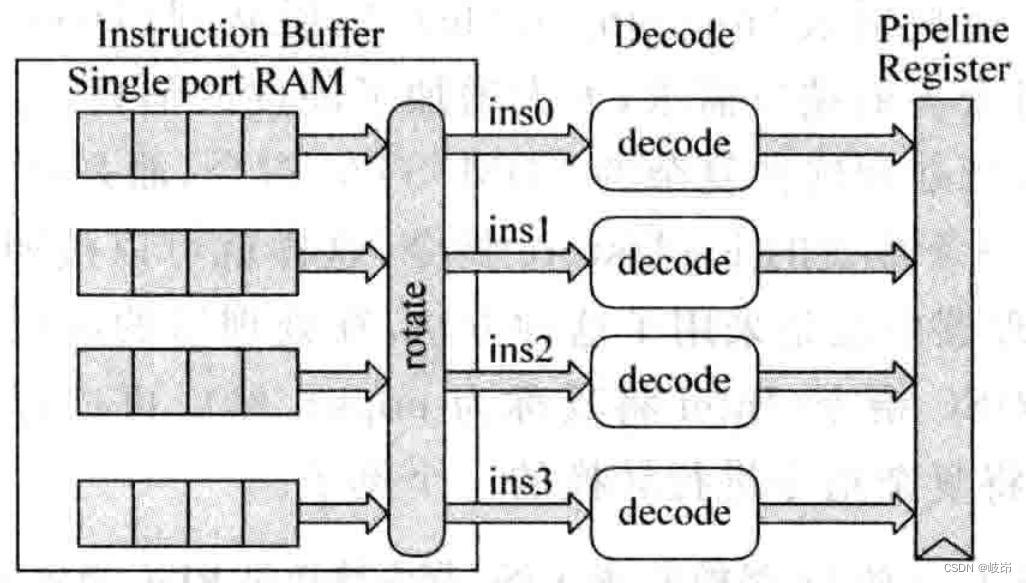
In general , From the instruction cache every week instruction buffer Read multiple instructions in . Read from instruction cache 4 This instruction is not necessarily 4 Word alignment , This requires that 4 The instructions are sorted according to the original order in the program , Send it to the decoding circuit for decoding , This is a problem that must be considered for multi port memory with overlapping structure .
because RISC The instructions are relatively regular , It's easy to find the opcode in the instruction op And operands operand, There will also be less pipeline control signals generated in the decoding stage , therefore RISC The decoding of the processor can generally be completed in one cycle , prominent RISC Adhering to simplify the complexity of hardware design through simplified instruction set , To get better performance .
RISC The tasks of processing in decoding and decoding can be summarized as three what, They are explained as follows :
(1)what type, For example, arithmetic instruction , Access memory instruction or branch instruction ;
(2)what operation, For example, what arithmetic operations are performed when arithmetic instructions
(3)what resource, For example, for arithmetic instructions , The source and destination registers are those , Whether there is an immediate number in the instruction .
6.3 A special case
about RISC Special instructions in , for example LDM/STM Come on , It takes multiple cycles to complete , And their purpose / There are multiple source registers , If they are treated as normal instructions in the excessive processor , Will make the mapping table mapping table、 Launch queue issue queue And reorder cache ROB And other components face many port requirements , It greatly increases the hardware consumption , And reduce the speed , Therefore, complex LDM/STM Instructions , Instead, they are converted into multiple simple instructions .
stay x86 Command set , It allows a number in the instruction to come from the memory , This is also CISC A feature of instructions , And in order to facilitate the correlation check between the instructions accessing the memory , Will store Instructions are split into STA and STD Two instructions ,STA Instructions are used to calculate addresses , and STD Instructions are used to find data .
No matter for CISC The instruction set is still RISC Instruction set , Using more complex instructions can achieve higher code density and lower I-Cache Absence rate . But in superscalar processors, these complex instructions introduce additional trouble , More hardware resources are needed to process them . At first, the implementation of superscalar was not considered when designing these complex instructions , for example ARM Instruction set is designed to be used in ordinary scalar scalar Designed for assembly line ,x86 Was born in the compiler compiler A very underdeveloped era , Hardware is needed to take on more responsibilities .
In today's high-performance applications , The code density sword has been rusted , Lost its charm .
and ARM These complex instructions in the instruction set need to consume more silicon resources to implement , This leads to an increase in power consumption , Contrary to the low-power design vision .
In the new ARMv8 Command set ,LDM/STM Such complex instructions have been cut down , And the number of general registers also becomes 32 individual , There is no longer an instruction embedded shift operation , Conditional execution is also limited to a few instructions .
6.3.1 Processing of branch instructions
use Checkpoint To restore the state of the processor whose branch prediction failed , In order to reduce the complexity of branch number assignment circuit , It is necessary to limit the number of branch instructions decoded per cycle , For example, there is at most one branch instruction .
A simple solution to multiple branch instructions , That is, when a branch instruction is encountered , The instruction after this branch instruction is not decoded in this cycle , Instead, put them in the next cycle , This function only needs to change the read pointer of the instruction cache .
If based on ROB Method to restore the state of the processor when branch prediction fails , It is no longer necessary to assign numbers .
There is another important task in the decoding stage , It is to preliminarily check whether the branch prediction is correct , The sooner we find the wrong branch prediction , Punishment caused penalty The smaller it is , Some branch instructions of direct jump type can calculate the target address in the decoding stage , Therefore, whether the target address of these branch instructions is correct can be checked in the decoding stage .
The branch instruction cannot get the actual direction in the decoding stage ( except Jump Instructions , Because it always jumps , Generally, there is no prediction error ), Because the direction of branch prediction cannot be checked in the decoding stage , This needs to wait until the subsequent assembly line stage .
6.3.2 Multiply and accumulate / Processing of multiplication instructions
Generally speaking , The simpler the instruction , The easier it is to implement in superscalar processors .MIPS The special instruction in multiply accumulate and multiply is a special instruction , Its special feature is that the instruction includes two destination registers , And it is not a general register .
Multiplication and destination registers have two destination registers , Unconventional situations bring trouble to rename circuits . More Than This , If you multiply and accumulate this . The multiplication instruction is put directly into ROB in , be ROB You need to be able to store two destination registers , This unconventional situation has also increased ROB The area of , And because most instructions are not multiply accumulate instructions , therefore ROB Most of the time, the part added in is unused , Adopt the following two parts to solve this problem :
(1) Register Hi and Lo Assigned to MIPS Deal with 33 And 34 General registers , Of course, this process cannot be seen in the instruction set , This allocation is only done inside the processor , The remapping table of register renaming process also needs to be supported accordingly 34 General registers .
(2) Multiply / The multiply accumulate instruction is split into two instructions .
These two instructions are renamed and written to ROB in , It will occupy ROB Two table entries of entry, You need to read four source registers , Two destination registers . In fact, inside the processor , The split multiply accumulate instruction does not complete the operation alone , But in the pipeline execution stage , Still complete the operation with a complete multiply accumulate instruction , Therefore, instruction splitting is only more conducive to register renaming , And convenient for ROB In the store , Each split instruction does not operate separately .
Of course , To achieve the above functions , You also need to check the transmission queue issue queue Do special treatment , Use one operation unit for multiply instruction and multiply accumulate instruction Function Unit, This FU The launch queue of is different from others , It includes four source operands , Two destination registers . Instructions that are split in the decoding phase , After renaming the register , Will be written to ROB And in the launch queue , This stage is Dispatch, Write at this time ROB Is still written in the form of two instructions , occupy ROB Two continuous spaces in ; When writing the launch queue , Is to fuse the two instructions , These two instructions become a complete multiply accumulate or multiply instruction in the transmit queue , So you can make sure FU At the time of execution , Can execute a complete multiply accumulate or multiply instruction .
The four instructions decoded in one cycle include multiply accumulate instructions , Adopt the following two methods to solve ;
Method 1 : Add a cache between the decoding phase and the register renaming phase , Use it to replace the pipeline register , Temporarily store the instruction information generated in the decoding stage . however , Because instructions will get a lot of information after decoding , For example, the control signal light of the assembly line , The bit width required for this cache is very large , To a certain extent, it increases the hardware area .
Method 2 : Limit the number of decodes per cycle , Once the multiply accumulate instruction is found in the decoding stage , for example MADD, Then only in MADD1 Instructions and their predecessors can be decoded , stay MADD2 And subsequent instructions need to wait until the next cycle before decoding .
6.3.3 Processing of pre and post indexing instructions
stay ARM There is also an addressing mode of fore-and-aft indexing in the instruction set , Able to complete two tasks in one instruction , Ordinary pipeline processors are easy to implement , But in superscalar implementations , It will cause extra trouble . for example ARM One of the load Instructions :
LDR R2,[R1,#4];
This instruction performs two operations , That is, the address from memory [R1+4] Put the data in the register R2 in , And use the register as the address R1 Updated to R1+4 Value . At this time, the destination register includes R1 and R2, The two destination registers will cause trouble for register renaming and later, such as wakeup , Because when implementing superscalar processors , This complex... Will still be built inside the processor load The instruction is split into two ordinary instructions .
A common one load Instructions implement load The function of data ;
An addition instruction , Used to change the address register .
This splitting process is completed in the decoding stage ,
Implement the same functionality ,ARM The processor takes up less instruction memory space , bring ARM To deal with the I-Cache miss rate lower than MIPS processor ; however ARM You need to use hardware inside the processor to split instructions , This requires more silicon area , It also leads to an increase in power consumption .
6.3.4 LDM/STM Processing of instructions
STM The instruction saves the contents of multiple registers in a continuous space in memory ,LDM Instructions can load data from a contiguous address space in memory into multiple registers , In superscalar processors , You need to split them into several ordinary load/store Instructions . for example LDM Instructions ;
LDM R5!, {R0~R3}
This instruction will store the data of four addresses in memory memory[R5],memory[R5+4],memory[R5+8],memory[R5+12] Read R0,R1,R2,R3 in , And will be used as the address register R5 Update to the new value R5+12, Therefore, this instruction is equivalent to completing five tasks . The decoding phase of the superscalar processor splits it into 4 Ordinary load Instructions and a common add Instructions .
LDR R0, #0[R5]
LDR R0, #4[R5]
LDR R0, #8[R5]
LDR R0, #12[R5]
ADD R5, R5,12
After splitting ,LDM Instructions still need multiple cycles to complete , And this kind of splitting requires some logic circuits , And have a negative impact on the cycle time of the processor .
Why do you want to start with the lowest bit of the register list , Search in sequence ? This is because in the LDM/STM In the instruction , Registers correspond to a continuous address space in memory in order of the number from small to large , Therefore, the registers in the register list must be found in order , Can be correctly corresponding to the address of the memory .
6.3.5 Processing of conditional instructions
stay ARM in , In the encoding of each instruction ,Bit[31:28] Used as a condition code , Used to judge the current CPSR Whether the value in the register is the desired value , So as to determine whether this instruction is executed .
ARM In the processor , The nature of conditional execution will CPSR Register is also treated as a source destination register , When the execution of an instruction needs to change the status register ,CPSR As a destination register , When an instruction requires conditional execution , Status register CPSR As the source register .
Instructions in superscalar processors are executed out of order , The instruction executed by the condition reads CPSR The contents of registers are not necessarily what you want .
In the superscalar register ARM In the processor , It is necessary to deal with the implementation of conditions . When an instruction is to be rewritten CPSR When the register , Use a new CPSR Register to save the state of this instruction , And give this CPSR Register is given a new name , The corresponding conditional execution instructions will use this new CPSR Register as one of their source registers .
边栏推荐
- Wuzhicms code audit
- 超标量处理器设计 姚永斌 第7章 寄存器重命名 摘录
- 新享科技发布小程序UniPro小优 满足客户移动办公场景
- 居家打工年入800多万,一共五份全职工作,他还有时间打游戏
- Rainfall warning broadcast automatic data platform bwii broadcast warning monitor
- Is it safe for Bank of China Securities to open an account online?
- What is low code development?
- leetcode:421. The maximum XOR value of two numbers in the array
- Dynamic programming stock problem comparison
- RecastNavigation 之 Recast
猜你喜欢

Chow Tai Fook fulfills the "centenary commitment" and sincerely serves to promote green environmental protection
超标量处理器设计 姚永斌 第5章 指令集体系 摘录

Firewall basic transparent mode deployment and dual machine hot standby
公司要上监控,Zabbix 和 Prometheus 怎么选?这么选准没错!

整理混乱的头文件,我用include what you use
Developers, MySQL column finish, help you easily from installation to entry
Talk about seven ways to realize asynchronous programming
NFT流动性市场安全问题频发—NFT交易平台Quixotic被黑事件分析
To sort out messy header files, I use include what you use

码农版隐秘的角落:作为开发者最讨厌的5件
随机推荐
长城证券安全不 证券开户
Offline and open source version of notation -- comprehensive evaluation of note taking software anytype
Dynamic programming stock problem comparison
Hidden corners of coder Edition: five things that developers hate most
超标量处理器设计 姚永斌 第5章 指令集体系 摘录
51 single chip microcomputer temperature alarm based on WiFi control
Master the use of auto analyze in data warehouse
【Go ~ 0到1 】 第六天 文件的读写与创建
一文掌握数仓中auto analyze的使用
正则表达式
利用win10计划任务程序定时自动运行jar包
Image retrieval
Is it safe to open an account online
缓存穿透、缓存击穿、缓存雪崩分别是什么
Redis 的内存淘汰策略和过期删除策略的区别
[template] [Luogu p4630] duathlon Triathlon (round square tree)
Detectron2 installation method
NFT liquidity market security issues occur frequently - Analysis of the black incident of NFT trading platform quixotic
智捷云——元宇宙综合解决方案服务商
Pytorch深度学习之环境搭建