大规模预训练模型的出现,为自然语言处理任务带来了新的求解范式,也显著地提升了各类NLP任务的基准效果。自2020年,OPPO小布助手团队开始对预训练模型进行探索和落地应用,从“可大规模工业化”的角度出发,先后自研了一亿、三亿和十亿参数量的预训练模型OBERT。
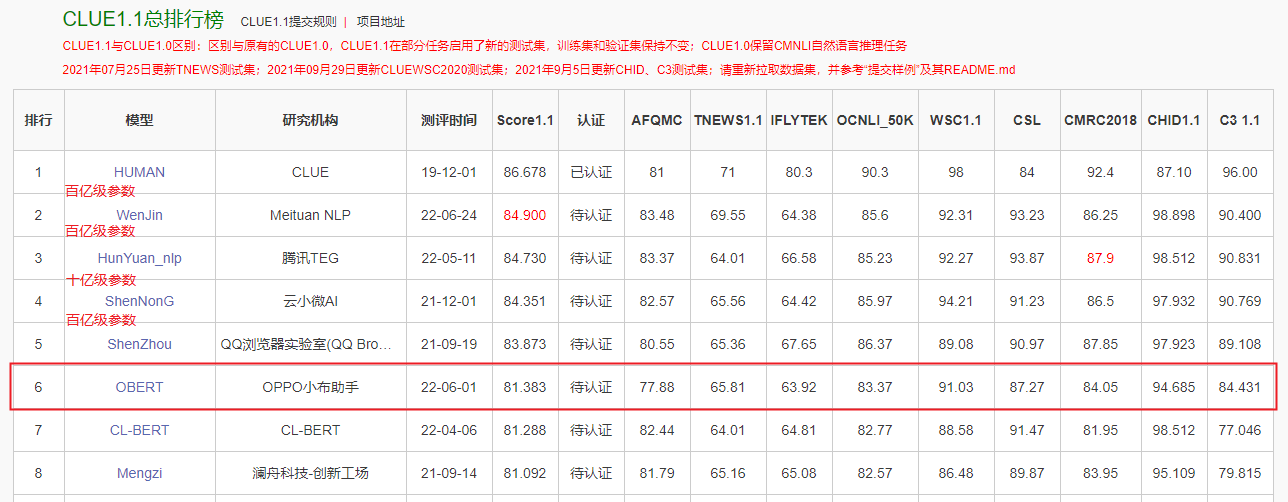
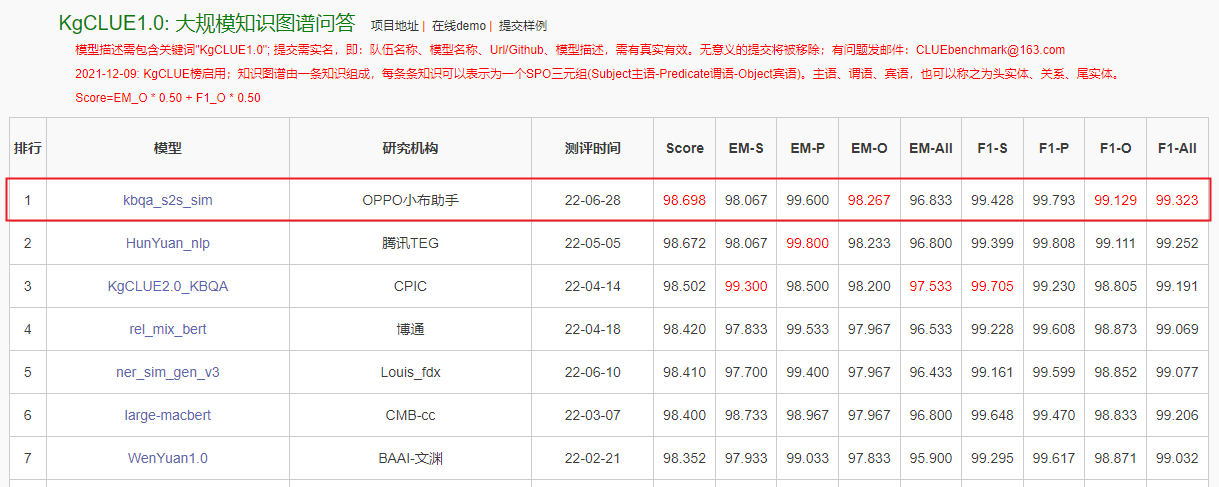
近期,OPPO小布助手团队和机器学习部联合完成了十亿参数模型“OBERT”的预训练,该模型通过5种mask机制从TB级语料中学习语言知识,在业务上取得了4%以上的提升;在行业对比评测中,OBERT跃居中文语言理解测评基准CLUE1.1总榜第五名、大规模知识图谱问答KgCLUE1.0排行榜第一名,在十亿级模型上进入第一梯队,多项子任务得分与排前3名的百亿参数模型效果非常接近,而参数量仅为后者的十分之一,更有利于大规模工业化应用。
背景
随着NLP领域预训练技术的快速发展,“预训练+微调”逐渐成为解决意图识别等问题的新范式,经过小布助手团队前期的探索和尝试,在百科技能分类、闲聊语义匹配、阅读理解答案抽取、FAQ精排等场景已经上线了自研一亿级模型并取得了显著的收益,并仍有提升的空间,验证了进一步自研十亿级模型并推广落地的必要性。
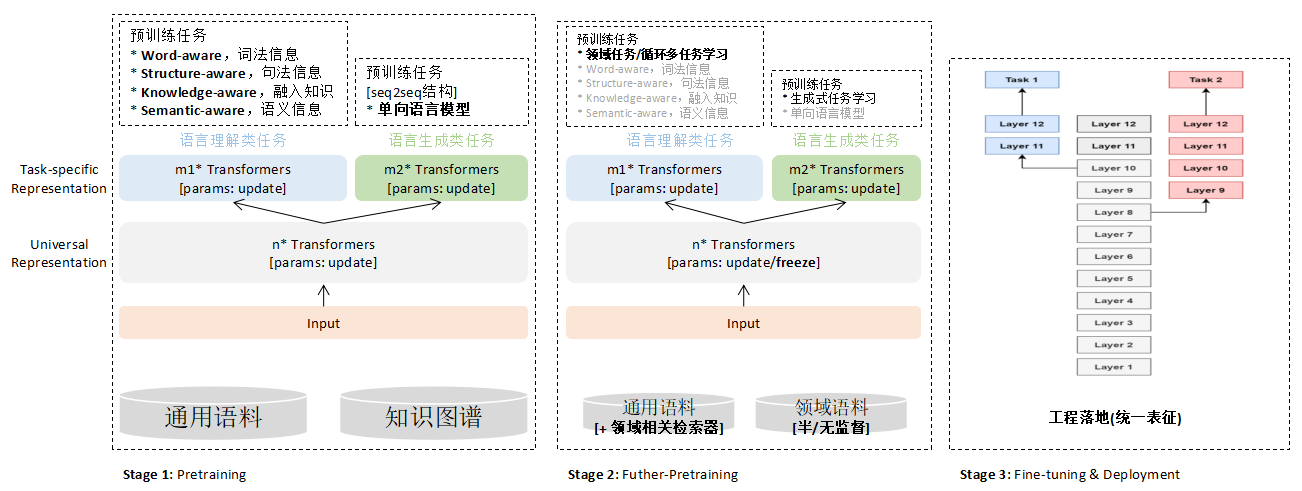
小布助手场景涉及意图理解、多轮聊天、文本匹配等NLP任务,结合工作[6,14]的经验,小布助手团队预训练到业务落地会按图3所示的方式进行,包括Pretraining、Futher-Pretraing、Fine-tuning&Deployment等阶段。主要有四个特点:
一是
表征解耦
,统一表征器适配不同下游任务,可以同时满足下游理解类任务和多轮聊天生成任务,更好地满足小布助手丰富的应用场景;
二是
检索增强
,检索对象包括知识图谱,以及目标任务相关的通用文本片段等;
三是
多阶段
,从数据、任务的维度逐步适应目标场景进行训练,平衡自监督训练和下游效果,定向获取目标场景相关的无监督、弱监督语料数据,进行进一步预训练调优;
四是
模型量级
以一亿、三亿、十亿级为主,更友好地支持大规模应用落地。
OBERT预训练模型
预训练语料
从开源工作[1]实验结果来看,语料的数量和内容多样性越大,下游任务效果会进一步提升。基于此,小布助手团队收集并清洗出1.6TB语料,内容包含百科、社区问答、新闻等。预处理过程如图4所示。在此特别感谢浪潮共享了源1.0的部分预训练语料,为OBERT模型的训练补充了更充分的数据资源。

预训练任务
得益于数据获取的低成本性和语言模型强大的迁移能力,目前NLP预训练主流的任务还是基于分布式假设的语言模型,在单向生成式语言模型(LM),前缀-单向生成式语言模型(Prefix-LM)和双向掩码语言模型(MLM)的选择上,受工作[2,3]的启发,选择了MLM作为预训练任务,因为其在下游自然语言理解类(NLU)任务上有更好的效果。

具体到mask策略,如图5,粗粒度上包括两种。
一是全词、实体、关键词、短语、短句等词句掩码,可以从不同粒度学习文本表征,是比较常用的做法。需要说明的是,mask部分与使用的上下文
Context
来自同一段落,目标如式(1)。
P
(
w
|
Context
) (1)
二是考虑外部知识增强的表征学习,与REALM[4]、内存增强[5]、ERNIE3.0[6]的做法类似,期望通过检索与输入相关的自然文本/知识图谱三元组,作为输入的扩展信息,以更好地学习文本表征。对于目前知识增强的预训练范式,主要差异点在知识库k的设置,以及知识检索方式。在OBERT的知识掩码策略中,设置了百科词条(含摘要、关键词等字段)作为知识库,相当于知识图谱中的(Entity,Description,Content)三元组信息,实体链接作为知识检索方式,具体地,给定初始文本,将文本中的实体链接到百度百科等知识库,并将其摘要文本作为上下文的补充,更充分地学习文本表征,目标如式(2)。
P
(
w
|
Context
, k
) (2)
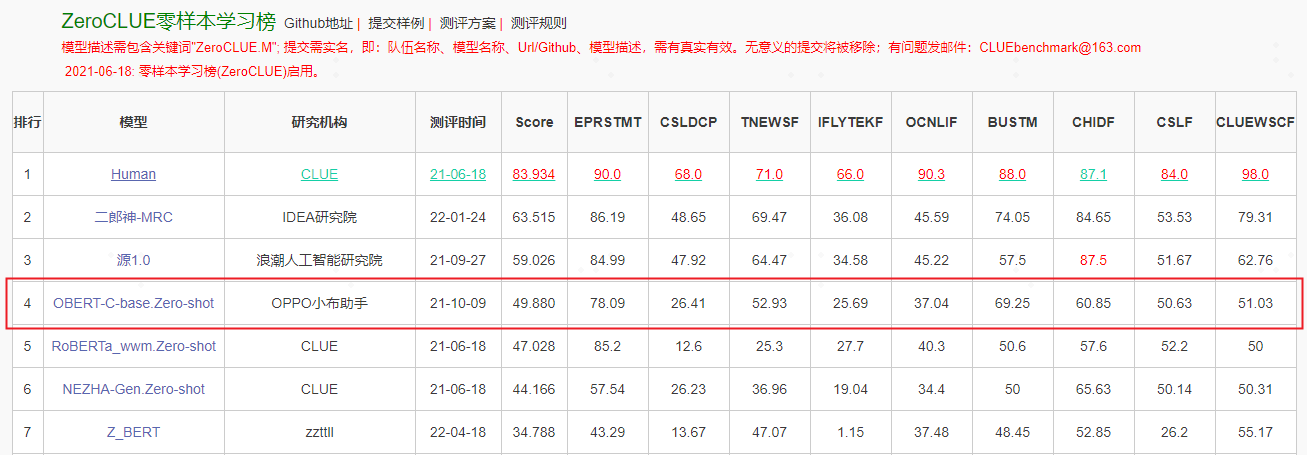
小布助手团队首先在一亿级模型上验证了上述mask策略的有效性,其Zero-shot效果显著优于开源base级模型,下游应用时也取得了收益,随后将其应用到十亿级模型训练中。
预训练策略
主要采用了课程学习,由易到难地提升训练难度,从而提高训练稳定性[7]。一方面,seqence length从64逐渐增大到512,batch size从64增加到5120;另一方面,训练初期mask策略以字词粒度为主(masked span长度小,学习难度低),逐渐增大到短语、短句粒度。
训练加速
为了加速OBERT模型的预训练,在分布式训练框架上面临两项挑战:
显存挑战:
大模型训练需要存储模型参数、梯度、优化器状态等参数,同时有训练过程产生的中间结果Activation等开销,十/百亿规模参数规模下远超常规GPU显存(V100-32GB);
计算效率挑战:
随着训练节点规模的增加,如何结合节点/网络拓扑结构和模型混合并行方式,更大程度发挥出节点的算力,保持训练吞吐量的线性/超线性拓展。
面对上述挑战,基于开源AI训练框架,OPPO StarFire机器学习平台团队研发并应用了以下方案:
1、
混合并行:
数据并行 + 模型并行 + Zero Redundancy Optimizer (ZeRO)[8];
2、
基于节点拓扑感知通信优化;
3、
梯度累积。
通过以上优化方法,相比基线训练方案取得29%+的训练吞吐量提升,可以更快速地进行OBERT模型的训练迭代,同时也使得百亿甚至更大规模参数模型的预训练变得可行与高效。
微调策略
CLUE1.1任务
小布助手团队围绕预训练模型开发了微调框架,包含了FGM[9]、PGD[10]、R-Drop[11]、Noise-tune[12]、Multi-Sample Dropout[13]等提升微调鲁棒性的方式,也包含为下游主任务增加词法辅助任务的配置,使用该框架,只需修改配置文件即可在文本分类、相似度、提槽等不同下游任务中使用上述优化方式,快速拿到不同优化方式的结果。
KgCLUE1.0任务
小布助手团队复用语音助手的知识问答方案,应用到KgCLUE的知识图谱问答评测任务上;在方案上,基于具有外部知识增强的OBERT大模型,融合ner+similar的pipeline方法和基于生成的方案,取得了第一名的成绩。更加难能可贵的是,小布助手仅仅使用单模型而未使用集成就达到了上述成绩。
落地方案
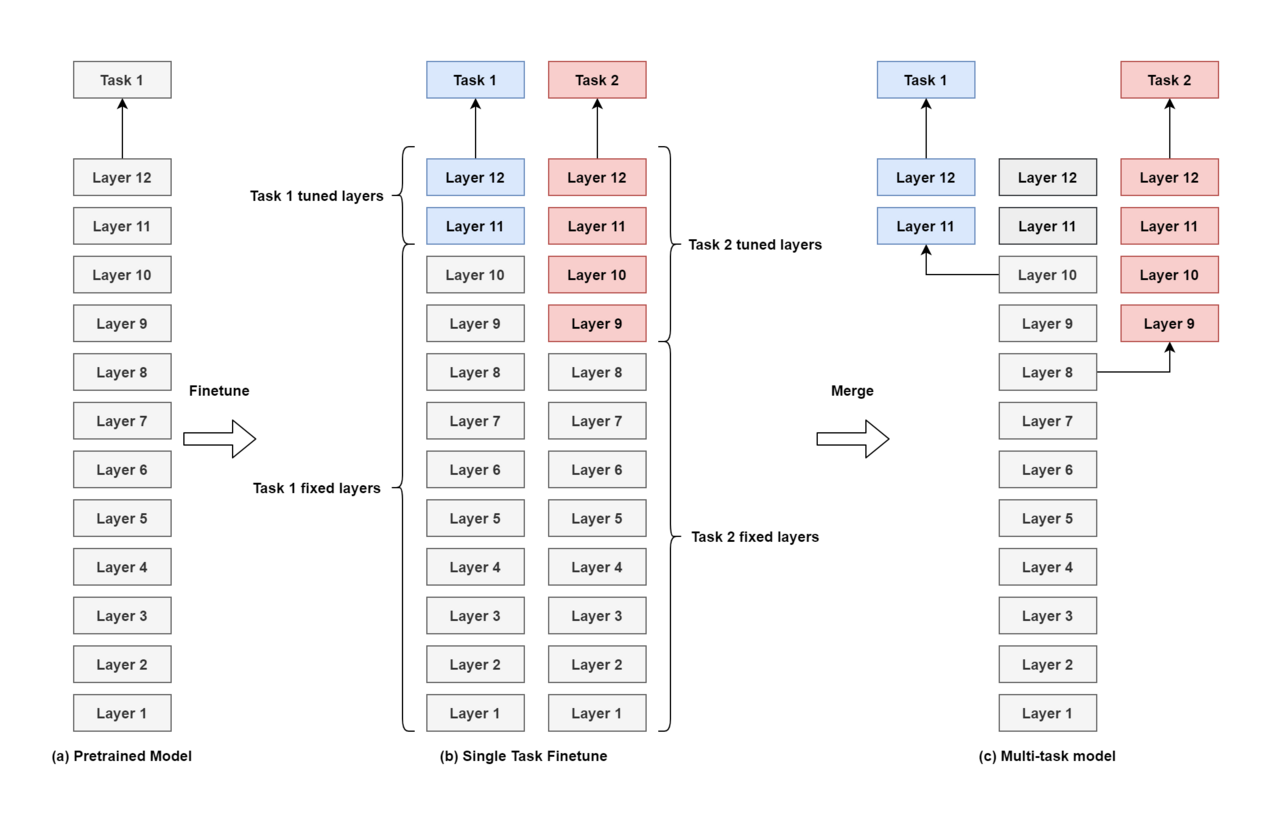
在预训练落地实践上,小布助手使用多个NLU(如知识问答NLU、系统设置NLU、闲聊NLU)来解决各种领域的问答任务,多个NLU都需要单独使用预训练做下游任务的微调,会带来巨大的GPU计算压力。
为了解决上述问题,小布助手提出统一表征方案,如下图7。该方案包括下述三个步骤:
1、
预训练
2、
多任务微调:
实践发现,为了降低全局的计算量,可以固定BERT模型的topM层transformer,只针对任务微调后N层,效果仅比全微调的最优解相差1%以内
3、
多任务合并:
推理时,在调用NLU前,先进行一次骨干网络的推理后,由各个NLU使用对应的骨干网络层作为下游任务的输入,再进行单任务的推理。
在小布助手的实践落地表明,当下游NLU为10、下游任务平均微调层数N=3时,统一表征方案下的全局计算量约为全微调方案的27%。
未来方向
小布助手团队会结合智能助手场景特点持续优化预训练技术,包括利用检索增强范式优化短文本表征、挖掘和利用反馈信息构建无监督预训练任务、以及探索模型轻量化技术加速大模型的落地等。
团队简介
OPPO小布助手团队以小布助手为AI技术落地的关键载体,致力于提供多场景、智慧有度的用户体验。小布助手是OPPO智能手机和IoT设备上内置的智能助手,包含语音、建议、指令、识屏和扫一扫五大能力模块。作为多终端、多模态、对话式的智能助手,小布助手的技术覆盖语音识别、语义理解、对话生成、知识问答系统、开放域聊天、推荐算法、数字人、多模态等多个核心领域,为用户提供更友好自然的人机交互体验。小布助手的技术实力在技术创新及应用上始终保持领先,当前已在多个自然语言处理、语音识别相关的行业权威赛事及榜单中获得亮眼成绩。
OPPO机器学习团队致力于利用ML技术构建一体化平台,提升AI工程师的全链路开发体验。面向OPPO开发者,提供轻量化、标准的、全栈式的人工智能开发服务平台,在数据处理、模型构建、模型训练、模型部署、模型管理的全链路AI开发环节提供托管式服务及AI工具,覆盖个性化推荐、广告算法、手机影像优化、语音助手推荐、图学习风控、搜索NLP等几十种落地场景,帮助用户快速创建和部署 AI 应用,管理全周期 AI 解决方案,从而助力加速数字化转型并促进 AI 工程化建设。
参考文献
[1] Cloze-driven Pretraining of Self-attention Networks
[2] Pre-trained Models for Natural Language Processing: A Survey
[3] YUAN 1.0: LARGE-SCALE PRE-TRAINED LANGUAGE MODEL IN ZERO-SHOT AND FEW-SHOT LEARNING
[4] REALM: Retrieval-Augmented Language Model Pre-Training
[5] Training Language Models with Memory Augmentation
[6] ERNIE 3.0: LARGE-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION
[7] Curriculum Learning: A Regularization Method for Efficient and Stable Billion-Scale GPT Model Pre-Training
[8] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
[9] FGM: Adversarial Training Methods for Semi-Supervised Text Classification
[10] Towards Deep Learning Models Resistant to Adversarial Attacks
[11] R-Drop: Regularized Dropout for Neural Networks
[12] NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better
[13] Multi-Sample Dropout for Accelerated Training and Better Generalization
[14] Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://xie.infoq.cn/article/8e4c79e60493889c5b66f3393