当前位置:网站首页>Rhcsa learning practice
Rhcsa learning practice
2022-07-04 10:17:00 【Attiude】
1. Use whereis lookup locate command
Use which lookup whereis command
Use locate lookup rm command
[[email protected] ~]# locate -c rm
5228
[[email protected] ~]# whereis locate
locate: /usr/bin/locate /usr/share/man/man1/locate.1.gz
[[email protected] ~]# which whereis
/usr/bin/whereis2.find Command to use : Use find Command to find all ordinary files in the current path Use find Command to find... In the current path file1.txt,file2.txt,file3.txt Use find The command to find the file owner is root The ordinary documents of Use find The command search modification time is 1 Ordinary documents within days
[[email protected] ~]# find -type f # All text files
[[email protected] ~]# find -type l # All linked files
[[email protected] ~]# find find_test1 find_test2 find_test3
find_test1
find_test2
find_test3
[email protected] ~]# find -user root | find -type l # Find the user as root Common files under
[[email protected] ~]# find -mtime -1 |find -type l # Documents modified within one day 3.cut Command to use : Given the file cut_data.txt And the content is : No Name Score 1 zhang 20 2 li 80 3 wang 90 4 sun 60 Use the default delimiter to cut the contents of the file , And output the first field after cutting Cut file content , And output the first field and the third field after cutting Cut by byte : Output the first byte to the second byte of the cut 10 Bytes of content Cut by character : Output the first character and the second character after cutting 5 The content of a character Cut according to the specified delimiter : The contents are as follows , Output the contents of the first field and the third field No|Name|Score 1|zhang|20 2|li|80 3|wang|90 4|sun|60
[[email protected] ~]# cut -s -f1 cut_data.txt
[[email protected] ~]# cut -s -f1,3 cut_data.txt
[[email protected] ~]# cut -b 1-10 cut_data.txt
[[email protected] ~]# cut -c 1-5 cut_data.txt
[[email protected] ~]# cut -d"|" -f 1,3 cut_data.txt
4.uniq Command to use : New file uniq_data.txt, The content of the document is Welcome to Linux Windows Windows Mac Mac Linux Use uniq The command outputs the result after de duplication Use uniqmingl Output only duplicate lines Use uniq The command outputs non repeating lines Use uniq The command counts the number of repetitions
[[email protected] ~]# uniq uniq_data.txt
[[email protected] ~]# uniq -d uniq_data.txt
[[email protected] ~]# uniq -u uniq_data.txt
[[email protected] ~]# uniq -c -d uniq_data.txt5.sort command : Given the file num.txt, args.txt The contents of the document :num.txt 1 3 5 2 4 The contents of the document :args.txt test args1 args2 args4 args4 args3
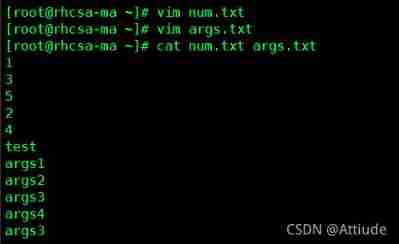
Yes num.txt Sort , And output the results to sorted_num.txt in
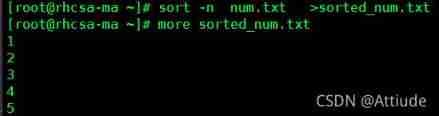
[email protected] ~]# sort -n num.txt > sorted_num.txtYes args.txt Sort , And output the results to sorted_args.txt in
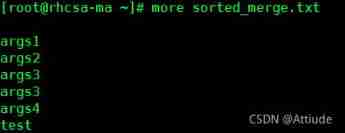
[[email protected] ~]# sort -n args.txt > sorted_merge.txtYes num.txt and args.txt Sort , And output the results to sorted_merge.txt in
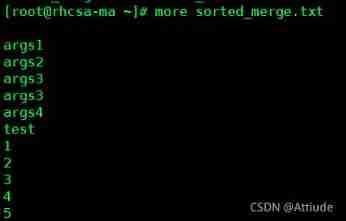
[[email protected] ~]# sort -n args.txt num.txt > sorted_merge.txtYes args.txt After sorting, de re output
[[email protected] ~]# sort -n -u args.txtMerge sorted_args.txt and sorted_num.txt And output
[[email protected] ~]# sort args.txt num.txt Given the file info_txt: Press the second column as key Sort No Name Score 1 zhang 20 2 li 80 3 wang 90 4 sun 60
[[email protected] ~]# sort -n -k 2 info.txt6. take 26 After a lowercase letter 13 Replace the first letter with a capital letter
![]()
take hello 123 world 456 Replace the numbers in with empty characters ( Prompt to use wildcards )
![]()
take hello 123 world 456 Replace letters and spaces in , Just keep the numbers ( Prompt to use wildcards )
![]()
7.wc Command to use : Given the file :word_count.txt, It's filled with 10 Row content Count by byte Count by word Count by
[[email protected] ~]# wc -l word_count.txt # Count by
10 word_count.txt
[[email protected] ~]# wc -w word_count.txt # Count by word
11 word_count.txt
[[email protected] ~]# wc -c word_count.txt # Count by byte 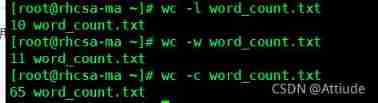
边栏推荐
- Es advanced series - 1 JVM memory allocation
- MongoDB数据日期显示相差8小时 原因和解决方案
- 2. Data type
- The future education examination system cannot answer questions, and there is no response after clicking on the options, and the answers will not be recorded
- Some summaries of the third anniversary of joining Ping An in China
- Go context basic introduction
- Sword finger offer 31 Stack push in and pop-up sequence
- C language pointer classic interview question - the first bullet
- The time difference between the past time and the present time of uniapp processing, such as just, a few minutes ago, a few hours ago, a few months ago
- Latex error: missing delimiter (. Inserted) {\xi \left( {p,{p_q}} \right)} \right|}}
猜你喜欢

Application of safety monitoring in zhizhilu Denggan reservoir area

对于程序员来说,伤害力度最大的话。。。

Hands on deep learning (43) -- machine translation and its data construction

转载:等比数列的求和公式,及其推导过程

libmysqlclient.so.20: cannot open shared object file: No such file or directory
Debug:==42==ERROR: AddressSanitizer: heap-buffer-overflow on address
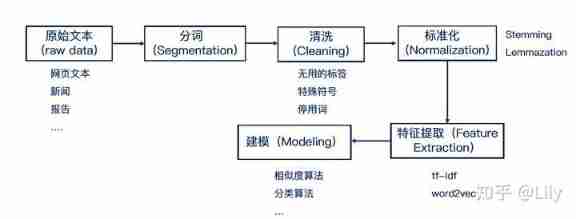
Hands on deep learning (35) -- text preprocessing (NLP)
What are the advantages of automation?
Reasons and solutions for the 8-hour difference in mongodb data date display
Dynamic memory management

随机推荐
【Day2】 convolutional-neural-networks
Batch distribution of SSH keys and batch execution of ansible
Mmclassification annotation file generation
Kotlin:集合使用
If the uniapp is less than 1000, it will be displayed according to the original number. If the number exceeds 1000, it will be converted into 10w+ 1.3k+ display
Hands on deep learning (III) -- Torch Operation (sorting out documents in detail)
Hands on deep learning (37) -- cyclic neural network
View CSDN personal resource download details
今日睡眠质量记录78分
5g/4g wireless networking scheme for brand chain stores
Summary of reasons for web side automation test failure
uniapp 小于1000 按原数字显示 超过1000 数字换算成10w+ 1.3k+ 显示
System. Currenttimemillis() and system Nanotime (), which is faster? Don't use it wrong!
Kubernetes CNI 插件之Fabric
Doris / Clickhouse / Hudi, a phased summary in June
Golang Modules
2020-03-28
原生div具有编辑能力
MySQL case
用数据告诉你高考最难的省份是哪里!