当前位置:网站首页>Redis notes (14) - persistence and data recovery (data persistence RDB and AOF, data recovery, mixed persistence)
Redis notes (14) - persistence and data recovery (data persistence RDB and AOF, data recovery, mixed persistence)
2022-06-26 09:45:00 【wohu1104】
1. Persistence
Persistence refers to synchronizing data from memory to hard disk in some form , stay Redis Data can be recovered according to the records in the hard disk after restart .Redis There are two ways to persist , Respectively RDB(redis data base) 【 snapshot 】 The way and AOF(append only file ) 【 journal 】 The way .
Redis There are two persistence mechanisms , Respectively :
- snapshot
RDB, Snapshot is a full backup , Is the binary serialized form of memory data , Very compact on storage ; - journal
AOF, Log is a continuous incremental backup , What the log records is the instruction record text of memory data modification ;
AOF The log will become huge in the long run , The database needs to be loaded when it is restarted AOF Log for instruction replay , This time will be very long . So it needs to be done on a regular basis AOF rewrite , to AOF Keep your weight down .
Difference between them :
RDBPersistence refers to writing the data set snapshot in memory to disk within a specified time interval , The actual operation process isforkA subprocess , Write the dataset to the temporary file first , After writing successfully , Replace the previous file , Compress storage with binary .AOFPersistence logs every write processed by the server 、 Delete operation , The query operation will not record , Record as text , You can open the file to see the detailed operation record .
2. RDB
2.1 RDB 【 snapshot 】 The way
RDB Persistence is Redis Default support for , No need to configure .RDB It refers to writing the data set snapshot in memory to disk within a specified time interval . When certain rules are met ,Redis Automatically generate a copy of all data in memory and store it on the hard disk . It can be divided into the following four situations :
Automatically take snapshots according to configuration rules
SAVE 900 1 SAVE 300 10 SAVE 60 1000SAVE 900 1Express 900s If one or more keys are changed in the snapshot configuration file .User execution
SAVEorBGSAVEcommand(1)
SAVEcommandRedisThe snapshot operation will be synchronized , All requests from clients will be blocked during snapshot execution .(2)
BGSAVEcommandRedisSnapshot operations will be performed asynchronously in the background , During snapshot execution, the server can continue to respond to requests from the client . The specific operation isRedisProcess executionforkAction create subprocess ,RDBThe persistence process is the responsibility of the subprocess , It will automatically end when it is finished . The blockage only happens inforkStage , The average time is very short . It is recommended to use .perform
FLUSHALLcommandAs long as the snapshot configuration condition is not empty , When this command is executed, a snapshot operation will be executed ; When no snapshot condition is defined , Even if this command is executed, the snapshot operation will not be executed .
Perform replication
replicationEven if no auto snapshot conditions are defined , And no snapshot operation has been performed manually , Automatic snapshots are also taken during replication operations .
2.2 RDB 【 snapshot 】 principle
Redis stay RDB When persisting, it will call glibc Function of fork Generate a subprocess , Snapshot persistence is completely left to the child process to handle , The parent process continues to process client requests . When the subprocess was just generated , It shares code and data segments in memory with the parent process . This is a Linux The mechanism of the operating system , In order to save memory resources , So try to share them as much as possible . In the moment of process separation , Memory growth has barely changed .
use Python The logic of process separation described by the language is as follows .fork Function will return at the same time as the parent and child processes , Returns the name of the child process in the parent process pid, Returns zero in the child process . If the operating system is low on memory resources ,pid It will be negative , Express fork Failure .
pid = os.fork()
if pid > 0:
handle_client_requests() # The parent process continues to process client requests
if pid == 0:
handle_snapshot_write() # Subprocess processing snapshot write disk
if pid < 0:
# fork error
Subprocesses do data persistence , It does not modify the existing memory data structure , It's just a traversal read of the data structure , And save outdated data , Then serialization is written to disk . But the parent process is different , It must continuously serve client requests , Then the memory data structure is modified continuously .
I will use the operating system at this time COW(Copy On Write) Mechanism to separate data segment pages . Data segments are a combination of pages from many operating systems , When the parent process modifies the data of one of the pages , A copy of the shared page will be copied and separated , Then modify the copied page . At this time, the corresponding page of the subprocess does not change , Or the data at the moment when the process is generated .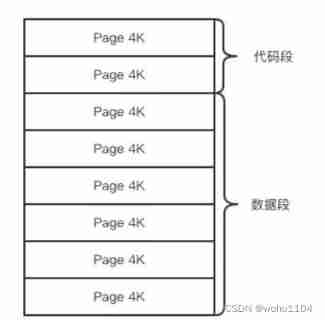
As the modification of the parent process continues , More and more shared pages are being separated , Memory will continue to grow . But it will not exceed the original data memory 2 Multiple size . Another one Redis The proportion of cold data in an example is often relatively high , So it's rare that all the pages will be detached , Often only a part of the page is separated . The size of each page is just 4K, One Redis There are usually thousands of pages in an instance .
Subprocess because the data has not changed , The data in memory that it can see solidifies in the moment of process generation , It will never change , That's why Redis The persistence of is called 「 snapshot 」 Why . Next, the subprocess can traverse the data with great ease to serialize and write to disk .
3. AOF
3.1 AOF 【 journal 】 The way
This mechanism will log every write operation processed by the server , stay Redis The server will read the file to rebuild the database at the beginning of startup , To ensure that the data in the database is complete after startup .
- Off by default , adopt
appendonly yesOpenable - After opening , Every time you execute a command to change the database ,
RedisWill write the command to the hard diskAOFfile - When certain conditions are met ,
RedisIt will be automatically rewrittenAOFfile
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
- Startup time
RedisIt will be executed one by oneAOFThe commands in the file load the data from the hard disk into memory appendfsync everysecThrough this configuration item in the configuration file , It can make the data in the hard disk cache every 1s Sync once to the real hard disk
3.2 AOF 【 journal 】 principle
In fact, due to the operating system caching mechanism , The data is not actually written to the hard disk , Instead, it enters the system hard disk cache .AOF Logs exist in the form of files , When the program is right AOF When the log file is being written , In fact, the content is written to a memory cache allocated by the kernel for file descriptors , Then the kernel will asynchronously brush the dirty data back to the disk .
This means that if the machine suddenly goes down ,AOF The contents of the log may not have been brushed to the disk completely , At this time, the log will be lost . So what do we do? ?
Linux Of glibc Provides fsync(int fd) Function to force the contents of the specified file from kernel cache to disk . as long as Redis Process real time call fsync The function guarantees aof Logs are not lost . however fsync It's a disk IO operation , It's very slow ! If Redis To execute an instruction is to fsync once , that Redis High performance status is not guaranteed .
So in the server of the production environment ,Redis Usually every 1s Do it around once fsync operation , cycle 1s It can be configured . This is a tradeoff between data security and performance , While maintaining high performance , Try to minimize data loss .
Redis Provides bgrewriteaof Instructions are used for AOF Keep your weight down . Its principle is to open up a subprocess to traverse memory and convert it into a series of Redis Operation instructions of , Serialize to a new AOF Log file . Increment occurred during operation after serialization AOF The log is appended to this new AOF Log file , Replace the old one immediately after the addition AOF The log file is missing , The job of slimming is done .
4. Data recovery
4.1 RDB The way
RDB The method of persistent data recovery does not require much operation , Just put the backup file in Redis Installation directory , Start it up .Redis The file will be automatically loaded into memory . It will be blocked all the time during loading .
advantage :
- The entire database contains only one backup file . Easy to recover and store .
- Easy to copy and transfer .
- Compared with
AOF, When the data set is large ,RDBIt's more efficient to start . - Maximize performance . about
RedisIn terms of service process , At the beginning of persistence , The only thing it needs to do isforkOut of child process , After that, the subprocess completes these persistent tasks , This can greatly avoid the service process from performing operations .
shortcoming :
- If you want to minimize data loss ,
RDBNot a good choice , If the system goes down during persistence , Any data not written to the disk will be lost . RDBadoptforkSubprocesses to assist with persistence , If the dataset is large , It will cause the server to stop for some time .
4.2 AOF The way
And RDB equally , restart Redis,Redis It will load automatically AOF file , Data recovery .
advantage :
AOFData security and synchronization ratioRDBForm high . The default is one synchronization per second , If it is set to synchronize every operation , The data will be fully synchronized .AOFFiles are generated by appending . If an exception occurs in the last write, the previous file data will not be affected .AOFThe file has a clear and readable file format , If we write the command incorrectly , Can be closed immediately , When the rewrite is not in progress , Enter the file first , Get rid of misspelled commands .
shortcoming :
AOFIt takes up more space thanRDBBig .AOFSynchronization speed ratio ofRDBslow .
5 Mix persistence
restart Redis when , We seldom use rdb To restore memory state , Because data will be lost , because rdb Not real-time data storage . We usually use AOF Log replay , But replay AOF Log performance is relative rdb It's a lot slower , In this way Redis When the examples are large , It takes a long time to start .
Redis 4.0 To solve this problem , Brings a new persistence option —— Mix persistence . take rdb The content of the file and the incremental AOF Log files exist together . there AOF Logs are no longer full logs , It's the increment from the beginning of persistence to the end of persistence AOF journal , Usually this part AOF The log is very small .
So in Redis When restarting , You can load rdb The content of , Then replay the increment AOF Log can completely replace the previous AOF Full file replay , The restart efficiency has been greatly improved .
6. How to choose
If the requirements for data integrity are not very high , A bit of data can be lost , Then choose RDB It's the best .RDB Both backup convenience and recovery speed are higher than AOF, At the same time, it can avoid AOF Some of bug.
If the requirements for data integrity are extremely high , Please select AOF form .

Reference resources :
https://juejin.cn/book/6844733724618129422/section/6844733724714614797
边栏推荐
- online trajectory generation
- Throttling, anti chattering, new function, coriolism
- SQL高级教程
- LeetCode 498. Diagonal traversal
- CVPR:Refining Pseudo Labels with Clustering Consensus over Generations for Unsupervised Object Re-ID
- How to create an IE tab in edge browser
- Several connection query methods of SQL (internal connection, external connection, full connection and joint query)
- Common circuit design
- 计算领域高质量科技期刊分级目录
- 全面解读!Golang中泛型的使用
猜你喜欢

Badge collection 6:api\_ Use of level
How to correctly open the USB debugging and complete log functions of Huawei mobile phones?

Curriculum learning (CL)

Record a time when the server was taken to mine

"One week's data collection" - logic gate
The shutter tabbar listener is called twice

The first techo day Tencent technology open day, 628

Common circuit design

"One week's work on Analog Electronics" - Basic amplification circuit

PHP extracts TXT text to store the domain name in JSON data

随机推荐
LeetCode 498. 对角线遍历
【CVPR 2021】Joint Generative and Contrastive Learning for Unsupervised Person Re-identification
[open5gs] open5gs installation configuration
【CVPR 2021】DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
[pulsar learning] pulsar Architecture Principle
Teach you to use shell script to check whether the server program is running
SQL query duplicate record
Differences between VI and vim and common commands
Record a time when the server was taken to mine
Joint Noise-Tolerant Learning and Meta Camera Shift Adaptation for Unsupervised Person Re-ID
MapReduce & yarn theory
Curriculum learning (CL)
Halcon photometric stereoscopic
c语言语法基础之——指针( 多维数组、函数、总结 ) 学习
【CVPR 2021】Intra-Inter Camera Similarity for Unsupervised Person Re-Identification (IICS++)
Badge series 5: use of codecov
2021年全国职业院校技能大赛(中职组)网络安全竞赛试题(1)详细解析教程
"One week's data collection" -- combinational logic circuit
测试须知——常见接口协议解析
QPM suspended window setting information