当前位置:网站首页>Storage, reading and writing of blood relationship data of Nepal Graph & Data Warehouse
Storage, reading and writing of blood relationship data of Nepal Graph & Data Warehouse
2022-07-02 15:56:00 【Figure database nebulagraph】
This article was first published in Nebula Graph Community official account
{kind=link}
One 、 choice Nebula Why
Superior performance
- Query speed is very fast
- Architecture separation , Easy to expand ( The current machine configuration is low , It may be extended in the future )
- High availability ( Because it's distributed , Therefore, there has been no downtime since its use )
The easier
- Full introduction ( Familiar with architecture and performance )
- The deployment of fast ( After the baptism of the manual , Quickly deploy simple clusters )
- Easy to use ( Encounter the required data , Query the manual to get the corresponding GNQL, Targeted query )
- Excellent Q & A ( Have a problem , You can turn to the forum first , without , Then post , The help of developers is timely )
Open source , And the technology is stable
- Because there are many practical enterprises , Don't worry about it .
Two 、 Business requirements background introduction
To facilitate data governance 、 Metadata management and data quality monitoring , Save the generated blood warehouse scheduling system .
Blood relationship data flow
From the collection 、 The whole process of data stored on the platform :
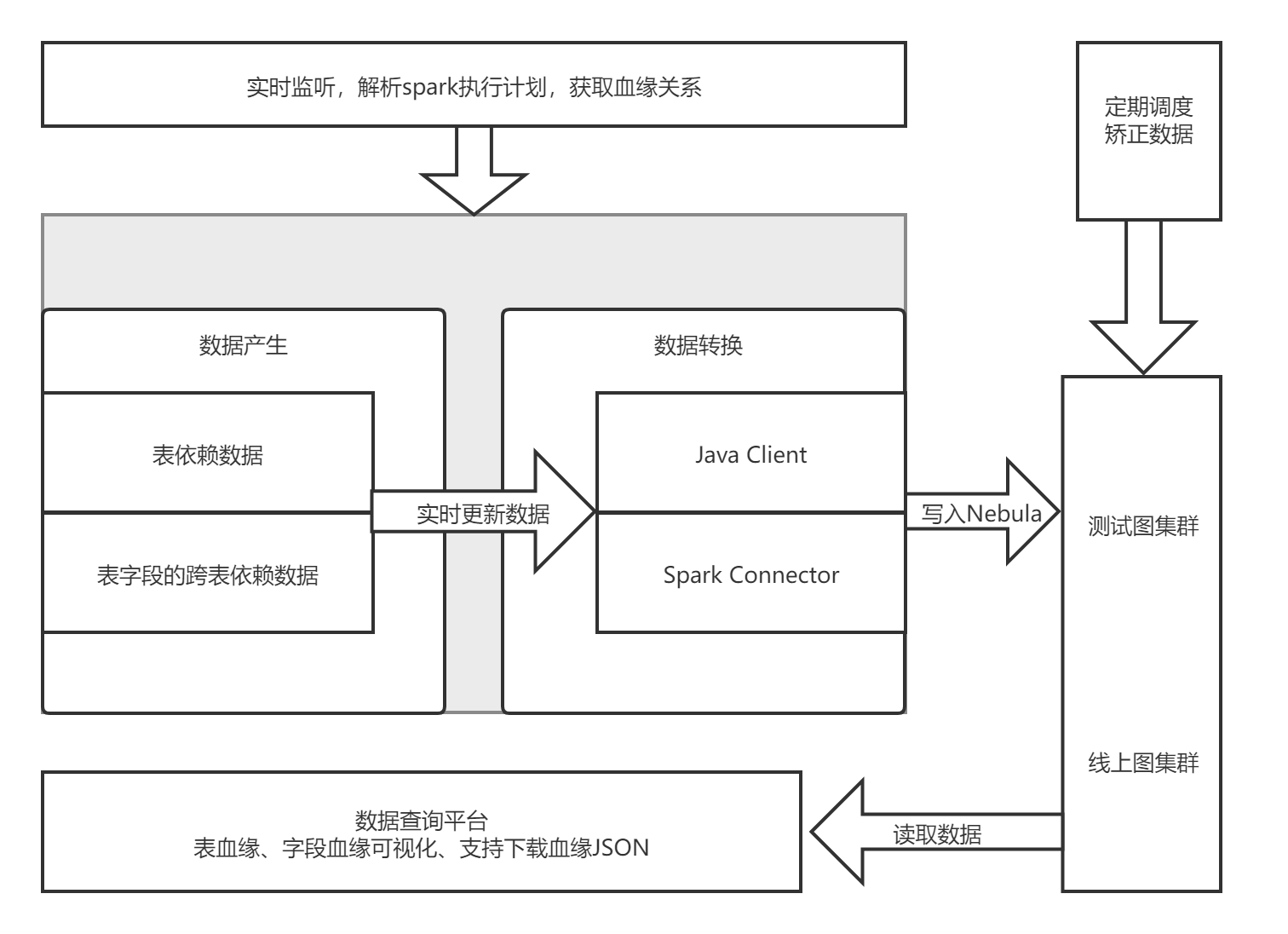
Some data query displays on the query platform

3、 ... and 、 My specific practice
1、 Version selection
Here we use Nebula v3.0.0、Nebula Java Client v3.0.0, Let's talk about Nebula Graph and Java The client needs to be compatible , The version number should be aligned .
2、 Cluster deployment
Machine configuration
Four physical machines , Same configuration :
10C * 2 / 16G * 8 / 600G
3、 Installation mode
Here we use RPM install .
a. adopt wget Pull the installation package and install .
b. Changing configuration files , Main change parameters :
- Meta All machines served
—— meta_server_addrs=ip1:9559, ip2:9559, ip3:9559
Current machine ip( If it is meta / graph / storage, Fill correspondence meta / graph / storage Mechanical ip) —— local_ip
c. Pass after startup Console A simple test add hosts ip:port Add your own machines ip after ( Kernel version is lower than v3.0.0 Of Nebula The user can ignore this step ),show hosts, If it is online, You can begin to test the relevant nGQL.
4、 Data import
At present, the data can be updated in two ways .
a. Real time monitoring and dispatching platform
Monitor each task instance , Obtain upstream and downstream relationships through dependent nodes , Push the relationship into... In real time MySQL and Nebula in , to update Nebula Graph Data is passed through Spark Connector Realization .(MySQL Make a backup , because Nebula Unsupported transaction , There may be data deviation )
b. Regular scheduling correction data
adopt MySQL Blood relationship in , adopt Spark Task timing correction Nebula data , Update data also through Spark Connector Realization .
Spark Connector Use :NebulaConnectionConfig Initialize configuration , Then through the connection information 、 Relevant parameters and entities of inserted points and edges Tag、Edge establish WriteNebulaVertexConfig and WriteNebulaEdgeConfig object , For writing point and edge data .
5、 Data platform query
Application platform of blood relationship query :
a. obtain Nebula Data implementation process
By initializing the connection pool Nebula pool, Implement the singleton tool class , Easy to call and use throughout the project Session.
It's important to be careful here , There can only be one connection pool , and Session Can pass MaxConnectionNum Set the number of connections , Judge the specific parameters according to the actual business ( The more frequent platform queries , The more connections you need to set ). And every time Session It is also released after use .
b. Query data , Convert to ECharts Needed JSON
① adopt getSubGraph Get all upstream and downstream related points of the current table or field , This is done by obtaining subgraphs , Very convenient .
② Need to pass the result , Analyze the data points in two directions , Then recursively parse , Finally, it turns into a recursive call to its own Bean Class object .
③ Write one that meets the needs of the front end JSON List of toString Method , When you get the results .
Tool classes and core logic code
Here I share the tool classes and core logic code I use
Tool class
object NebulaUtil {
private val log: Logger = LoggerFactory.getLogger(NebulaUtil.getClass)
private val pool: NebulaPool = new NebulaPool
private var success: Boolean = false
{
// First initialize the connection pool
val nebulaPoolConfig = new NebulaPoolConfig
nebulaPoolConfig.setMaxConnSize(100)
// initialization ip And port
val addresses = util.Arrays.asList(new HostAddress("10.88.100.88", 9669))
success = pool.init(addresses, nebulaPoolConfig)
}
def getPool(): NebulaPool = {
pool
}
def isSuccess(): Boolean = {
success
}
//TODO query: Create space 、 Enter space 、 Create new point and edge types 、 The insertion point 、 Insert edge 、 Execute the query
def executeResultSet(query: String, session: Session): ResultSet = {
val resp: ResultSet = session.execute(query)
if (!resp.isSucceeded){
log.error(String.format("Execute: `%s', failed: %s", query, resp.getErrorMessage))
System.exit(1)
}
resp
}
def executeJSON(queryForJson: String, session: Session): String = {
val resp: String = session.executeJson(queryForJson)
val errors: JSONObject = JSON.parseObject(resp).getJSONArray("errors").getJSONObject(0)
if (errors.getInteger("code") != 0){
log.error(String.format("Execute: `%s', failed: %s", queryForJson, errors.getString("message")))
System.exit(1)
}
resp
}
def executeNGqlWithParameter(query: String, paramMap: util.Map[String, Object], session: Session): Unit = {
val resp: ResultSet = session.executeWithParameter(query, paramMap)
if (!resp.isSucceeded){
log.error(String.format("Execute: `%s', failed: %s", query, resp.getErrorMessage))
System.exit(1)
}
}
// obtain ResultSet Column names and data in
//_1 A list of column names
//_2 many row The list of components is nested Single row A list of Contains the data for each column of the row
def getInfoForResult(resultSet: ResultSet): (util.List[String], util.List[util.List[Object]]) = {
// Get the list
val colNames: util.List[String] = resultSet.keys
// Get data
val data: util.List[util.List[Object]] = new util.ArrayList[util.List[Object]]
// Loop through each row of data
for (i <- 0 until resultSet.rowsSize) {
val curData = new util.ArrayList[Object]
// Get the number i Container for row data
val record = resultSet.rowValues(i)
import scala.collection.JavaConversions._
// Get the data in the container
for (value <- record.values) {
if (value.isString) curData.add(value.asString)
else if (value.isLong) curData.add(value.asLong.toString)
else if (value.isBoolean) curData.add(value.asBoolean.toString)
else if (value.isDouble) curData.add(value.asDouble.toString)
else if (value.isTime) curData.add(value.asTime.toString)
else if (value.isDate) curData.add(value.asDate.toString)
else if (value.isDateTime) curData.add(value.asDateTime.toString)
else if (value.isVertex) curData.add(value.asNode.toString)
else if (value.isEdge) curData.add(value.asRelationship.toString)
else if (value.isPath) curData.add(value.asPath.toString)
else if (value.isList) curData.add(value.asList.toString)
else if (value.isSet) curData.add(value.asSet.toString)
else if (value.isMap) curData.add(value.asMap.toString)
}
// Merge data
data.add(curData)
}
(colNames, data)
}
def close(): Unit = {
pool.close()
}
}
Core code
//bean next The pointer is a variable array
// Get subgraph
//field_name Start node , direct Subgraph direction (true The downstream , false The upstream )
def getSubgraph(field_name: String, direct: Boolean, nebulaSession: Session): FieldRely = {
// field_name The node
val relyResult = new FieldRely(field_name, new mutable.ArrayBuffer[FieldRely])
// out For the downstream , in For upstream
var downOrUp = "out"
// Get the direction of the current query
if (direct){
downOrUp = "out"
} else {
downOrUp = "in"
}
//1 Query statement Query all downstream subgraphs
val query =
s"""
| get subgraph 100 steps from "$field_name" $downOrUp field_rely yield edges as field_rely;
|""".stripMargin
val resultSet = NebulaUtil.executeResultSet(query, nebulaSession)
//[[:field_rely "dws.dws_order+ds_code"->"dws.dws_order_day+ds_code" @0 {}], [:field_rely "dws.dws_order+ds_code"->"tujia_qlibra.dws_order+p_ds_code" @0 {}], [:field_rely "dws.dws_order+ds_code"->"tujia_tmp.dws_order_execution+ds_code" @0 {}]]
// If it is not empty, get the data
if (!resultSet.isEmpty) {
// Non empty , Take the data , Parsing data
val data = NebulaUtil.getInfoForResult(resultSet)
val curData: util.List[util.List[Object]] = data._2
// Regular matching data in quotation marks
val pattern = Pattern.compile("\"([^\"]*)\"")
// Array of all nodes in the previous step
// Determine the parent node of the node , Convenience store
var parentNode = new mutable.ArrayBuffer[FieldRely]()
//2 First, the step size is 1 The edge of
curData.get(0).get(0).toString.split(",").foreach(curEdge =>{
// Get the start and destination of the edge
val matcher = pattern.matcher(curEdge)
var startPoint = ""
var endPoint = ""
// Assign two points
while (matcher.find()){
val curValue = matcher.group().replaceAll("\"", "")
// The directions of upstream and downstream are different Therefore, it is necessary to switch between upstream and downstream Information acquisition of start node and end node
// out For the downstream , The data structure is startPoint -> endPoint
if(direct){
if ("".equals(startPoint)){
startPoint = curValue
}else{
endPoint = curValue
}
}else {
// in For upstream , The data structure is endPoint -> startPoint
if ("".equals(endPoint)){
endPoint = curValue
}else{
startPoint = curValue
}
}
}
// Merge to starting point bean in
relyResult.children.append(new FieldRely(endPoint, new ArrayBuffer[FieldRely]()))
})
//3 And initialize the parent node array
parentNode = relyResult.children
//4 Get all the other edges
for (i <- 1 until curData.size - 1){
// Save the parent node set of the next step
val nextParentNode = new mutable.ArrayBuffer[FieldRely]()
val curEdges = curData.get(i).get(0).toString
//3 Multiple edge loop analysis , Get to the destination
curEdges.split(",").foreach(curEdge => {
// Get the start and destination of the edge
val matcher = pattern.matcher(curEdge)
var startPoint = ""
val endNode = new FieldRely("")
// Assign two points
while (matcher.find()){
val curValue = matcher.group().replaceAll("\"", "")
// logger.info(s"not 1 curValue: $curValue")
if(direct) {
if ("".equals(startPoint)){
startPoint = curValue
}else{
endNode.name = curValue
endNode.children = new mutable.ArrayBuffer[FieldRely]()
nextParentNode.append(endNode)
}
}else {
if ("".equals(endNode.name)){
endNode.name = curValue
endNode.children = new mutable.ArrayBuffer[FieldRely]()
nextParentNode.append(endNode)
}else{
startPoint = curValue
}
}
}
// adopt startPoint Find the parent node , take endPoint Added to this parent node children in
var flag = true
// thus , One edge inserted successfully
for (curFieldRely <- parentNode if flag){
if (curFieldRely.name.equals(startPoint)){
curFieldRely.children.append(endNode)
flag = false
}
}
})
// Update parent
parentNode = nextParentNode
}
}
// logger.info(s"relyResult.toString: ${relyResult.toString}")
relyResult
}
Bean toString
class FieldRely {
@BeanProperty
var name: String = _ // Current node field name
@BeanProperty
var children: mutable.ArrayBuffer[FieldRely] = _ // All upstream or downstream subfield names corresponding to the current node
def this(name: String, children: mutable.ArrayBuffer[FieldRely]) = {
this()
this.name = name
this.children = children
}
def this(name: String) = {
this()
this.name = name
}
override def toString(): String = {
var resultString = ""
// Quote variables
val quote = "\""
// If empty, directly child Set to an empty array json
if (children.isEmpty){
resultString += s"{${quote}name${quote}: ${quote}$name${quote}, ${quote}children${quote}: []}"
}else {
//child There's data , Add an index and cycle through
var childrenStr = ""
// var index = 0
for (curRely <- children){
val curRelyStr = curRely.toString
childrenStr += curRelyStr + ", "
// index += 1
}
// Get rid of the excess ', '
if (childrenStr.length > 2){
childrenStr = childrenStr.substring(0, childrenStr.length - 2)
}
resultString += s"{${quote}name${quote}: ${quote}$name${quote}, ${quote}children${quote}: [$childrenStr]}"
}
resultString
}
}
result
In the query subgraph, the step size is close to 20 Under the circumstances , Basically, the data returned by the interface can be controlled in 200ms Inside ( Contains back-end complex processing logic ).
This article is participating in First Nebula Voting for essay solicitation , If you think this article is helpful to you, you can vote for me , To encourage ~
thank you (#.#)
I'm an intern in data development , I have been working in this position for about four months , Be responsible for developing the functions of the data platform .
Because the reading and writing performance of some data is low , So after the research , Choose to deploy a Nebula colony , Its technical system is also relatively mature , The community is also relatively perfect , Very friendly to the people who just came into contact with it . So it was put into use soon . In use , I have some ideas of my own , And some problems encountered and solutions , Here I would like to share my experience .
Communication graph database technology ? Join in Nebula Communication group please first Fill in your Nebula Business card ,Nebula The little assistant will pull you into the group ~~
边栏推荐
- 蚂蚁集团大规模图计算系统TuGraph通过国家级评测
- 《大学“电路分析基础”课程实验合集.实验四》丨线性电路特性的研究
- [salesforce] how to confirm your salesforce version?
- lseek 出错
- 爱可可AI前沿推介(7.2)
- [idea] recommend an idea translation plug-in: translation "suggestions collection"
- 华为云服务器安装mysqlb for mysqld.service failed because the control process exited with error code.See “sys
- SQL FOREIGN KEY
- (Wanzi essence knowledge summary) basic knowledge of shell script programming
- Xpt2046 four wire resistive touch screen
猜你喜欢

Review materials for the special topic of analog electronics with all essence: basic amplification circuit knowledge points
win10系统升级一段时间后,内存占用过高

Teach you how to build virtual machines locally and deploy microservices

数仓中的维度表与事实表

idea jar包冲突排查

idea 公共方法抽取快捷键

二叉树前,中,后序遍历

可视化技术在 Nebula Graph 中的应用

爱可可AI前沿推介(7.2)
如何實現十億級離線 CSV 導入 Nebula Graph
随机推荐
动态规划入门一,队列的bfs(70.121.279.200)
Huawei ECS installs mysqlb for mysqld service failed because the control process exited with error code. See “sys
Moveit 避障路径规划 demo
Idea jar package conflict troubleshooting
Fiddler实现手机抓包——入门
数字藏品系统开发(程序开发)丨数字藏品3D建模经济模式系统开发源码
/bin/ld: 找不到 -lgssapi_krb5
Fastjson list to jsonarray and jsonarray to list "suggested collections"
华为云服务器安装mysqlb for mysqld.service failed because the control process exited with error code.See “sys
Introduction to dynamic planning I, BFS of queue (70.121.279.200)
SQL修改语句
Group by的用法
Traversal before, during and after binary tree
2020.4.12 byte written test questions B DP D monotone stack
6090. Minimax games
Digital collection system development (program development) - Digital Collection 3D modeling economic model system development source code
Experiment collection of University Course "Fundamentals of circuit analysis". Experiment 5 - Research on equivalent circuit of linear active two terminal network
Boot 事务使用
[idea] recommend an idea translation plug-in: translation "suggestions collection"
Xpt2046 four wire resistive touch screen